
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I hired a woman for senior quality assurance two weeks ago. Impressive resume, great interview, but I was met with some pseudo-sexist puzzled looks in the dev team.
Meeting today. Boss: "Why is the database cluster not working properly?"
Team devs: "We've tried diagnosing the problem, but we can't really find it. It keeps being under high load."
New QA: "It might have something to do with the way you developers write queries".
She pulls up a bunch of code examples with dozens of joins and orderings on unindexed columns, explains that you shouldn't call queries from within looping constructs, that it's smart to limit the data with constraints and aggregations, hints at where to actually place indexes, how not to drag the whole DB to the frontend and process it in VueJS, etc...
New QA: "I've already put the tasks for refactoring the queries in Asana"
I'm grinning, because finally... finally I'm not alone in my crusade anymore.
Boss: "Yeah but that's just that code quality nonsense Bittersweet always keeps nagging about. Why is the database not working? Can't we just add more thingies to the cluster? That would be easier than rewriting the code, right?"
Dev team: "Yes... yes. We could try a few more of these aws rds db.m4.10xlarge thingies. That will solve it."
QA looks pissed off, stands up: "No. These queries... they touch the database in so many places, and so violently, that it has to go to therapy. That's why it's down. It just can't take the abuse anymore. You could add more little brothers and sisters to the equation, but damn that would be cruel right? Not to mention that therapy isn't exactly cheap!"
Dev team looks annoyed at me. My boss looks even more annoyed at me. "You hired this one?"
I keep grinning, and I nod.
"I might have offered her a permanent contract"45 -
Hey everyone,
First off, a Merry Christmas to everyone who celebrates, happy holidays to everyone, and happy almost-new-year!
Tim and I are very happy with the year devRant has had, and thinking back, there are a lot of 2017 highlights to recap. Here are just a few of the ones that come to mind (this list is not exhaustive and I'm definitley forgetting stuff!):
- We introduced the devRant supporter program (devRant++)! (https://devrant.com/rants/638594/...). Thank you so much to everyone who has embraced devRant++! This program has helped us significantly and it's made it possible for us to mantain our current infrustructure and not have to cut down on servers/sacrifice app performance and stability.
- We added avatar pets (https://devrant.com/rants/455860/...)
- We finally got the domain devrant.com thanks to @wiardvanrij (https://devrant.com/rants/938509/...)
- The first international devRant meetup (Dutch) with organized by @linuxxx and was a huge success (https://devrant.com/rants/937319/... + https://devrant.com/rants/935713/...)
- We reached 50,000 downloads on Android (https://devrant.com/rants/728421/...)
- We introduced notif tabs (https://devrant.com/rants/1037456/...), which make it easy to filter your in-app notifications by type
- @AlexDeLarge became the first devRant user to hit 50,000++ (https://devrant.com/rants/885432/...), and @linuxxx became the first to hit 75,000++
- We made an April Fools joke that got a lot of people mad at us and hopefully got some laughs too (https://devrant.com/rants/506740/...)
- We launched devDucks!! (https://devducks.com)
- We got rid of the drawer menu in our mobile apps and switched to a tab layout
- We added the ability to subscribe to any user's rants (https://devrant.com/rants/538170/...)
- Introduced the post type selector (https://devrant.com/rants/850978/...) (which will be used for filtering - more details below)
- Started a bug/feature tracker GitHub repo (https://github.com/devRant/devRant)
- We did our first ever live stream (https://youtube.com/watch/...)
- Added an awesome all-black theme (devRant++) (https://devrant.com/rants/850978/...)
- We created an "active discussions" screen within the app so you can easily find rants with booming discussions!
- Thanks to the suggestion of many community members, we added "scroll to bottom" functionality to rants with long comment threads to make those rants more usable
- We improved our app stability and set our personal record for uptime, and we also cut request times in half with some database cluster upgrades
- Awesome new community projects: https://devrant.com/projects (more will be added to the list soon, sorry for the delay!)
- A new landing page for web (https://devrant.com), that was the first phase of our web overhaul coming soon (see below)
Even after all of this stuff, Tim and I both know there is a ton of work to do going forward and we want to continue to make devRant as good as it can be. We rely on your feedback to make that happen and we encourage everyone to keep submitting and discussing ideas in the bug/feature tracker (https://github.com/devRant/devRant).
We only have a little bit of the roadmap right now, but here's some things 2018 will bring:
- A brand new devRant web app: we've heard the feedback loud and clear. This is our top priority right now, and we're happy to say the completely redesigned/overhauled devRant web experience is almost done and will be released in early 2018. We think everyone will really like it.
- Functionality to filter rants by type: this feature was always planned since we introduced notif types, and it will soon be implemented. The notif type filter will allow you to select the types of rants you want to see for any of the sorting methods.
- App stability and usability: we want to dedicate a little time to making sure we don't forget to fix some long-standing bugs with our iOS/Android apps. This includes UI issues, push notification problems on Android, any many other small but annoying problems. We know the stability and usability of devRant is very important to the community, so it's important for us to give it the attention it deserves.
- Improved profiles/avatars: we can't reveal a ton here yet, but we've got some pretty cool ideas that we think everyone will enjoy.
- Private messaging: we think a PM system can add a lot to the app and make it much more intuitive to reach out to people privately. However, Tim and I believe in only launching carefully developed features, so rest assured that a lot of thought will be going into the system to maximize privacy, provide settings that make it easy to turn off, and provide security features that make it very difficult for abuse to take place. We're also open to any ideas here, so just let us know what you might be thinking.
There will be many more additions, but those are just a few we have in mind right now.
We've had a great year, and we really can't thank every member of the devRant community enough. We've always gotten amazingly positive feedback from the community, and we really do appreciate it. One of the most awesome things is when some compliments the kindness of the devRant community itself, which we hear a lot. It really is such a welcoming community and we love seeing devs of all kind and geographic locations welcomed with open arms.
2018 will be an important year for devRant as we continue to grow and we will need to continue the momentum. We think the ideas we have right now and the ones that will come from community feedback going forward will allow us to make this a big year and continue to improve the devRant community.
Thanks everyone, and thanks for your amazing contributions to the devRant community!
Looking forward to 2018,
- David and Tim 45
45 -
Hey everyone!
devRant will be going down on Friday, July 7th around 10:30pm EDT so we can do some database maintenance and restructuring of our cluster. It hopefully won't be down for more than about 30 minutes or so, and during that time you should see our "down for maintenance" message.
If you usually use devRant while you're on the toilet (we know many do!), we apologize and suggest you try to schedule around this!
Please let me know if you have any questions and apologies for the inconvenience.43 -
rant? rant!
I work for a company that develops a variety of software solutions for companies of varying sizes. The company has three people in charge, and small teams that each worked on a certain project. 9 months ago I joined the company as a junior developer, and coincidentally, we also started working on our biggest project so far - an online platform for buying groceries from a variety of vendors/merchants and having them be delivered to your doorstep on the same day (hadn't been done to this scale in Estonia yet). One of the people from management joined the team working on that. The company that ordered this is coincidentally being run by one of the richest men in Estonia. The platform included both the actual website for customers to use, a logistics system for routing between the merchants, the warehouse, and the customers, as well as a bunch of mobile apps for the couriers, warehouse personnel, etc. It was built on Node.js with Hapi (for the backend stuff), Angular 2 (for all the UIs, including the apps which are run through a WebView wrapper), and PostgreSQL (for the database). The deadline for the MVP we (read: the management) gave them, but we finished it in about 7 months in a team of five.
The hours were insane, from 10 AM to 10 PM if lucky. When we weren't lucky (which was half of the time, if not more), we had to work until anywhere from 12 PM to 3 AM, sometimes even the whole night. The weekends weren't any better, for the majority of the time we had to put in even more extra hours on the weekends. Luckily, we were paid extra for them, but the salary was no way near fair (the majority of the team earned about 1000€/mo after taxes in a country where junior developers usually earn 1500€/month). Also because of the short deadline given to us, we skipped all the important parts like writing tests, doing CI, code reviews, feature branching/PR's, etc. I tried pushing the team and the management to at least write tests and make feature branches/PRs, but the management always told me that there wasn't enough time to coordinate and work on all that, that we'll do that after launching the MVP, etc. We basically just wrote features, tested them by hand, and pushed into the "test" branch which would later get tested and merged into master.
During development, one of the other juniors managed to write the worst kind of Angular code you could imagine - enormous amounts of duplication, no reusable components (every view contained the everything used in the view, so popups and other parts that should logically be reusable were in every view separately), fuck - even the HTML was broken (the most memorable for me were the "table > tr > div > td" ones, but that's barely scratching the surface). He left a few months into the project, and we had to build upon his shit, ever so slightly trying to fix the shit he produced. This could have definitely been avoided if we did code reviews.
A month after launching the MVP for internal testing, the guy working on the logistics system had burned out and left the company (he's earning more than twice the salary he got here, happy for him, he is a great coder and an even better team player). This could have been avoided if this project had been planned better, but I can't really blame them, since it was the first project they had at this scale (even though they had given longer deadlines for projects way smaller than this).
After we finished and launched the MVP, the second guy from management joined, because he saw we needed extra help. Again I tried to push us into investing the time to write tests for the system (because at this point we had created an unstable cluster fuck of a codebase), but again to no avail. The same "no time, just test it manually for now, we'll do that later when we have time" bullshit from management.
Now, a few weeks ago, the third guy from management joined. He saw what a disaster our whole project was. Him joining was simply a blessing from the skies. He started off by writing migrations using sequelize. I talked to him about writing tests and everything, and he actually listened. He told me that I'm gonna be the one writing them, and also talked to the rest of management about it. I was overjoyed. I could actually hear the bitterness in the voices of the rest of management when they told me how to write the tests, what to test, etc. But I didn't give a flying rat's ass, I was hapi.
I was told to start off by writing a smoke test for the whole client flow using Puppeteer. I got even happier, since I was finally able to again learn new things (this stopped at about 4 or 5 months into the project).
I'm using jest as the framework and started writing the tests in TypeScript. Later I found a library called jest-extended, but it didn't have type defs, so I decided to write them and, for the first time in my life, contribute to the open source community.18 -
--- GitHub 24-hour outage post mortem ---
As many of you will remember; Github fell over earlier this month and cracked its head on the counter top on the way down. For more or less a full 24 hours the repo-wrangling behemoth had inconsistent data being presented to users, slow response times and failing requests during common user actions such as reporting issues and questioning your career choice in code reviews.
It's been revealed in a post-mortem of the incident (link at the end of the article) that DB replication was the root cause of the chaos after a failing 100G network link was being replaced during routine maintenance. I don't pretend to be a rockstar-ninja-wizard DBA but after speaking with colleagues who went a shade whiter when the term "replication" was used - It's hard to predict where a design decision will bite back and leave you untanging the web of lies and misinformation reported by the databases for weeks if not months after everything's gone a tad sideways.
When the link was yanked out of the east coast DC undergoing maintenance - Github's "Orchestrator" software did exactly what it was meant to do; It hit the "ohshi" button and failed over to another DC that wasn't reporting any issues. The hitch in the master plan was that when connectivity came back up at the east coast DC, Orchestrator was unable to (un)fail-over back to the east coast DC due to each cluster containing data the other didn't have.
At this point it's reasonable to assume that pants were turning funny colours - Monitoring systems across the board started squealing, firing off messages to engineers demanding they rouse from the land of nod and snap back to reality, that was a bit more "on-fire" than usual. A quick call to Orchestrator's API returned a result set that only contained database servers from the west coast - none of the east coast servers had responded.
Come 11pm UTC (about 10 minutes after the initial pant re-colouring) engineers realised they were well and truly backed into a corner, the site was flipped into "Yellow" status and internal mechanisms for deployments were locked out. 5 minutes later an Incident Co-ordinator was dragged from their lair by the status change and almost immediately flipped the site into "Red" status, a move i can only hope was accompanied by all the lights going red and klaxons sounding.
Even more engineers were roused from their slumber to help with the recovery effort, By this point hair was turning grey in real time - The fail-over DB cluster had been processing user data for nearly 40 minutes, every second that passed made the inevitable untangling process exponentially more difficult. Not long after this Github made the call to pause webhooks and Github Pages builds in an attempt to prevent further data loss, causing disruption to those of us using Github as a way of kicking off our deployment processes (myself included, I had to SSH in and run a git pull myself like some kind of savage).
Glossing over several more "And then things were still broken" sections of the post mortem; Clever engineers with their heads screwed on the right way successfully executed what i can only imagine was a large, complex and risky plan to untangle the mess and restore functionality. Github was picked up off the kitchen floor and promptly placed in a comfy chair with a sweet tea to recover. The enormous backlog of webhooks and Pages builds was caught up with and everything was more or less back to normal.
It goes to show that even the best laid plan rarely survives first contact with the enemy, In this case a failing 100G network link somewhere inside an east coast data center.
Link to the post mortem: https://blog.github.com/2018-10-30-...6 -
Finish my Raspberry Pi Zero Cluster... complete with kubernetes, etc.
... I still don't know what I'm going to run on this. suggestions in the comments welcome. 27
27 -
Never have I been so furious whilst at work as yesterday, I am still super pissed about going back today but knowing it's only for another few weeks makes it baerable.
I have been the lead developer on a project for the last 3~ months and our CTO is the product owner. So every now and then he decides to just work on a feature he is interested in- fair enough I guess. But everything I have to go and clean up his horrendous code. Everything he writes is an absolute joke, it's like he is constantly in Hackathon mode "let's just copy and paste some code here, hardcoded shit there and forgot about separation of code- it all goes in 1 file".
So yesterday he added a application to the project and instead of reusing a shared data access layer he added an entirely new ORM, which is near identical to the existing ORM in use, for this one application.
Being anal about these things, the first thing I did was delete his shit and simply reference the shared library then refactor a little code to make it compatible.
WELL!! I certainly hit a nerve, he went crazy spamming messages on Slack demanding I revert as it broke ONE SINGLE QUERY that he hadn't checked in (he does 1 huge commit for 10 of everyone else's). I stuck to my principals and explained both ORM's are similar and that we only needed one, the second would cause a fragmented codebase for no benefit whatsoever.
The lead Dev was then forced to come and convince me to revert, again I refused and called out the shit quality of their code. The battle raged on via the public slack group and I could hear colleagues enjoying the heated debate, new users even started joining the group just to get in on mine and the cto's difference of opinion.
I even offered to fix his code for him if he were to commit it, obviously that was not taken well ;).
Once I finally got a luck at the cluster fuck of shit he had written it took me around 5 minutes to fix and I ever improved performance. Regardless he was having none of it. Still the demands to revert continued.
I left the office steaming after long discussions with the lead Dev caught in the middle.
Fortunately my day was salvages with a positive technical discussion that evening at a company with whome I had a job offer from.
I really hate burning bridges and have never left a company under bad terms but this dictator is making me look forward to breaking the news today I will be gone in 4 weeks.4 -
!rant
So last weekend I started collecting hardware for a small scale cluster at home to test scalability of my software. Making some decent progress.
Tomorrow I will replace the switch and this weekend I will set up storage so I can start my first application 20
20 -
Data scientist: we need to whitelist a pod to connect to a database
Me: Whitelist? We don't use whitelists on private databases
DS: It's the new data warehouse database
Me: is it on <X> VPC?
DS: I'm not sure what that means but its ip is <real world ipv4>
Me: Are you hosting a publicly accessible database with all our end users information?!
DS: ...
Me: There goes our SOC2 audit controls...
DS: how long until you can white list it?
Me: I won't be whitelisting it. You need to put it on a private VPC and peer with the cluster, you'll have to rebuild all the Terraform and redeploy
DS: We didn't use Terraform because it takes too long, just white list the pods IP.
Me: No. I'm contacting the CISO and CTO...21 -
So, some time ago, I was working for a complete puckered anus of a cosmetics company on their ecommerce product. Won't name names, but they're shitty and known for MLM. If you're clever, go you ;)
Anyways, over the course of years they brought in a competent firm to implement their service layer. I'd even worked with them in the past and it was designed to handle a frankly ridiculous-scale load. After they got the 1.0 released, the manager was replaced with some absolutely talentless, chauvinist cuntrag from a phone company that is well known for having 99% indian devs and not being able to heard now. He of course brought in his number two, worked on making life miserable and running everyone on the team off; inside of a year the entire team was ex-said-phone-company.
Watching the decay of this product was a sheer joy. They cratered the database numerous times during peak-load periods, caused $20M in redis-cluster cost overrun, ended up submitting hundreds of erroneous and duplicate orders, and mailed almost $40K worth of product to a random guy in outer mongolia who is , we can only hope, now enjoying his new life as an instagram influencer. They even terminally broke the automatic metadata, and hired THIRTY PEOPLE to sit there and do nothing but edit swagger. And it was still both wrong and unusable.
Over the course of two years, I ended up rewriting large portions of their infra surrounding the centralized service cancer to do things like, "implement security," as well as cut memory usage and runtimes down by quite literally 100x in the worst cases.
It was during this time I discovered a rather critical flaw. This is the story of what, how and how can you fucking even be that stupid. The issue relates to users and their reports and their ability to order.
I first found this issue looking at some erroneous data for a low value order and went, "There's no fucking way, they're fucking stupid, but this is borderline criminal." It was easy to miss, but someone in a top down reporting chain had submitted an order for someone else in a different org. Shouldn't be possible, but here was that order staring me in the face.
So I set to work seeing if we'd pwned ourselves as an org. I spend a few hours poring over logs from the log service and dynatrace trying to recreate what happened. I first tested to see if I could get a user, not something that was usually done because auth identity was pervasive. I discover the users are INCREMENTAL int values they used for ids in the database when requesting from the API, so naturally I have a full list of users and their title and relative position, as well as reports and descendants in about 10 minutes.
I try the happy path of setting values for random, known payment methods and org structures similar to the impossible order, and submitting as a normal user, no dice. Several more tries and I'm confident this isn't the vector.
Exhausting that option, I look at the protocol for a type of order in the system that allowed higher level people to impersonate people below them and use their own payment info for descendant report orders. I see that all of the data for this transaction is stored in a cookie. Few tests later, I discover the UI has no forgery checks, hashing, etc, and just fucking trusts whatever is present in that cookie.
An hour of tweaking later, I'm impersonating a director as a bottom rung employee. Score. So I fill a cart with a bunch of test items and proceed to checkout. There, in all its glory are the director's payment options. I select one and am presented with:
"please reenter card number to validate."
Bupkiss. Dead end.
OR SO YOU WOULD THINK.
One unimportant detail I noticed during my log investigations that the shit slinging GUI monkeys who butchered the system didn't was, on a failed attempt to submit payment in the DB, the logs were filled with messages like:
"Failed to submit order for [userid] with credit card id [id], number [FULL CREDIT CARD NUMBER]"
One submit click later and the user's credit card number drops into lnav like a gatcha prize. I dutifully rerun the checkout and got an email send notification in the logs for successful transfer to fulfillment. Order placed. Some continued experimentation later and the truth is evident:
With an authenticated user or any privilege, you could place any order, as anyone, using anyon's payment methods and have it sent anywhere.
So naturally, I pack the crucifixion-worthy body of evidence up and walk it into the IT director's office. I show him the defect, and he turns sheet fucking white. He knows there's no recovering from it, and there's no way his shitstick service team can handle fixing it. Somewhere in his tiny little grinchly manager's heart he knew they'd caused it, and he was to blame for being a shit captain to the SS Failboat. He replies quietly, "You will never speak of this to anyone, fix this discretely." Straight up hitler's bunker meme rage.13 -
A Developer is desperate: his java application servers are unresponsive, thousand of dead zombie threads are sucking all cpus, memory is leaking everywhere, garbage collector has gone crazy, the cluster sessions are fucked....
The Developer goes to the closest bridge, ties a stone to his neck and gets ready to jump.
Suddenly a bearded old man with a fiery look runs toward him, yelling:
- stop stop!!!! Your application is not scaling and misconfigured, your servers are melting, cpu usage is not sustainable anymore, but don't despair
The Developer, puzzled, looks at him:
-I've never seen you...how do you know...
- Hey, man, I'm the Devil. I know everything. All your problems are solved. I'll give you magic functions. They are called Lambda.
You'll never have to worry about your servers, scalability, security, configuration and shit.
The Developer seems astonished but relieved:
- Ok, sounds great! let's try it - suddenly suspicion creeps in - hmmmm but you are the Devil....so...you want something back, don't you?
(the Devil nods lightly with a diabolic smile)
- ...and...you want my soul, I guess...
- your soul??? come on!!! - the Devil burst in a laugh - we are in 2019. I don't care about your soul. I want your ass.
- What!???!!!?
- yes, I want to fuck your ass
The Developer, evaluates quickly the situation.
Few moments of pain or slight discomfort (?) in exchange for magic lambda. It could be worth. He accepts.
After a while of rough anal fucking, the devil asks
- Hey, how old are you anyway?
- 45, why?
- Oh jeeez...45!!!??? and you still believe in the devil?5 -
We are moving to kubernetes.
Nothing much has changed except we now get to say
it works on my cluster.
instead of
it work on my machine.1 -
Reasons I hate the US
1. It's fucking 2 in the morning there and folks are checking their Slack when they wake up for pee breaks or done after their sex sessions.
Nearly 90% of the team is on and off checking Slack.
2. Culture fucks have only 10 holidays and hence they align rest of the world to their calendar and only give 10 holidays. India, Europe, and entire world can easily get 15 holidays per year outside their leave quota.
What a cluster fuck of a country it is.23 -
a dude just DROPPED the whole Fu**ing mongodb cluster. like Right Now.
multiple databases, expanding multiple projects.
fortunately in dev. but dunno how much data is recoverable.13 -
Some days I just want to shoot myself.
I get why... someone might do this, but sweet mother of god! 17
17 -
CEO - So... We'll have a new side project, it's a small thing, I spoke with a guy, he needs just a small thing...
Me - Ok....... So, what do you need me for?
CEO - Not much, this guy started a project but wants your help on a small part, and you already did something similar for us, so it should be fast, just copy and paste and change a little bit. You probably know better than me.
Me - *Sigh* ... So `friend`, what do you need from me?
Friend - So, I made a crawler that is storing some information on a local file, I just need to add multiprocessing and multithreading, a producer-consumer system with a queue so I can automatically add new links every now and then, a failback system, so when a process doesn't finish, it should be re-queued and crawled later, store all the information on a database cluster (that is not set up), [......]
Me - And when is this supposed to be up and running?
Friend - Your CEO told me you could do this by the weekend. Can we finish this by Friday?
Me - *facepalm* FML13 -
Inception.
Today I needed to check something in a remote server: this was the easiest way:
1: teamviewer to my home pc from university
2: started a vm on that machine with vpn connection to my work office
3: rdp to a windows server vm
4: ssh to a vm on our hosting cluster
5: from there, ssh to the server that I needed access to7 -
Yep. So the dev teams boss says it's fine to run a production environment on a single Windows instance with the db on that same instance, which they already totally lost once from a reboot after an auto update before I came along tasked with fixing the cluster fuck they created.
This from a man who somehow runs a dev team while using gmail via the web because he can't use an email client, uses email to track tasks but can't because they get lost amongst his 3000+ unread emails, has a screen dirtier than a hookers vag on half priced Tuesday, and got a new laptop but had to get his daughter to set it up and transfer his data because he couldn't.
But ok... you have a degree, You must know what you're doing.
It's ok though, I'll keep covering your incompetent ass while you keep raping the company because no one listens.
Peoples ignorance and arrogance astounds me.4 -
I am running a small - but growing - ceph-cluster at work. Since it is fun and our storage demand is growing each day.
Today, it was time to bring another node online and add another 12TB to the cluster.
Installation of the OS went fine, network settings fine, drives looks fine.
Now, time to add it into the cluster.... BAM
Every Dell machine in the Cluster - Dead.
The two HP-machines is online and running. But the Dell-machines just died.
WAT!?19 -
Went in to the therapist today. Their impression is I'm likely okay. Wait until I show them the cluster fuck that is Java Enterprise. 🙃11
-
We are building this big-data engine for a client's product for which we were using a cluster on GCP and they were billed ~1100$ for the last month's usage.
The CTO - the CHIEFFUCKING TECHNOLOGY OFFICER told us to hook up 5-6 laptops in our server room and create our own cluster because they cannot afford so much bill.6 -
"Let's create a docker-swarm cluster thingy for this application with horizontal scaling to learn docker and run this application better!"
This stuff is so overwhelming and I don't understand half of how to possibly set this up 😅32 -
Manager: "Can we get an accurate report on how many containers we have on the Kubernetes cluster?"
Me: "Well not really since Kubernetes is designed to be dynamic and agile with the number of resources and containers being created and deleted being subject to change at a moment's notice."
Manager: "I want numbers"
Me: "Okay well if we look at a simple moving average over time, we can see how the number of containers changes and then grab a rough answer from that"
Manager: "These numbers look a little round, are you sure these are exact?"
I'm going to throw myself into a pile of used heroin needles and hope i get stuck with whatever the hell this guy has to somehow be a manager while also being this retarded.13 -
Today we presented our project in Embedded Systems. We made our so called "Blinkdiagnosegerät" (blink diagnosis device) which is used to get error codes from older verhicles which use the check enginge light to output the error. (for reference: http://up.picr.de/7461761jwd.jpg ) This was common for vehicles without OBD.
We made our own PCB, made a small database for 2 vehicles and used a Suzuki Samurai instrument cluster for the presentation (hooked up to an Arduino UNO and a relay for emulating some Error Codes)
Got an 1.0 (A) for the project. Feel proud for the first project done in C++ and making our own PCB. So no rant, just a good day after all the stress in the last weeks doing all assignements and presentations.
Next week we hopefully finish our inverse pendulum in Simulink and then the exams are close. :D 15
15 -
> Monitoring: Load Average of 57!! ALERT!!!!
> me: What? That's not possible?
> *Monitoring froze 14 hours ago*
> *sshs into server*
> *see attached image*
The issue was ~1200 df processes that were issued by our monitoring system and all of them didn't finish because the external cluster we mounted onto that server died a few minutes before that. Just re-mounting the cluster fixed it but still a funny sight! 24
24 -
Got laid off last week with the rest of the dev team, except one full stack Laravel dev. Investors money drying up, and the clowns can't figure out how to sell what we have.
I was all of devops and cloud infra. Had a nice k8s cluster, all terraform and gitops. The only dev left is being asked to migrate all of it to Laravel forge. 7 ML microservices, monolith web app, hashicorp vault, perfect, mlflow, kubecost, rancher, some other random services.
The genius asked the dev to move everything to a single aws account and deploy publicly with Laravel forge... While adding more features. The VP of engineering just finished his 3 year plan for the 5 months of runway they have left.
I already have another job offer for 50k more a year. I'm out of here!13 -
Personally the coolest was the program I built for my fathers use on his job.
It was my first to be used commercially in the real.
That was a very big thing, I was 17 at the time an used turbo pascal 5.5 and he used it to compute how well all machinery was doing, they rented out diggers and other construction equipment to construction sites and manually compute this with a calculator took up to three days. (This was 1987 so there was not very many ready made programs for business, you often had to build your own)
With this program he had it done in around 30 minutes.
The next best was recently when I got my raft distributed consensus cluster server working. Its a little bit like zookeeper.
Building that purely from the research paper was rewarding but a bit of a challenge.3 -
So I'm sitting on the swings, minding my own business, seing how best I could destroy this cluster of servers, when suddenly I notice SOMEONE IS COMING FOR MY COFFEE
"hi neighbour! What you've got there" 4
4 -
Finally got ceph up and running, so far it does look really great!
At the moment we have 45 TB in the cluster, but we are able to expand it extremely easy.
Two servers with 256 GB RAM and 24 cores, three more with 32 GB and 12 cores.
Dedicated gigabit WAN connection.
The project is going forward strong, I'll let you know when it is time for beta testing.7 -
Between containers, cluster managers and virtual machines we've lost track of where our code even is.4
-
IT is so violent and disturbing when it comes to technical terms in relation to clusters:
- master / slave
- master / master / witness (crime scene?)
- splitbrain (how does that look in reality?)
- stonith (shoot the other node in the head)
- deadtime (no heartbeat)
- slicing (wtf?)
- shard (do they kill with that?)
- active / passive (sex scene?)
- single point of failure (at least they know who is to blame)
- share nothing / shared all (dictators vs communism)
😯6 -
I once found a MongoDB cluster open to the internet with no authentication with nearly a terabyte of data that backed a CRM service whose customers included Microsoft and Adobe to name a few.7
-
OMFG! Who’s bright fucking horrible stupid ass idea was it to mix Ajax with php (php deciding the ajax paths) with random js outputting HTML inside random fucking static divs found no where near the logical route of content.
Trying to add a simple fucking status to a gigantic cluster fuck of a legacy project is just FUCK.
If I could I would burn this bitch to the ground and start again I would, But no, it’s needed.
Someone kill me before I break the shit out of this thing, I would take a wordpress project right now instead. -
I received a job offer as web-app developer and, in order to access the interview, I had to do an online QI test.
I login in the website and I see an ugly cluster of links, missing informations, errors at receiving the data I just inserted, a lot of bugs, broken links, images not availables, blank pages and so on.
I'm not sure I want to work there anymore6 -
So you want full stack engineers to: design, do UX, create front end, build backend and deploy it in your mono repo stupid manual deployment "kubernetes cluster", add monitoring alerting manually, review others PR, QA our own apps and features, manually sync to Production, use VPN otherwise we cannot connect to anything, 2factor auth, do SRE, architecture diagrams, demo, run agile ceremonies, and learn a legacy coding language which was never mentioned in the job description. Did I miss anything?7
-
So we have an API that my team is supposed send messages to in a fire and forget kind of style.
We are dependent on it. If it fails there is some annoying manual labor involved to clean that mess up. (If it even can be cleaned up, as sometimes it is also time-sensitive.)
Yet once in a while, that endpoint just crashes by letting the request vanish. No response, no error, nothing, it is just gone.
Digging through the log files of that API nothing pops up. Yet then I realize the size of the log files. About ~30GB on good old plain text log files.
It turns out that that API has taken the LOG EVERYTHING approach so much too heart that it logs to the point of its own death.
Is circular logging such a bleeding edge technology? It's not like there are external solutions for it like loggly or kibana. But oh, one might have to pay for them. Just dump it to the disk :/
This is again a combination of developers thinking "I don't need to care about space! It's cheap!" and managers thinking "100 GB should be enough for that server cluster. Let's restrict its HDD to 100GB, save some money!"
And then, here I stand trying to keep my sanity :/1 -
We have a 15-machine cluster that went down last night because one machine in the cluster went down. Apparently having a cluster for redundancy is just a nice idea and doesnt actually work in practice.
Also I shouldnt have to go to a vendor's forums to find out the bug that is causing my cluster to go down is fixed in a future version. It should be in the goddamn patch notes!!! -
Should’ve posted this after it happened, but it requires a bit of background anyway.
There’s this guy that oversees our OpenStack environment. My team often make jokes and groan about him in private because he’s so overbearing. A few months back, he had to take us to our data center to show us our new racks, and he kept saying stupid stuff like “you break this and it costs me $30,000” as if he owns everything. He’s just... one of THOSE people. Always speaks in such a condescending way. We make jokes that he is our “best friend”.
Our company is shifting most of our products to the cloud in response to the coronavirus (trying to make it an opportunity for “innovation”). This has involved some structural and responsibility changes in our department, and long story short, I’m now heading the OpenStack environment alongside other projects.
This means going through grueling 1-on-1 meetings with our “best friend”. It’s not too bad, I can be pretty patient with people, so I didn’t mind too much at first. Then a few things happened.
1. He sent a shared folder that he owned containing info related to the environments. Several documents were outdated and incomplete, so I downloaded them, corrected them, and then uploaded the documents to my teams file share, as I was supposed to since we now own the projects.
2. Several files were missing, and when I asked about them, he said “Oh, did you refresh the browser?”. I told him no, that I downloaded them locally and republished them to my teams server, because he was supposed to hand everything off to us at once. He says “Well, silly, how are you going to get updates if you’re looking at them locally?” and kind of chuckles at me like I’m stupid.
3. He insists on training me how to remote into one of the servers to check on cluster space, which in itself is fine. I understand others wanting to make sure things will be done right by the people who come after them. But he tells me to download SuperPutty. I tell him, “oh no, that’s alright. I don’t need putty”. He says “oh cool, what tool do you use for ssh?”. I answer him “Just Git. If I want to I can use a CentOs bash terminal too, because we have WSL installed”. He responds “You can’t ssh through Git”.
I was actually a little shocked. I didn’t know if he was serious or not so I was silent for a few seconds before hesitantly saying “yes you can”. He says “this is news to me” and I so I tell him “every single one of our build jobs fetches code from Git with ssh” and he seemed genuinely shocked and surprised by that.... so then it occurs to me to show him that you can ssh in Powershell and that REALLY blew his mind. He would not shut up about it for several minutes. I was amused until it just got annoying.
Needless to say, my team had been previously teasing me about having to work with him, so they found it hilarious when I told them afterwards.8 -
Once upon a time, one or two jobs ago, a really awesome engineer specced out a distributed search application in response to a business need. This company was managed pretty oldschool and required a ton of paperwork and approvals.
The engineer spent many weeks running tests and optimizing the hell out of this app cluster. It flew, and he had the data to prove it could handle production workloads (think hundreds of terabytes of data being processed every single day)
Part of the way he achieved this was having RAID0 on all of the servers to maximize I/O throughput. He didn't care much about data loss, since the application itself was fault tolerant on a much more granular level.
Management, hearing about this, absolutely flipped their shit and demanded RAID6 instead. This despite the conclusive data that the engineer had that proved RAID6 couldn't keep up.
He more or less got told to STFU.
Even this despite the fact that a RAID restripe would actually take many times longer than rebuilding the failed node from scratch (a process that took about 30 minutes by hand, and could probably be automated to be done in less than five), causing a longer exposure to actual data loss throughout the length of the days-long array rebuild time.
The ill-thought-out requirement added about 50% to the cost of the project (*many* more hard drives now required), beyond the original budget, and the subsequent bureaucratic wrangling resulted in a late product launch.
6 months or so later, after real customers were using this product, the app was buckling under around half of its expected workload. A friend of the engineer suggested to management to try RAID0. Sure enough, that resolved the I/O bottleneck.
This rage-inducing story has a happy ending, though! Said engineer left the company not long after this incident, citing it as a reason for his departure. He was immediately hired by another company, making integer multiples of his prior salary.
The product the company botched the launch of by ignoring his spec? It died a few months later. Maybe the poor customer experience was to blame? Maybe the late launch? Maybe it was another reason entirely.
Either way, millions of dollars of hardware now sat fallow. This was a black eye on the company all the way up to the C-level.
tl;dr: Listen to your engineers. You hired them for their expertise.4 -
"four million dollars"
TL;DR. Seriously, It's way too long.
That's all the management really cares about, apparently.
It all started when there were heated, war faced discussions with a major client this weekend (coonts, I tell ye) and it was decided that a stupid, out of context customisation POC had that was hacked together by the "customisation and delivery " (they know to do neither) team needed to be merged with the product (a hot, lumpy cluster fuck, made in a technology so old that even the great creators (namely Goo-fucking-gle) decided that it was their worst mistake ever and stopped supporting it (or even considering its existence at this point)).
Today morning, I my manager calls me and announces that I'm the lucky fuck who gets to do this shit.
Now being the defacto got admin to our team (after the last lead left, I was the only one with adequate experience), I suggested to my manager "boss, here's a light bulb. Why don't we just create a new branch for the fuckers and ask them to merge their shite with our shite and then all we'll have to do it build the mixed up shite to create an even smellier pile of shite and feed it to the customer".
"I agree with you mahaDev (when haven't you said that, coont), but the thing is <insert random manger talk here> so we're the ones who'll have to do it (again, when haven't you said that, coont)"
I said fine. Send me the details. He forwarded me a mail, which contained context not amounting to half a syllable of the word "context". I pinged the guy who developed the hack. He gave me nothing but a link to his code repo. I said give me details. He simply said "I've sent the repo details, what else do you require?"
1st motherfucker.
Dafuq? Dude, gimme some spice. Dafuq you done? Dafuq libraries you used? Dafuq APIs you used? Where Dafuq did you get this old ass checkout on which you've made these changes? AND DAFUQ IS THIS TOOL SUPPOSED TO DO AND HOW DOES IT AFFECT MY PRODUCT?
Anyway, since I didn't get a lot of info, I set about trying to just merge the code blindly and fix all conflicts, assuming that no new libraries/APIs have been used and the code is compatible with our master code base.
Enter delivery head. 2nd motherfucker.
This coont neither has technical knowledge nor the common sense to ask someone who knows his shit to help out with the technical stuff.
I find out that this was the half assed moron who agreed to a 3 day timeline (and our build takes around 13 hours to complete, end to end). Because fuck testing. They validated the their tool, we've tested our product. There's no way it can fail when we make a hybrid cocktail that will make the elephants foot look like a frikkin mojito!
Anywho, he comes by every half-mother fucking-hour and asks whether the build has been triggered.
Bitch. I have no clue what is going on and your people apparently don't have the time to give a fuck. How in the world do you expect me to finish this in 5 minutes?
Anyway, after I compile for the first time after merging, I see enough compilations to last a frikkin life time. I kid you not, I scrolled for a complete minute before reaching the last one.
Again, my assumption was that there are no library or dependency changes, neither did I know the fact that the dude implemented using completely different libraries altogether in some places.
Now I know it's my fault for not checking myself, but I was already having a bad day.
I then proceeded to have a little tantrum. In the middle of the floor, because I DIDN'T HAVE A CLUE WHAT CHANGES WERE MADE AND NOBODY CARED ENOUGH TO GIVE A FUCKING FUCK ABOUT THE DAMN FUCK.
Lo and behold, everyone's at my service now. I get all things clarified, takes around an hour and a half of my time (could have been done in 20 minutes had someone given me the complete info) to find out all I need to know and proceed to remove all compilation problems.
Hurrah. In my frustration, I forgot to push some changes, and because of some weird shit in our build framework, the build failed in Jenkins. Multiple times. Even though the exact same code was working on my local setup (cliche, I know).
In any case, it was sometime during sorting out this mess did I come to know that the reason why the 2nd motherfucker accepted the 3 day deadline was because the total bill being slapped to the customer is four fucking million USD.
Greed. Wow. The fucker just sacrificed everyone's day and night (his team and the next) for 4mil. And my manager and director agreed. Four fucking million dollars. I don't get to see a penny of it, I work for peanut shells, for 15 hours, you'll get bonuses and commissions, the fucking junior Dev earns more than me, but my manager says I'm the MVP of the team, all I get is a thanks and a bad rating for this hike cycle.
4mil usd, I learnt today, is enough to make you lick the smelly, hairy balls of a Neanderthal even though the money isn't truly yours.4 -
5 of us working for a larger team were tasked with doing some R&D, we blew everyone away and were given funding to start a new team and hire people to make the project come to life.
One of the high level sales / product managers we were reporting to, secretly had another team work on a similar idea because he needed it quicker (i.e. no time for research, just build it).
After forming new team, we were asked to work on his project instead because it was further along. 4 months later, big knob comes to a meeting and basically says "You know what, this doesn't look like we have enough features, we need more, but I don't know what".
Project blew up 2 months later, head of the unit kicked up a shit storm saying how badly everything was planned and canned everything. Now one of our clients is building nearly the same thing we were originally working on, the team no longer exists and i'm back on the R&D team.
Don't get me wrong, I LOVE the R&D team, actually didn't want to leave in the first place but was told I had to. But the sheer anger and frustration to see that walking cluster fuck strutting around like his shit doesn't stink, derailing entire teams, meanwhile we can't hire new staff due to lack of funding.
Heres an idea, fire the fucktards bleeding us dry ... then we'll have lots of funding. -
Was forced to do some work on Windows this week (CAD tools that runs only on Windows). I spent a few days just setting up the tools. There were quite a few things I realized I forgot about Windows (as compared to Linux).
1) Installation times are down right horrific. What exactly are the installer doing for 10 minutes?
2) .NET is a cluster fuck. Not even Microsofts repair tool can fix it, but rather just hangs. I ended up using another tool to nuke it and reinstall.
3) Windows binary installs are insanely huge, thus, takes forever to download.
4) The registry is a pointless database that must have been written in hell with the single intent of destroying users will to live. The sole existence of the registry is another proof that completely incompetent engineers designed Windows.
5) Rebooting is the only way to solve many problems. This is another sure sign of a fundamentally fucked up OS design.
6) What the heck is wrong with the GUIs designers? The control panel must be the worst design ever. There are so many levels to get to a particular setting I'm getting dizzy. Nothing gets better by the illogical organisation.
7) Windows networking. A perversion of the tcp/ip stack that makes it virtually impossible to understand a damn thing about the current network configuration. There are at least 3 different places that effects the settings.
8) Windows command prompt. Why did they even bother to leave it in? The interpreter is as intelligent as retarded donut. You can't do anything with it, except typing "exit" and Google for another solution.
8) Updates. Why does it takes hundreds of updates per month to keep that thing safe?
9) Despite all updates that is flying out of Redmond like confetti, it is still necessary to install antivirus to keep the damn thing safe. That cost extra money, and further cost you by degrading performance of your hardware.
10) Window performance. Software runs like it was swimming in molasses. The final stab in the back on your hardware investment, and pretty much sends performance on your hardware back a few hundred bucks more.
11) Closed source is evil. If something crash consistently, you might find a forum that address the issues you have. Otherwise you're out of luck. On the other hand, it might be for the better. I imagine reading the code for Windows can lead to severe depression.
I'm lucky to be a Linux dev, and should probably not complain too much... But really, Windows, go get yourself hit by a truck and die. I won't miss you.14 -
REDIS: Great for cloud, will fuck up your local disk if too many write operations per second.
DynamoDB: WTF 10Mb should not be "too large for a single record"!!
SPARK: NEVER CONNECT IT TO A DATABASE! Wasted A LOT of cluster time. Also, can you be LESS specific on exactly what are the bugs in my code? 'cause I don't think it's possible.
NPM: can't install a package for shit. tried it waaaay to many times.
Makefiles: Just fuck you.
WSL1: breaks more often than a glass hammer.
Python >= 3.6: FUCK ENCODINGS!!
Jupyter: STOP MESSING UP WHILE SAVING!
Living is to collet bugs, it seems.4 -
I had spent the last year working on a online store power by woocommerce with over 100k products from various suppliers. This online store utilized a custom API that would take the various formats that suppliers offer their inventory in and made them consistent. Now everything was going swimmingly initially, but then I began adding more and more products using a plug-in called WP all import. I reached around 100k products and the site would take up to an entire minute to load sometimes timing out. I got desperate so I installed several caching plugins, but to no avail this did not help me. The site was originally only supposed to take three to four months but ended up taking an entire year. Then, just yesterday I found out what went wrong and why this woocommerce website with all of these optimizations was still taking anywhere from 60 to 90 seconds to load, or just timing out entirely. I had initially thought that I needed a beefier server so I moved it to a high CPU digitalocean VM. While this did help a little bit, the site was still very slow and now I had very high CPU usage RAM usage and high disk IO. I was seriously stumped the Apache process was using a high amount of CPU and IO along with MYSQL as well. It wasn't until I started digging deeper into the database that I actually found out what the issue was. As I was loading the site I would run 'show process list' in the SQL terminal, I began to notice a very significant load time for one of the tables, so I went to go and check it out. What I did was I ran a select all query on that particular table just to see how full it was and SQL returned a error saying that I had exceeded the maximum packet size. So I was like okay what the fuck...
So I exited my SQL and re-entered it this time with a higher packet size. I ran a query that would count how many rows were in this particular table and the number came out to being in the millions. I was surprised, and what's worse is that this table belong to a plugin that I had attempted to use early in the development process to cache the site. The plugin was deactivated but apparently it had left PHP files within the wp content directory outside of the actual plugin directory, so it's still executing scripts even though the plugin itself was disabled. Basically every time I would change anything on the site, it would recache the whole thing, and it didn't delete any old records. So 100k+ products caching on saves with no garbage collection... You do the math, it's gonna be a heavy ass database. Not only that but it was serialized data, so when it did pull this metric shit ton of spaghetti from the database, PHP then had to deserialize it. Hence the high ass CPU load. I had caching enabled on the MySQL end of things so that ate the ram. I was really desperate to get this thing running.
Honest to God the main reason why this website took so long was because the load times made it miserable to work on. I just thought that the hardware that I had the site on was inadequate. I had initially started the development on a small Linux VM which apparently wasn't enough, which is why I moved it to digitalocean which also seemed to not be enough, so from there I moved to a dedicated server which still didn't seem to be enough. I was probably a few more 60-second wait times or timeouts from recommending a server cluster to my client who I know would not be willing to purchase it. The client who I promised this site to have completed in 3 months and has waited a year. Seriously, I would tell people the struggles that I would go through with this particular site and they would just tell me to just drop the site; just take the money, just take the loss. I refused to, this was really the only thing that was kicking my ass. I present myself as this high-and-mighty developer like I'm just really good at what I do but then I have this WordPress site that's just beating the shit out of me for a year. It was a very big learning experience and it was also very humbling as well, it made me realize that I really don't know as much as I think I might. It was evidence that there is still so much more to learn out there, I did learn a lot from that experience especially about optimizing websites the different types of methods to do that particular lonely on the server side and I'll be able to utilize this knowledge in the future.
I guess the moral of the story is, never really give up. Ultimately things might get so bad that you're running on hopes and dreams. Those experiences are generally the most humbling. Now I can finally present the site that I am basically a year late on to the client who will be so happy that I did not give up on the project entirely. I'll have experienced this feeling of pure euphoria, and help the small business significantly grow their revenue. Helping others is very fulfilling for me, even at my own expense.
Anyways, gonna stop ranting. Running out of characters. If you're still here... Ty for reading :')7 -
I do like Windows, it is a quite good OS nowadays, but for FUCK SAKE, what does it take to fix that CLUSTER FUCK that you call search? You don't have enough people MS or what? Just show me the BLOODY ITEMS that actually contain the words that I typed in!!! While you are at it WOULD YOU MIND LEAVING ME THE FUCK ALONE WITH THE FUCKING WEB RESULTS???9
-
So I was wondering, what is you guys' 'goal' in the long run? What do you really want to be able to do or what do you really want to achieve in 5 to 10 years? Are you working primarily for an income or are there more prominent reasons for doing what you do?
I'm in my last years of university and have a job at a software development company, not because I need the money but because of all the amazing technologies I come in touch with and the amazing things I learn, mostly about servers and devops tools.
I currently have 2 goals in mind: Creating an .io game together with a frontend developer and setting up a kubernetes cluster and using it. I personally consider kubernetes an end-game thing when it comes to running apps and am experimenting with it on three servers that I got from school.
So I was wondering, what ahout you? 😀27 -
This begs for a rant... [too bad I can't post actual screenshots :/ ]
Me: He k8s team! We're having trouble with our k8s cluster. After scaling up and running h/c and Sanity tests environment was confirmed as Healthy and Stable. But once we'd started our load tests k8s cluster went out for a walk: most of the replicas got stoped and restarted and I cannot find in events' log WHY that happened. Could you please have a look?
k8s team [india]: Hello, thank you for reaching out to k8s support. We will check and let you know.
Me: Oh, you're welcome! I'll be just sitting here quietly and eagerly waiting for your reply. TIA! :slightly_smiling_face:
<5 minutes later>
k8s team India: Hi. Could you give me a list of replicas that were failing?
Me: I gave you a Grafana link with a timeframe filter. Look there -- almost all apps show instability at k8s layer. For instance APP_1 and APP_2 were OK. But APP_3, APP_4 and APP_5 were crashing all over the place
k8s team India: ok I will check.
<My shift has ended. k8s team works in different timezone. I've opened up Slack this morning>
k8s team India: HI. APP_1 and APP_2 are fine. I don't even see any errors from logs, no restarts. All response codes are 200.
Me: 🤦♂️ .... Man, isn't that what I've said? ... 🤦♂️5 -
EoS1: This is the continuation of my previous rant, "The Ballad of The Six Witchers and The Undocumented Java Tool". Catch the first part here: https://devrant.com/rants/5009817/...
The Undocumented Java Tool, created by Those Who Came Before to fight the great battles of the past, is a swift beast. It reaches systems unknown and impacts many processes, unbeknownst even to said processes' masters. All from within it's lair, a foggy Windows Server swamp of moldy data streams and boggy flows.
One of The Six Witchers, the Wild One, scouted ahead to map the input and output data streams of the Unmapped Data Swamp. Accompanied only by his animal familiars, NetCat and WireShark.
Two others, bold and adventurous, raised their decompiling blades against the Undocumented Java Tool beast itself, to uncover it's data processing secrets.
Another of the witchers, of dark complexion and smooth speak, followed the data upstream to find where the fuck the limited excel sheets that feeds The Beast comes from, since it's handlers only know that "every other day a new one appears on this shared active directory location". WTF do people often have NPC-levels of unawareness about their own fucking jobs?!?!
The other witchers left to tend to the Burn-Rate Bonfire, for The Sprint is dark and full of terrors, and some bigwigs always manage to shoehorn their whims/unrelated stories into a otherwise lean sprint.
At the dawn of the new year, the witchers reconvened. "The Beast breathes a currency conversion API" - said The Wild One - "And it's claws and fangs strike mostly at two independent JIRA clusters, sometimes upserting issues. It uses a company-deprecated API to send emails. We're in deep shit."
"I've found The Source of Fucking Excel Sheets" - said the smooth witcher - "It is The Temple of Cash-Flow, where the priests weave the Tapestry of Transactions. Our Fucking Excel Sheets are but a snapshot of the latest updates on the balance of some billing accounts. I spoke with one of the priestesses, and she told me that The Oracle (DB) would be able to provide us with The Data directly, if we were to learn the way of the ODBC and the Query"
"We stroke at the beast" - said the bold and adventurous witchers, now deserving of the bragging rights to be called The Butchers of Jarfile - "It is actually fewer than twenty classes and modules. Most are API-drivers. And less than 40% of the code is ever even fucking used! We found fucking JIRA API tokens and URIs hard-coded. And it is all synchronous and monolithic - no wonder it takes almost 20 hours to run a single fucking excel sheet".
Together, the witchers figured out that each new billing account were morphed by The Beast into a new JIRA issue, if none was open yet for it. Transactions were used to update the outstanding balance on the issues regarding the billing accounts. The currency conversion API was used too often, and it's purpose was only to give a rough estimate of the total balance in each Jira issue in USD, since each issue could have transactions in several currencies. The Beast would consume the Excel sheet, do some cryptic transformations on it, and for each resulting line access the currency API and upsert a JIRA issue. The secrets of those transformations were still hidden from the witchers. When and why would The Beast send emails, was still a mistery.
As the Witchers Council approached an end and all were armed with knowledge and information, they decided on the next steps.
The Wild Witcher, known in every tavern in the land and by the sea, would create a connector to The Red Port of Redis, where every currency conversion is already updated by other processes and can be quickly retrieved inside the VPC. The Greenhorn Witcher is to follow him and build an offline process to update balances in JIRA issues.
The Butchers of Jarfile were to build The Juggler, an automation that should be able to receive a parquet file with an insertion plan and asynchronously update the JIRA API with scores of concurrent requests.
The Smooth Witcher, proud of his new lead, was to build The Oracle Watch, an order that would guard the Oracle (DB) at the Temple of Cash-Flow and report every qualifying transaction to parquet files in AWS S3. The Data would then be pushed to cross The Event Bridge into The Cluster of Sparks and Storms.
This Witcher Who Writes is to ride the Elephant of Hadoop into The Cluster of Sparks an Storms, to weave the signs of Map and Reduce and with speed and precision transform The Data into The Insertion Plan.
However, how exactly is The Data to be transformed is not yet known.
Will the Witchers be able to build The Data's New Path? Will they figure out the mysterious transformation? Will they discover the Undocumented Java Tool's secrets on notifying customers and aggregating data?
This story is still afoot. Only the future will tell, and I will keep you posted.6 -
A new head of operations joins a small company.
— Okay guys, I’m planning for the long run. I need 500 warehouses across the country — we might need that capacity. We will build them rather than renting them — Amazon does the same thing, so we should too. We also need our own shipping fleet — FedEx has that too, so it’s a battle-tested approach. We might need that capacity. We need a future-proof solution.
— Uh… That’s kind of dumb. Are you kidding me?
A new head of engineering joins a small company.
— Okay guys, I’m planning for the long run. I need an AWS cluster running Kubernetes deploying microservices built with Docker. We might need autoscaling. Frontend should be Next.js + TypeScript — everyone does that now, plus we can develop a React Native app more easily if need be. We need a future-proof solution.
— Wow! That’s what I call a good manager. You really know what you’re talking about. You’re promoted!4 -
Want to make someone's life a misery? Here's how.
Don't base your tech stack on any prior knowledge or what's relevant to the problem.
Instead design it around all the latest trends and badges you want to put on your resume because they're frequent key words on job postings.
Once your data goes in, you'll never get it out again. At best you'll be teased with little crumbs of data but never the whole.
I know, here's a genius idea, instead of putting data into a normal data base then using a cache, lets put it all into the cache and by the way it's a volatile cache.
Here's an idea. For something as simple as a single log lets make it use a queue that goes into a queue that goes into another queue that goes into another queue all of which are black boxes. No rhyme of reason, queues are all the rage.
Have you tried: Lets use a new fangled tangle, trust me it's safe, INSERT BIG NAME HERE uses it.
Finally it all gets flushed down into this subterranean cunt of a sewerage system and good luck getting it all out again. It's like hell except it's all shitty instead of all fiery.
All I want is to export one table, a simple log table with a few GB to CSV or heck whatever generic format it supports, that's it.
So I run the export table to file command and off it goes only less than a minute later for timeout commands to start piling up until it aborts. WTF. So then I set the most obvious timeout setting in the client, no change, then another timeout setting on the client, no change, then i try to put it in the client configuration file, no change, then I set the timeout on the export query, no change, then finally I bump the timeouts in the server config, no change, then I find someone has downloaded it from both tucows and apt, but they're using the tucows version so its real config is in /dev/database.xml (don't even ask). I increase that from seconds to a minute, it's still timing out after a minute.
In the end I have to make my own and this involves working out how to parse non-standard binary formatted data structures. It's the umpteenth time I have had to do this.
These aren't some no name solutions and it really terrifies me. All this is doing is taking some access logs, store them in one place then index by timestamp. These things are all meant to be blazing fast but grep is often faster. How the hell is such a trivial thing turned into a series of one nightmare after another? Things that should take a few minutes take days of screwing around. I don't have access logs any more because I can't access them anymore.
The terror of this isn't that it's so awful, it's that all the little kiddies doing all this jazz for the first time and using all these shit wipe buzzword driven approaches have no fucking clue it's not meant to be this difficult. I'm replacing entire tens of thousands to million line enterprise systems with a few hundred lines of code that's faster, more reliable and better in virtually every measurable way time and time again.
This is constant. It's not one offender, it's not one project, it's not one company, it's not one developer, it's the industry standard. It's all over open source software and all over dev shops. Everything is exponentially becoming more bloated and difficult than it needs to be. I'm seeing people pull up a hundred cloud instances for things that'll be happy at home with a few minutes to a week's optimisation efforts. Queries that are N*N and only take a few minutes to turn to LOG(N) but instead people renting out a fucking off huge ass SQL cluster instead that not only costs gobs of money but takes a ton of time maintaining and configuring which isn't going to be done right either.
I think most people are bullshitting when they say they have impostor syndrome but when the trend in technology is to make every fucking little trivial thing a thousand times more complex than it has to be I can see how they'd feel that way. There's so bloody much you need to do that you don't need to do these days that you either can't get anything done right or the smallest thing takes an age.
I have no idea why some people put up with some of these appliances. If you bought a dish washer that made washing dishes even harder than it was before you'd return it to the store.
Every time I see the terms enterprise, fast, big data, scalable, cloud or anything of the like I bang my head on the table. One of these days I'm going to lose my fucking tits.10 -
I'm a python fanboy, not gonna lie.
I love everything about it. It's clean syntax, ready to use out of the box-ness, convenient built-in functions.
The one thing I hate is the official documentation. It's ugly, hard to navigate and a cluster fuck.
But it has proper information, so it's fine I guess. tsch12 -
Too many night shifts.
But it's done.
After the last migrations my emotional state is... Questionable.
VM migrations between different CPU vendors and generations leading to segfaults because of unsupported X86 extensions.... Thx for doing that at 23 o'clock after 8 hours of work....
Forgetting a left over NIC in a virtual machine, creating a routing loop, leading to very erratic behaviour and fun things.
Someone forgot to check the '"Unique" box, mass spawning a cluster of VMs with same MAC adresses....
DNS fuckery since someone thought that reboot would flush the cache of an DNS server.... Nope most DNS servers have persistent caches. You'll have to flush manually.
And let's not forget the joy of the 12 plus pages of when and where to move VMs, harddrives and VLAN configuration.
Oh migrations are such a festival of joy.
Finally done with that shit -.-4 -
Holy fcuk! Can anyone here help me understand how this domain is possible?
WARNING: obviously its a spam site. Take necessary security precautions if you are going to visit.
the following domain opens a cluster fuck domain name! >> secret.ɢoogle.com
That ɢ is not what it looks like. How is such domains possible to exist? Even more surprising, how is this sub domain -ception possible? 7
7 -
This just happened....
Tester: My cluster is not working properly!!!
Me: What's wrong?
Tester: I don't know. I've checked all the logs available on the entire cluster. All i know is that node 1 and 7 is broken.
*ssh into the cluster*
node1
# less /var/log/<affected application log>.log
*no errors here everything is working properly*
node7
# less /var/log/<affected application log>.log
*goes down to the bottom and scrolls up a few lines*
<insert massive error here>
Checked all the logs eh? 3
3 -
Building my own router was a great idea. It solved almost all of my problems.
Almost.
Just recently have I started to build a GL CI pipeline for my project. >100 jobs for each commit - quite a bundle. Naturally, I have used up all my free runners' time after a few commits, so I had to build myself a runner. "My old i7 should do well" - I thought to myself and deployed the GL runner on my local k8s cluster.
And my router is my k8s master.
And this is the ping to my router (via wifi) every time after I push to GL :)
DAMN IT!
P.S. at least I have Noctua all over that PC - I can't hear a sound out of it while all the CPUs are at 100%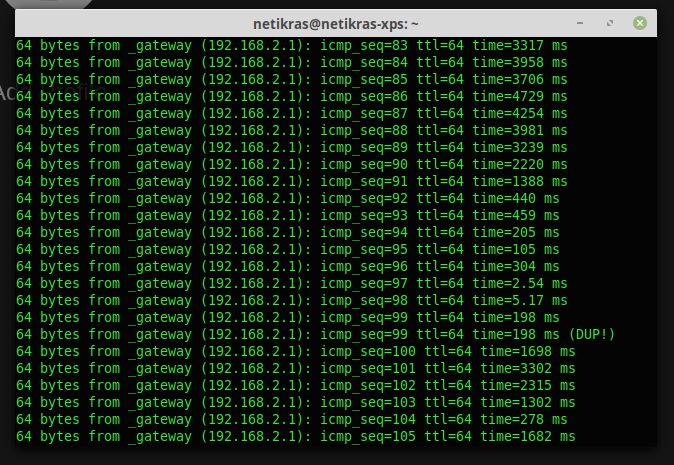 8
8 -
So, it's 22:40 here and I'm sat on a bench staring out at a pond because my stress and anxiety is at an all time high after a couple of weeks of hellish arguments with work and my personal life so as were all developers here to some degree let me convey my fucking thoughts here.
If you care more about maintaining your fucking superiority complex over writing good clean efficient code then get the fuck out of the industry.
I don't give two fucks whether you use Linux or Windows. I couldn't give two fucks about whether you use sublime, Emacs or VIM. I couldn't give two fucks about the framework you spend more time defending than coding in, because absolutely none of it matters if you code like a retard on bath salts you pretentious cunts.
Stop feeding you fucking ego. Absolute cluster fuck of an industry.4 -
Everyone and their dog is making a game, so why can't I?
1. open world (check)
2. taking inspiration from metro and fallout (check)
3. on a map roughly the size of the u.s. (check)
So I thought what I'd do is pretend to be one of those deaf mutes. While also pretending to be a programmer. Sometimes you make believe
so hard that it comes true apparently.
For the main map I thought I'd automate laying down the base map before hand tweaking it. It's been a bit of a slog. Roughly 1 pixel per mile. (okay, 1973 by 1067). The u.s. is 3.1 million miles, this would work out to 2.1 million miles instead. Eh.
Wrote the script to filter out all the ocean pixels, based on the elevation map, and output the difference. Still had to edit around the shoreline but it sped things up a lot. Just attached the elevation map, because the actual one is an ugly cluster of death magenta to represent the ocean.
Consequence of filtering is, the shoreline is messy and not entirely representative of the u.s.
The preprocessing step also added a lot of in-land 'lakes' that don't exist in some areas, like death valley. Already expected that.
But the plus side is I now have map layers for both elevation and ecology biomes. Aligning them close enough so that the heightmap wasn't displaced, and didn't cut off the shoreline in the ecology layer (at export), was a royal pain, and as super finicky. But thankfully thats done.
Next step is to go through the ecology map, copy each key color, and write down the biome id, courtesy of the 2017 ecoregions project.
From there, I write down the primary landscape features (water, plants, trees, terrain roughness, etc), anything easy to convey.
Main thing I'm interested in is tree types, because those, as tiles, convey a lot more information about the hex terrain than anything else.
Once the biomes are marked, and the tree types are written, the next step is to assign a tile to each tree type, and each density level of mountains (flat, hills, mountains, snowcapped peaks, etc).
The reference ids, colors, and numbers on the map will simplify the process.
After that, I'll write an exporter with python, and dump to csv or another format.
Next steps are laying out the instances in the level editor, that'll act as the tiles in question.
Theres a few naive approaches:
Spawn all the relevant instances at startup, and load the corresponding tiles.
Or setup chunks of instances, enough to cover the camera, and a buffer surrounding the camera. As the camera moves, reconfigure the instances to match the streamed in tile data.
Instances here make sense, because if theres any simulation going on (and I'd like there to be), they can detect in event code, when they are in the invisible buffer around the camera but not yet visible, and be activated by the camera, or deactive themselves after leaving the camera and buffer's area.
The alternative is to let a global controller stream the data in, as a series of tile IDs, corresponding to the various tile sprites, and code global interaction like tile picking into a single event, which seems unwieldy and not at all manageable. I can see it turning into a giant switch case already.
So instances it is.
Actually, if I do 16^2 pixel chunks, it only works out to 124x68 chunks in all. A few thousand, mostly inactive chunks is pretty trivial, and simplifies spawning and serializing/deserializing.
All of this doesn't account for
* putting lakes back in that aren't present
* lots of islands and parts of shores that would typically have bays and parts that jut out, need reworked.
* great lakes need refinement and corrections
* elevation key map too blocky. Need a higher resolution one while reducing color count
This can be solved by introducing some noise into the elevations, varying say, within one standard div.
* mountains will still require refinement to individual state geography. Thats for later on
* shoreline is too smooth, and needs to be less straight-line and less blocky. less corners.
* rivers need added, not just large ones but smaller ones too
* available tree assets need to be matched, as best and fully as possible, to types of trees represented in biome data, so that even if I don't have an exact match, I can still place *something* thats native or looks close enough to what you would expect in a given biome.
Ponderosa pines vs white pines for example.
This also doesn't account for 1. major and minor roads, 2. artificial and natural attractions, 3. other major features people in any given state are familiar with. 4. named places, 5. infrastructure, 6. cities and buildings and towns.
Also I'm pretty sure I cut off part of florida.
Woops, sorry everglades.
Guess I'll just make it a death-zone from nuclear fallout.
Take that gators!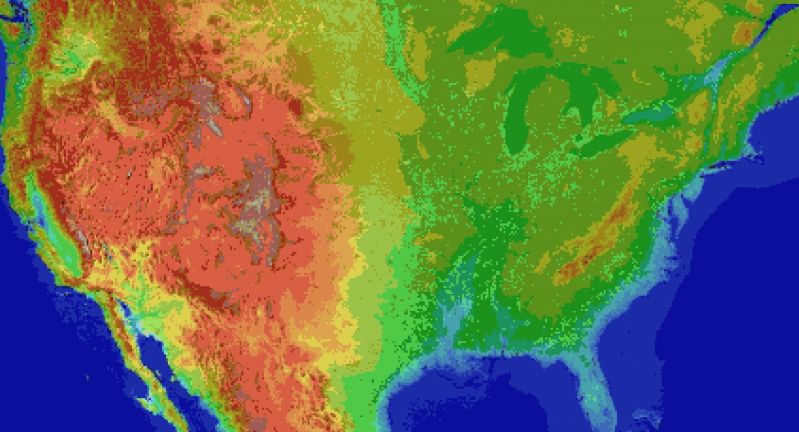 5
5 -
>Client complains about a 30 minute downtime around midnight
>Client also pays only for a single VM on a HV that they don't even own themselves
>Replies with an offer of how to make the setup more resilient, going from 1 VM to 2 LBs/FE loadbalanced through BGP, and distributing traffic through HaProxy onto 2 BE machines that in turn talk to a Postgres Cluster with RepMgr for dynamic failover.
>No reply so far
Hmmm :^)5 -
Boss activates encryption on dashboard
we installed the software
2 machines get locked out coz drive got encrypted with bitlocker
No one received the 48 bit key from bitlocker
I loose all my work coz the only way to use my laptop was to format the drive
Me as the technical guy and knowing how encryption works i just formatted the drive
Boss blames me for the cluster fuck8 -
Yesterday I shutdown a database cluster after 2 years of running it, what a ride it was... Felt a little bad when I removed the servers...learned a lot ...3
-
Me: do you have monitorin enabled for your cluster?
They: no
me: I recommend enabling it
they: naah, we're good
error: *occurs*
they: *try to guess at which hop which limits were or were not hit and/or which nw links could've dropped a packet with trial-and-error approach for days*
me: telemetry would give you an answer in under a minute....
They: ok cool. We're still good1 -
My boss did not care about making things secure in our early development stage, even though I told him several times.
After 1 day our elastic search cluster was filled with random crappy data.
Fix: Apply security schemes provided by AWS1 -
2 weeks and i leave my job.
Pro: no more dealing-with-math-msc-students
Con: i want to keep that juicy cluster to run my own calculations ;_;2 -
Just got a new job at an old school hardware company. The codebase is giving me heart attack. They don't care about dev experience or code navigation at all. Every attempts to modernize the codebase is so half assed. All patches are so bloated that make the codebase even worse.
Frontend is migrated from prototype-oop-jquery cluster fuck to AngularJS, then finally angular. Holy moly, all business logics are baked into UI "classes" using prototype chain. When they migrated to AngularJS, someone simply added a wrapper to that jQuery cluster fuck class and overwrote all the prototype with a 10k +lines file. Since all the methods are hidden in either prototype, JS object, or callback function, it's impossible to trace the data pipeline using IDE when "go to definition" on update() method gives you all the update methods/string in all objects/classes. And they don't care about immutability. References are taken out, renamed, and mutated everywhere. Finding the source of a bug is fucking guessing game.
I don't know what trick they use that makes cLion static analyzer fail.
And there is no unit test or spec doc.
Fuck me dead3 -
Monday is the deadline for a big project in my master, I worked together with 11 people for one whole year. Our repository is on a server from university and we use the uni cluster to evaluate our results.
And today the uni spontaneous turns of its electricyty for the weekend to test some fallback systems...2 -
Creating a cluster with shared storage in Proxmox
Once you've learned how to configure a single Proxmox host and Linux and Windows guests, the next step is to expand...
Want to continue reading this article? Register here with your corporate email address. Because your private email address isn't good enough, we need your corporate one.
No TechTarget, how about you go fuck yourself? As if anyone is going to register just to read one fucking article on your goddamn shitty site. Fucking wanketeering dickheads.7 -
At the institute I did my PhD everyone had to take some role apart from research to keep the infrastructure running. My part was admin for the Linux workstations and supporting the admin of the calculation cluster we had (about 11 machines with 8 cores each... hot shit at the time).
At some point the university had some euros of budget left that had to be spent so the institute decided to buy a shiny new NAS system for the cluster.
I wasn't really involved with the stuff, I was just the replacement admin so everything was handled by the main admin.
A few months on and the cluster starts behaving ... weird. Huge CPU loads, lots of network traffic. No one really knows what's going on. At some point I discover a process on one of the compute nodes that apparently receives commands from an IRC server in the UK... OK code red, we've been hacked.
First thing we needed to find out was how they had broken in, so we looked at the logs of the compute nodes. There was nothing obvious, but the fact that each compute node had its own public IP address and was reachable from all over the world certainly didn't help.
A few hours of poking around not really knowing what I'm looking for, I resort to a TCPDUMP to find whether there is any actor on the network that I might have overlooked. And indeed I found an IP adress that I couldn't match with any of the machines.
Long story short: It was the new NAS box. Our main admin didn't care about the new box, because it was set up by an external company. The guy from the external company didn't care, because he thought he was working on a compute cluster that is sealed off behind some uber-restrictive firewall.
So our shiny new NAS system, filled to the brink with confidential research data, (and also as it turns out a lot of login credentials) was sitting there with its quaint little default config and a DHCP-assigned public IP adress, waiting for the next best rookie hacker to try U:admin/P:admin to take it over.
Looking back this could have gotten a lot worse and we were extremely lucky that these guys either didn't know what they had there or didn't care. -
I'm so fucking frustrated with my ex company CEO, this motherfucker made everyone move to Bangalore costing is employees a good chunk of their salary and this delusional ASSHOLE knew that only half of the expected funding was coming in January 2023 itself and they'd be out of funds by July/August, they let go few folks from the team, fired the entire marketing team and expected to make the product profitable. The only reason I had stayed at that time was because the product was interesting to build and the scale I was working with was crazy like 100k request per minute peaks and avg of 10k rpm. I left the company in August...
This MOTHERFUCKER hasn't paid out final settlement after leaving for most employees and he openly says to the folks who are still working there that paying us is not his priority.
I hope your Atlas cluster gets fucking deleted, accesses revoked and entire AWS setup goes down forever, bitch.
We can't goto courts because the company law tribunal needs atleast 1 crore (1.2 million usd) of unpaid dues to declare it insolvent in a years time..
This asshole deducted taxes from our salaried but didn't pay them to the income tax department for an entire fucking financial year.
What a cheating, delusional, sick bastard. And he's still not willing to sell off the company to pay off the debts and call it a day.
Aarrghhhh on top of losing 2-3k USD I might have to pay my taxes approx 5-6k USD to the govt to keep my records well maintained.
What a grade A delusional asshole 😡
If he won't clear the dues till December, I'm gonna launch a mass of social media posts and destroy his reputation so that he doesn't get one penny of VC funds in the future I'm gonna make sure of that...4 -
This is the third part of my ongoing series "The Ballad of the Six Witchers and the Undocumented Java Tool".
In this part, we have the massive Battle of Sparks and Storms.
The first part is here: https://devrant.com/rants/5009817/...
The second part is here: https://devrant.com/rants/5054467/...
Over the last couple sprints and then some, The Witcher Who Writes and the Butchers of Jarfile had studied the decompiled guts of the Undocumented Java Beast and finally derived (most of) the process by which the data was transformed. They even built a model to replicate the results in small scale.
But when such process was presented to the Priests of Accounting at the Temple of Cash-Flow, chaos ensued.
This cannot be! - cried the priests - You must be wrong!
Wrong, the Witchers were not. In every single test case the Priests of Accounting threw at the Witchers, their model predicted perfectly what would be registered by the Undocumented Java Tool at the very end.
It was not the Witchers. The process was corrupted at its essence.
The Witchers reconvened at their fortress of Sprint. In the dark room of Standup, the leader of their order, wise beyond his years (and there were plenty of those), in a deep and solemn voice, there declared:
"Guys, we must not fuck this up." (actual quote)
For the leader of the witchers had just returned from a war council at the capitol of the province. There, heading a table boarding the Archpriest of Accounting, the Augur of Economics, the Marketing Spymaster and Admiral of the Fleet, was the Ciefoh Seat himself.
They had heard rumors about the Order of the Witchers' battles and operations. They wanted to know more.
It was quiet that night in the flat and cloudy plains of Cluster of Sparks and Storms. The Ciefoh Seat had ordered the thunder to stay silent, so that the forces of whole cluster would be available for the Witchers.
The cluster had solid ground for Hive and Parquet turf, and extended from the Connection River to farther than the horizon.
The Witcher Who Writes, seated high atop his war-elephant, looked at the massive battle formations behind.
The frontline were all war-elephants of Hadoop, their mahouts the Witchers themselves.
For the right flank, the Red Port of Redis had sent their best connectors - currency conversions would happen by the hundreds, instantly and always updated.
The left flank had the first and second army of Coroutine Jugglers, trained by the Witchers. Their swift catapults would be able to move data to and from the JIRA cities. No data point will be left behind.
At the center were thousands of Sparks mounting their RDD warhorses. Organized in formations designed by the Witchers and the Priestesses of Accounting, those armoured and strong units were native to this cloudy landscape. This was their home, and they were ready to defend it.
For the enemy could be seen in the horizon.
There were terabytes of data crossing the Stony Event Bridge. Hundreds of millions of datapoints, eager to flood the memory of every system and devour the processing time of every node on sight.
For the Ciefoh Seat, in his fury about the wrong calculations of the processes of the past, had ruled that the Witchers would not simply reshape the data from now on.
The Witchers were to process the entire historical ledger of transactions. And be done before the end of the month.
The metrics rumbled under the weight of terabytes of data crossing the Event Bridge. With fire in their eyes, the war-elephants in the frontline advanced.
Hundreds of data points would be impaled by their tusks and trampled by their feet, pressed into the parquet and hive grounds. But hundreds more would take their place. There were too many data points for the Hadoop war-elephants alone.
But the dawn will come.
When the night seemed darker, the Witchers heard a thunder, and the skies turned red. The Sparks were on the move.
Riding into the parquet and hive turf, impaling scores of data points with their long SIMD lances and chopping data off with their Scala swords, the Sparks burned through the enemy like fire.
The second line of the sparks would pick data off to be sent by the Coroutine Jugglers to JIRA. That would provoke even more data to cross the Event Bridge, but the third line of Sparks were ready for it - those data would be pierced by the rounds provided by the Red Port of Redis, and sent back to JIRA - for good.
They fought for six days and six nights, taking turns so that the battles would not stop. And then, silence. The day was won, all the data crushed into hive and parquet.
Short-lived was the relief. The Witchers knew that the enemy in combat is but a shadow of the troubles that approach. Politics and greed and grudge are all next in line. Are the Witchers heroes or marauders? The aftermath is to come, and I will keep you posted.4 -
- Launch the new version of the system I have been refactoring for 2 years and counting, then ceremoniously burn (literally) the legacy code as well as the cluster fuck of hardware it runs on.
- Decrease my stress + bus factor by bringing another up to speed on my code & the new version (his cluster fuck now).
- Pay attention to & take better care of health, my wrists in patricular.
- Find a mentor and mentor someone else.
- Get out of crisis management mode and find the time to write tuts, experiment and live a little.
- Find & join a local dev meetup, maybe make a local dev friend.
- Book leave and actually take it, preferabbly without having to take my laptop to the beach - actually, preferabbly at least have the choice to take a offline vacation.
- Sort through the drives containing ALL the code I have ever written, migrate the usefull interesting bits to Github.
Phew, that bit of self reflection was intense! I'm adding a cron to my server to sms & email me this rant in a year to remind me what hope looks like. -
@dfox Would you make it possible to cluster push notifications that occur on the same post? When I receive a lot of notifs at once it clogs up my notification center.
Additionally would it be possible so that I can completely turn off seeing certain types of notifs even in the app not just for push notifications (from what I gather that is the only thing I have control over)2 -
It seems that every Pi day, I end up with a new Raspberry Pi that I got sometime before it. First, a 1, then a 2+3, now I have a Zero as well. Next year, I'll have a cluster of 3s. No reason, just want to mess with it.1
-
Today marks the day that i finally get to do stuff on a production server.
Its just installing the elasticsearch cluster. But i still feel honored by the trust im given even tho im still an apprentice.6 -
For just 26 easy payments of $79.99, our AI cluster that consumes as much electricity as Guatemala will take photos of the hottest event (out of unconsenting people's phones), inpaint you into them next to the celebrities and post it to your Instagram and TikTok! For $19.99/mo you'll get at least 30 comments saying “mood af” and “🍆🍑💦”, and for $39.99/mo we will highlight other people's posts that were generated by our AI!1
-
Don't use your senior software engineer title or years of experience as reasons in a debate or argument about software
My manager was asking me what steps needs to be done to perform a disaster recovery for our cluster( on production). I will be honest here, I have not maintained this type of cluster(kubernetes) in production before. However, I have enough understand of the system to answer my boss question. I basically told him there are A, B, C you have to do.
My senior developer jumped in and said "No you should do A,C, B because C is more critical than B. " I then replied to him: "I understand your point, I notice that too, but .." Before I can even finish my sentence, this dude has already rolled his eyes and interrupted me very loudly: "Have you worked with these systems on production before? I did". The asshole knows I haven't maintained Kubernetes on production yet of course.
I got super pissed at him and pretty much shouted back to him and my manager: "Just because I haven't worked on this system on production yet, does not mean my argument is wrong" .
I then dragged my managers, that asshole, and other engineers in a room and settle this out. In the end, people agreed with my steps over that asshole senior engineer dude because I gave them rational reasons.
The conclusion is: Your senior title is given by the company, It doesn't mean anything to me. Also, it doesn't make you more right than another person just because he has a "lower" title than you.1 -
Today was a SHIT day!
Working as ops for my customer, we are maintaining several tools in different environments. Today was the day my fucking Kubernetes Cluster made me rage quit, AGAIN!
We have a MongoDB running on Kubernetes with daily backups, the main node crashed due a full PVC on the cluster.
Full PVC => Pod doesn't start
Pod doesn't start => You can't get the live data
No live data? => Need Backup
Backup is in S3 => No Credentials
Got Backup from coworker
Restore Backup? => No connection to new MongoDB
3 FUCKING HOURS WASTED FOR NOTHING
Got it working at the end... Now we need to make an incident in the incident management software. Tbh that's the worst part.
And the team responsible for the cluster said monitoring wont be supported because it's unnecessary....3 -
What if people, life, humanity, the universe is just a cluster of CPUs running a giant Recurrent Neural Network algorithm? 🤔
-Sun and food == power source
-People == semiconductors
-Earth/a Galaxy == a single CPU
-Universe == a local grouping of nearby nodes, so far the ones we've discovered are dead or not what same data transport protocol/port as us
-Universal Expansion == the search algorithm
-Blackholes: sector failures
-Big Bang == God turns on his PC, starts the program
-Big Crunch == rm -rf4 -
The Matrix. Then use the brains of the people plugged in like a computer cluster for large calculations.3
-
I am building a website inspired by devrant but have never built a server network before, and as im still a student I have no industry experience to base a design on, so was hoping for any advice on what is important/ what I have fucked up in my plan.
The attached image is my currently planned design. Blue is for the main site, and is a cluster of app servers to handle any incoming requests.
Green is a subdomain to handle images, as I figured it would help with performance to have image uploads/downloads separated from the main webpage content. It also means I can keep cache servers and app servers separated.
Pink is internal stuff for logging and backups and probably some monitoring stuff too.
Purple is databases. One is dedicated for images, that way I can easily back them up or load them to a cache server, and the other is for normal user data and posts etc.
The brown proxy in the middle is sorta an internal proxy which the servers need to authenticate with to connect to, that way I can just open the database to the internal proxy, and deny all other requests, and then I can have as many app servers as I want and as long as they authenticate with the proxy, they can access the database without me changing any firewall rules. The other 2 proxies just distribute requests between the available servers in the pool.
Any advice would be greatly appreciated! Thanks in advanced :D 13
13 -
I could kill someone. My boss occupied the whole cluster for 24h yesterday, so that I had to wait until today to see that I had a small bug in my code. I wasted a whole day waiting around for something I could have fixed in 5 minutes yesterday if I only had 1 free node on the cluster 😠
Worst of all, if anybody else had occupied the whole cluster for so long without asking, he would have sent an angry e-mail to the whole institute 😠4 -
At night is when my creativity starts flowing like a motherfucker. The moment when all the tasks are done for the day and you can start working on your own projects and just lay back and smoke (or drink, whichever you prefer) and zone the fuck out with some good music. Oh and if I've gotten a good work out in that day, then there's no stopping me.
I had no plans to even create an admin panel for my own small project but last night I made one just to make it look professional. After that, I got an idea for a separate project which I started working on. I usually write my ideas down so that I don't get into a complete project cluster fuck with 50 half completed projects, but sometimes you get that golden one that you have to start (currently those are the only two unfinished projects I got). -
So for a while I have wanted to build a raspberry pi cluster. In the spirit of shia labeouf I got started last saturday.
I had two pies lying around so I figured I'd run some experiments before I invested in a lot of hardware. After about a day I had turned the two pies into a shared cluster when disaster struck....
I had completely ignored the fact that you cannot run 32 or 64bit software on an arm processor (I know... I'm a java developer). So when I booted my service and the load balancer, I found that nothing worked. So pretty bumbed out, I quit the project.
Later that day I found a crazy guy who had bought a batch of 400 small form factor PSUs (300W) and internally I laughed at him a little. I mean, who's gonna sell 300W irregular power supplies. Then, just as I was about to go to bed I found this guy, he was selling from a batch of CPU-onboard motherboard for 10 bucks each and everything clicked!
I did some quick calculations and decided I could probably gather enough cash to get: 10 motherboards, 10 2GB ram dimms, 10 Sata disks and 14 PSU (in case some fail) and some misc hardware for networking and such.
So... Long story short, I am going to build a cluster computer, the first version is going to have 10 nodes and I am waiting for delivery right now!12 -
Here it goes,
So there I was a Linux enthusiast stuck in a windows job for about 3 years. I would spend my weekends doing Linux related tasks for my personal amusement, while I spent my week doing windows maintenance and development (partially) professionally.
It was about 2014 I started building an openstack cluster at home and i was so stoked! I searched for openstack summits or meetups and for my surprise there was an openstack meetup in my town. Holly 🐄 I said.
The date of the event came and I left work earlier to attend the meetup.
There , I had a talk with the meetup organizer/speaker and he told he was interested in what I was doing and that they were going to open a job in the next months.
A few months later still at my boring job I got an email from him for an interview.
Everything went just about right...and here I am a Linux systems engineer doing everything I love for a living... -
Four and half months,
Hundreds of hundreds PRs and one additional product cluster
By 6 Engineers..
To 500+ micro services
Which has no timezone or currency context,
Created by 250+ engineers,
To launch in a new country...
It didn't make me happy.
But the feedback from customers and drivers is priceless and #heartwhelming13 -
Avoid ACPICA if at all possible. It's one garbage tier cluster fuck of bad design, horrible documentation and downright misleading and wrong code
It's meant to consist of an ASL compiler, disassembler, debugger, dumper, various user space utitilies and a kernel resident OSPM implementation *if* you can figure out what belongs to what. Even just compiling this pile of trash is a mystery in itself. Think you need the source files in source/common? EEEEH, wrong. Well, at least partially since most of them seem to be for the user space stuff..? Other ones *are* needed on the other hand. At least the disassembler and/or debugger and/or dumper components seem to reference them. Not that I could figure out how to compile those anyways. The real path to your goal seems to be to ignore a seemingly arbitrary subset of source and header files until your linker stops complaining
There's also a bunch of configuration defines, some of which *you* define, some defined *for* you, based on again others. Of course most of them do stupid shit. Enabling the debugger automatically enables debug logging. Enabling the disassembler force enables debug allocation tracking... What?
The code itself isn't of much help either. Looking in "os_specific/service_layers" you find what looks to be reference implementations of acpica functions in certain os' like windows and unix. Of course I had a look because AcpiOsReadMemory is supposed to read physical memory and I don't know how I would even implement that. But hey, osunixxf.c (xf for interface... of course) should tell me. I'll let you see for yourself in the attached image. Apparently it does fuck all and just returns AE_OK. No error, no logging, no nothing. Just ok. As you can imagine, AcpiOsWriteMemory doesn't do much more either.
...okay so maybe physical memory accesses aren't actually used and these functions are some sort of relic from past times? Nope! They are absolutely necessary for doing low level device interaction. WTF. So finally I went to the linux source and checked how *they* implemented them, and just as I thought, these functions are anything but no-ops...
...So for what fucking reason do these stupid interface implementations even exist but to purposefully mislead you?? They aren't used for fucking anything! As far as I know Windows doesn't even *use* ACPICA and Linux have their own fork with working implementations... They just sit there, just to tell you how to NOT do it
So that's some of my thoughts about ACPICA. Note that I haven't even used it as a library yet, I just got it to compile and link and it already fucked with me this much.
There's also so much more I didn't mention like that you *have* to modify the acpica source in order to get your own platform header working (else #error) eventhough the docs explicitely instruct you not too but you get the point
Don't use ACPICA if you don't have to. Save your sanity for something that's worth it
-
What the fuck this fucking shit of an app supposedly went through five rounds of QA and I broke it in 5 minutes? Holy fucking shit How this is the main point of your job. You shitty shits take forever getting this PR to me and now it’s buggier than a haunted house on Halloween?
After this is after wanting to cuss Apple for making me update the os then then xcode then iTunes just to recognize the goddamn development phone. It’s an app built off Cordova it works for like 14 versions of iOS just run the bugger you over priced aluminum chassis dildo riding fruit Fuckers.
Now back to the goddamn cluster fuck I just got delivered. What the goddamn fuck. This level of bullshittery I have not seen before. And apparently Cordova is only partly de-sandboxed? I don’t know for sure because I don’t have time to test it because I’m running the entire technological stack of this company on a junior dev salary!
When you tell me it goes though all this QA and you spend 2 weeks on just QA tickets for fucks sake the first operation I do, the most common fucking operation on the app, the shit we have been building around all this fucking time, should not fucking error out. For fucks sake at least try to get the main fucking thing working. I recognize you did a lot of work and implemented a number of features but what the fuck good are they if I can’t even run them for one fucking time. -
Just finished dumping all ethereum tranasctions into one big 30 GB csv.
Only thing left is to configure Apache Spark cluster.1 -
I'm very short tempered at the moment.
A lot like Dr Cox in Scrubs.
And really ... You mother fucking stupid idiotic developers with your tendency to discuss absolutely everything just to not have to work for a dozen more minutes...
But ok. Let's discuss.
But even that seems to be absolutely impossible for you little shitheads.
Instead of discussing solutions, nooooooooo....
We're grown up developers so we discuss how the baddy manager hurt our lil feelings by saying that we're morons for wasting all the fucking time without coming up with a solution.
Now my lil cry babies, once the baddy manager got your pacifiers so at least once in an hour my migraine finally calms down for not hearing your bitching pathetic lil whiny noises...
Face it. Over the years you collected a huge ton of mother fucking tech debt because no one of you actually took a bit of time to use that empty space in your head to think at least a mu further than the dumb jira task you were given.
And yes. That ends badly.
And yes. As it is now in a state of cluster fuck, guess what. You have to work. You get money for it, remember?
And yes. if you would stop moping and bitching and crying and being a pathetic lil piece of shit, you'd realize we could come up with solutions very fast.
But nooo... Let's talk about our feelings.
And how we are over worked.
And how nothing works.
Cause yes. That will be the hail mary that saves us all.
Let me give u a hint: it's a mother fucking waste of time bitches.
I think it's time I put a pacifier not only in your mouth, but arse too. Maybe it helps overcoming the anal and oral phase of childhood so we can at least have something close to adult talk.
*breathes in*
Gooozfraba.3 -
OMG SharePoint is such a royal cluster fuck.
Random interface with some controls here, some controls there, sometimes shit is in one place, another time it is in another.
It is like a fucking retarded toddler glued a bunch of different animal parts together to make a pet monkey-horse-fish. Frankinware 🧟
Whomever runs that at Microsoft needs a spanking. Hell, their mother needs a spanking for birthing them.3 -
I already wrote a rant about this yesterday, but since I'm a sysadmin trying to convert to dev.. I dunno, maybe it's not a bad idea to muddy the waters a bit and talk about why not to be a sysadmin.
Personally I think it's that the perceived barrier to entry is just too high, while it isn't. You don't need a huge Ceph cluster and massive servers when you're just starting out. Why overbuild an appliance like that if it's gonna start out at maybe 5 requests a minute?
Let's take an example - DNS servers! So there's been this guy on the bind-users mailing list asking how to set up a DNS server on 2 public servers, along with a website. Nothing special I guess - you can read the thread here: https://0x0.st/ZY-d. Aside from the question being quite confusing, there was advice to read RFC's, get a book, read the BIND ARM, etc etc. And the person to deny this? No one less than Stephane Bortzmeyer, one of the people who works for nic.fr (so he maintains the .fr TLD) and wrote some of those RFC's as part of the DNSOP working group in the IETF. As for valid reasons to set up a DNS server? Could just be to learn how the DNS works, or hell even for fun. As far as professional DNS servers go.. this (https://0x0.st/ZYo9) is the nugget that powers the K root server, one of the 13 root servers that power the root zone of the internet, aka the zone apex. 2 RJ45 connections, and a console connection. The reason why this is possible is the massive recursor networks that ISP's, Google DNS, Cloudflare DNS, Quad9, etc etc provide. Point is, you don't need huge infrastructure to run a server!
Or maybe your business needs email. How many thousands of emails per second are you gonna need to build your mail server against? How many millions will you need to store? If your business has 10 employees and all of those manage about 10k emails total.. well that's easy, 100k emails total. Per second? Hundreds of emails per second per employee? Haha, of course not. Maybe you'll see an email a minute at most. That is not to say that all email services are like this - it is true that ISP's who offer email to their customers, and especially providers like Microsoft and Google do need massive mail servers that can handle thousands of emails per second. But you are not Microsoft or Google. So yeah, focus on the parts of email that are actually hard.. and there is plenty.
Among sysadmins you have this distinction between "professional" sysadmins and homelabbers. I don't mind the distinction itself but I think both augment each other. If you've started out by jumping into a heap of legacy at an established company, you will have plenty of resources, immediately high complexity, and probably a clusterfuck right away. But you will have massive amounts of resources. If you start out with a homelab, you will have not many resources, small workloads, and something completely new for you to build and learn with. And when running a server like that, you'll probably find that the resources required are quite small, to provide you with your new services. My DHCP servers take 12MB memory each. My DNS servers hover around the 40MB mark. The mail server.. to be fair that one consumes around 150. But if you'd hear the people saying that you need huge servers.. omg you need at least a TB of RAM on your server and 72 cores, massive disks and Ceph!1!
No you don't. All that does is scaring people away and creating a toxic environment for everyone. Stop it.1 -
There is this dude called Richard Eng which is sort of famous for 2 things:
First: he is known as *the* Smalltall evangelist of mothern times. And he constantly writes about it. Which is fine since he tries to attract new users to this beautiful and simple little language.
Second: his constant bashing of other technologies, mainly Javascript stating that it is the most harmful tech known to man.
The thing is, saying "use this because that is shit" is never going to convince a community, specifically one as potent as that of the JS community. And to make it worse...the dude links his reasoning about bad languages to articles he wrote. As in "this is shit, look at my completely biased article regarding why its shit"
Once he is confronted about it he links back to his own writings. Much like christian fanatics do
"good is real because it says so in the bible"
"but how can you trust that resource?"
"Because the bible is the word of God"
"and how do you know?"
"Because it is in the bible"
Circular arguments like that cannot be taken seriously. And what this guy does for the Smalltalk community hurts more than it helps really.
Claims like those are all around us. If we were to believe or consider them depending on who said what then we would never have the amazing cluster of tech choices that we have.
Take c++. It is absolutely powerful and gives you the ability to do pretty much anything. If we were to take Linus Torvalds's word about it being shit and only having subpar development we would miss on absolutely powerful tools.
The same came to me from Evee, writer of "PHP a fractal of bad design" or the "Node.js is cancer" article.
You are never going to please anyone with anything. I go by live and let live, and whilst I don't like some technologies I certainly don't look down on those that do.4 -
Who the hell deploys PROD environments in a STAGING cluster.....?
Who the hell deploys PROD environments in a PROD cluster and (deliberately) configures them to use a STAGING environment's DB cluster....? 5
5 -
There is a drawing competition for my currently most played game.
I'm on vacation and the deadline is when I get back. So what did I do?
I made an inspiration cluster with the character and drawings having this arrogant face (laptop, gimp).
I sketched on my phone and put it on my laptop (the sketch). I have no desk here so I'm drawing on my bed. I have no drawing pad so I'm drawing with my mouse. Then I draw it in gimp with colors and everything (the stroke in another program on my gfs laptop), put each layer in inkscape to svg-ify them and to hq-render them back in Gimp. Corrected a few things in Gimp. Added more detail, effects (glow, gradient instead of flat color ...).
~6 hours over two days. That was fun. And fucking unprofessional.7 -
Hey guys i wanna build a Pi-like Cluster to try out kunernetes locally and I would like some parts advice for the boards, casing, cooling, and the rack itself.
so far I have a Cisco E1200 Router I would use for the cluster for SSHing and connecting to3 -
I wanted to install this new software in our cluster but it didn't have Cmake on it, so I scp Cmake source files and then I started looking for a CMakeLists.txt file for compile it when I suddenly realized what I wanted to accomplish in the first place 😅1
-
Day 1:
Optimizing huge problems for the company. Get mail. *sigh*; Why is your script using up half the CPU on our thin clients? *place in complaints folder and go on*
Day 2:
Boss asks about it during scrum meeting. *Oh shits*
Need a cluster. Been asking for it for months...
Day 3:
Start runs on all thin clients. *Thou shall feel my wrath*
Complaints folder floods.
Day 4:
Expect rage from boss.
"IT seems to have found a cluster for you at last."
Finally! -
Set-up a 5 node EC2 cluster in AWS; Install my dependencies on all; Add private keys between all for handshake; Submit my Hadoop job for processing; AWS closes my instance within 10 minutes of starting a job that took me almost half an hour to set-up because the master node's spot costs have reached more than 15 USD :(
 2
2 -
Currently learning Kubernetes Cluster. Wow so much to learn.
Much easier to setup any app for a Cluster. Only building the Image takes time 🙄
Containers are the future ✌🏻6 -
Just needing somewhere to let some steam off
Tl;dr: perfectly fine commandline system is replaced by bad ui system because it has a ui.
For a while now we have had a development k8s cluster for the dev team. Using helm as composing framework everything worked perfectly via the console. Being able to quickly test new code to existing apps, and even deploy new (and even third party apps) on a simar-to-production system was a breeze.
Introducing Rancher
We are now required to commit every helm configuration change to a git repository and merge to master (master is used on dev and prod) before even being able to test the the configuration change, as the package is not created until after the merge is completed.
Rolling out new tags now also requires a VCS change as you have to point to the docker image version within a file.
As we now have this awesome new system, the ops didn't see a reason to give us access to kubectl. So the dev team is stuck with a ui, but this should give the dev team more flexibility and independence, and more people from the team can roll releases.
Back to reality: since the new system we have hogged more time from ops than we have done in a while, everyone needs to learn a new unintuitive tool, and the funny thing, only a few people can actually accept VCS changes as it impacts dev and prod. So the entire reason this was done, so it is reachable to more people, is out the window.3 -
1. Exporting fat jar
2. Transferring to cluster using WinSCP
3. Running it in the cluster.
4. Find a small bug.
5. Repeat
I HATE IT1 -
Stupid pipeline bullshit.
Yeah i get it, it speeds up development/deployment time, but debugging this shit with secret variables/generated config and only viewable inside kubernetes after everything has been entered into the helm charts through Key Vaults in the pipeline just to see the docker image fail with "no such file found" or similar errors...
This means, a new commit, a new commit message, waiting for the docker build and push to finish, waiting for the release pipeline to trigger, a new helm chart release, waiting for kubernetes deployment and taking a look at the logs...
And another error which shouldn't happen.
Docker, fixes "it runs on my machine"
Kubernetes, fixes "it runs on my docker image"
Helm, fixes "it runs in my kubernetes cluster"
Why is this stuff always so unnecessarily hard to debug?!
I sure hope the devs appreciate my struggle with this... well guess what, they won't.
Anyways, weekend is near and my last day in this company is only four months away.2 -
Developing and deploying in Xcode is some Requiem for a Dream level bullshit.
I literally just de selected everything for managing automatic signing, and re-selected the EXACT SAME GODDAMN THING. And it worked. It’s literally some fucking shit you do when you are first learning how to code or learning a language and you keep flipping something but you don’t get exactly how it works.
But this is YOUR FUCKING FLAGSHIP development product. I shouldn’t have to check my goddamn inception totem to see if I’m dreaming or not because this kind of bullshit can’t be real life.
That being fucking said your bullshit forced shutdown also FUCKED MY ANDROID STUDIO INSTALLATION AND FUCKED MY $PATH. Thanks. Now NOTHING WORKS. Fuck you Apple. Between slowing my phone and the cluster or problems your shit is causing that are just random as hell and are plenty common because thank god people smarter than me have fixed them in SO by now, I am SO READY TO LEAVE THE APPLE ECO SYSTEM. If I didn’t have to use one of the boxes to push iPhone app updates I doubt I would touch one again.
Apple stuff looks good but at this point that’s about it. -
Today I learned that some external devs one of our projects is working with have DB tables where they store references to specific dates, and not only that, but every minute of those dates, and the day of the week, and what season its in. Im not joking.
Hmm should I use the local datetime libs or should I go through a firewall, load balancer and DB cluster just to find out what day it is? -
Setting up a single node Hadoop cluster. Then installing intellij idea, to find that it doesn't detect any installed jdk. Then uninstalled all jdks, and then reinstalled one, then Hadoop won't work. Now everything seems fine.
-
Things I love today.
Totally love. Like kick in the balls with testicle torsion love. Picking my eyeballs out with a spoon... I think you got the idea.
Getting updates of other managers, as I'm busy with other stuff.
More or less goes like this:
Flaky tests. Since weeks...
Ain't nobody got time for that.
🤬
I don't wanna upgrade that version to the next major version, cause then I'd have to do tests... And the tests are flaky.
🤬🤬
I wanna have shiny new thing XY, but NOONE wants to upgrade to next major version so we cannot have that
🤬🤬🤬
Oh we just crushed the live cluster cause there's this PR everyone constantly ignores cause the tests are flaky....
🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬🤬
Good thing I'm busy and just getting all the updates via the gossip mill...
I'm just prolonging my current tasks as I really don't wanna have to fix that mess.
My fix would be probably eye for eye, tooth for tooth.
...
Problem is.... I'm slowly getting into trouble because some of these fixes would be much needed for my task...
Why do I have always to be the bad cop in the company -.
I think I'm gonna ask HR what applying electro shocks would cost me, cause I think that would solve a lot of problems.
10 kV for every stupid answer.
Smells like bacon!4 -
I'm currently between jobs and have a few rants about my previous job (naturally). In retrospect, it's somewhat therapeutic to range about the sheer brainfuckery that has taken place. Enjoy!
First, let me set the scene: legacy B2B web app made with LEMP stack and sencha ext.js 3 + 4 (don't ask) and a lot of madness. Let's call that app "Alpha".
Alpha is a self made CMS build for typical ERP stuff. Yes, a self made CMS: entities are containers, containers have types and fields and values. Like so many legacy PHP apps, it does not have a dedicated FE: the HTML is rendered on the server and then spewed out to the browser.
Easy right? Coding like it's 1999! But there was a twist: Because everything is basically a container, the HTML-templates are saved in the DB. Along with the nessary JS and the CSS. And the translation variables. Why? Because fuck you! That's why. Who needs a git history anyways.
For some reason, Alpha was kinda slow.
There was also an editor, that allowed you to modify templates (web, mail, pdf) on the fly in prod. Because templates contain repeating data (header/footer), one template could contain additional templates. Much confusion. You could change templates via migration (slow, boring) or just ctrl-c/ctrl-v that sucker (fast, much excitement).
Did I mention Alpha was slow?
On with the rant: e-mails! How do they work? Noone knows. How to send mails asynchronous in PHP? Witchcraft is the only possible answer to that riddle. Here is your enterprise™ solution:
1. create mail
2. insert mail into DB
3. WAIT UP TO 59 SECONDS FOR A FUCKING CRON TO SEND MAIL
Why? "Because that way, we can resend mails in case the network is down :)"
Same procedure for the SOAP-API (db-queue + cron). You read that right: all requests to various other systems are processed once a minute.
Alpha slow.
Alpha was only one of several systems. Imagine a bunch of monolithic php apps, interconnected via SOAP, REST and GraphQL like a godamn intergalactic orgy. Image having to debug that cluster fuck.
Let's say there is a bad request. These things happen. No biggie. Remember the db-queue? Let's try to send the bad request a second time! And a third time! Still no luck? How odd. Let's create a specific file in a specific directory: a LOCK-file. Now, "the db-queue is on hold and no request gets processed :)"
Golly gee thanks Alpha.
Anyhow, did you know that MySQL has a join limit of 61 tables? 3
3 -
Completely fucked up replication of MySQL servers.
Remote: 2 different database Servers
--> made sense.
Except the misconfiguration. Or better: No configuration at all.
So how to solve the massiv delays and make everything even more crazy?
2 remote servers - 2 readonly slaves for reading data remote (master - slave)
2 local (internal) servers.
Remote - Local Master Master.
Unfucking this cluster fuck was a real nightmare.
It had to be done at night, cause everything needed to be ripped apart.
And the servers were the backend of a warehouse with supply chain and multiple selling channels (Amazon, eBay etcetera).
So. It had to run the next day at 05.00 clock so the incoming orders could be packaged / prepared for shipping.
That was fun. Not.
And the clusterfuck died spectaculously on my first work day - the old DBA was gone (fired....)
:) -
Just got handed a dozen servers. Documentation shows a (Linux) database cluster is using ldap authentication. I try logging in with my creds. No joy. I look up the root password and log in.
Not only is it not configured to use ldap, it's also not clustered.
I need more coffee. -
Low budget companies be charging insane prices to clients and let the junior frontend dev setup a Azure cluster.. then wonder why it suddenly falls apart at the end of the project
-
One of my colleagues who thinks he knows all about "big data": "I try to put everything in hadoop, that is my philosophy".
We don't even have a hadoop cluster. -
Got handed a CentOS 7 cluster, previous admin made kernel command line changes in grub.cfg instead of default/grub.
Ah, thank you. -
Ever wonder why there are so few HomeKit devices on the market? It's not any absurd Apple licensing this time... it is that the Accessory Development Kit / Software Development Kit (adk/sdk) is such a land of broken toys, that's why.
The base install per the guide on the Raspberry PI as a prototyping system system is a complete cluster fuck. The install itself breaks all over the place. Clearly these people are not embedded firmware engineers.
They could have just created a ready-to-go Raspberry PI disk image that you master over to a microSD card but noooo...
(They should be put on an island and work on embedded missile firmware. Those that are still breathing in 6 months might be real firmware engineers and not script kiddies.)
If you ever manage to get their garbage to actually work with the bags of shitty tools approach to a "dev stack" ... you should seriously be awarded a Nobel prize for patience and dedication.
The Made for 'i' (whatever the fuck 'i' stands for in MFi) is really "Made For Idiots" or "Mother Fucking Interface".
<https://mfi.apple.com/en/...>
Bunch of fucking bureaucrats more worried about certification and use of logos than product development.2 -
L1 support requested to terminate an EC2 instance on which one of our apps seemed to be misbehaving. The node was terminated after few min.
L1 later realized that that instance didn't belong to that app, but instead it was one of the RabbitMQ nodes.
Then, after some panicking we remembered that HA was enabled, so nothing should've been lost.
Later, we realized that the recent RMQ upgrade necessitated a new cluster on which HA was NOT enabled!1 -
The most difficult part about learning/working with new technology is the lack of online support and a really small community! So every time you're stuck with an error you got to open each and every configuration file to see which little value was throwing that page long error!!!!
The same happened with me while working with the new RedHat CEPH Storage while I was configuring my nodes using ceph-ansible. A new error pops up and it was like reaching milestones when I found the error halting up the execution of the playbook!1 -
A few weeks back we ported our PHP Rest API into a couple of Go micro-services.
Incredibly _satisfying_ job.
Requests went from 20+ seconds to ~100-300ms.
There was still one bottle-neck, though, because we had to use most of the old cluster-fork of a database (because no way I'll be able to fix all that in a week).
And ooh, next we're thinking of switching to gRPC. Man, we have the best jobs.5 -
Task: Deploy MinIO in k8s cluster
Me: deploys the first docker image found on google: bitnami/minio
MinIO: starts
Me: log in
MinIO: Fuck you! There's a cryptic error: Expected element type <Error> but have <HTML>
Me: spends half a day trying out different vendors, different versions, different environments (works on local BTW)
Me: got tired, restored the manifest to what it was at the beginning. Gave it the last try before signing off
MinIO: works 100%
wtf... So switching it back and forth fixed the problem, whatever it was. Oh well, yet another day.6 -
You know what I had to deal with
A bunch of these shit
try{
//Shitty cluster fuck excuse for java
//code
}catch(Exception e){
}1 -
I am so sick of this place. Production deployment shouldn't be such a massive cluster fuck of different departments and sometimes redundant configurations. Knowing who to talk to about a problem shouldn't change daily, and it shouldn't be hard to figure out.
My jvm doesn't appear to be running in production. I hunt down the fucker who is supposed to be handling this problem today...but he's out of office and no one knows who his stand in is...GODDAMNIT!2 -
code reviewed a "senior" developers code (guy has been at the companyny since noah and his clay computer tablets), he replied with my comments against it stating he has more experience than i have and that i shouldnt do anything except just sign off the stuff to production, stuff goes to production and breaks a massive financial cluster fuck of a mess, who gets the blame for releasing the code to production ? Junior me !!! gotta love it when management needs scapegoats of FIFO people.2
-
(Repost: Broken Link)
Announcing Covey (v0.1)!
A lightweight (or at least that's the goal) Linux cluster orchestration/management system.
https://github.com/chabad360/covey
Why?
Because there are no systems with a (web) GUI (that I could find) that can run on a Raspberry Pi or similar.
This doesn't have a GUI!
It's coming in the next week or so (hopefully).
The codebase is shit!
I know, I'm actively refactoring it (feel free to send a PR).
What is it written in?
Go, with Postgres as the database.
Can I use it?
Go ahead and try, it's currently more in the MVP stage then at the stage where I recommend you use it.
Do you know what you're doing?
Maybe... This is my first big project in Go, and the first time I've ever used SQL. So I'm learning as I go along.9 -
Posted previously about our codebase being a monolithic, poorly-written, pain-to-maintain gigantic cluster-fuck. And the efforts made to rewrite it.
Well, we made huge success the previous year in this regard. I rewrote the entire API while my other team mates worked on two different UI apps one of which is now in production and the other soon to be released in alpha.
Processes have being put in place for our team and are being improved.
We still have some technical debts though.
Dev goal for 2020,
- Pay most of the technical debt.
- Dive deeper into Flutter and finish the app I wanted.
- Play with ML, AI and Game dev.4 -
Hello devRant!
Man its been a while, i havent logged in here in like 4 years.
Recently ive been getting into home-labbing, and i thought to myself
"all of these people on youtube/reddit run Plex on pre-built NASs that have awful celerons and whatnot, we can do much better!"
And by "much better" i meant a bare metal k8s cluster.
My hybris knows no bounds apparently.
Turns out this shit is quite hard.
Really gives u an appreciation of just how much stuff cloud providers magically abstract away....
My final goal is to run stableDiffusion on this thing, even know i know full-well the moment i try Nvidia will fuck me raw with some hidden enterprise subscrition :) -
Let's see what's on the menu today:
* Web Application Catastrophe Special *
Includes, but not limited to:
- Orphaned server processes in the configuration management cluster
- Microservice back-end architecture with no API documentation
- Poorly implemented cache microservice with no documentation
- Stale data causing everything to be shown as down in production, despite everything running fine
Cost: 1 developer's sanity -
I'm quite pleased to show off the initial rendering of my CaaB (Cluster as a Box)!
This is a project that I've put not enough time into, and them finally I decided to get a move on with it. The estimated cost of the whole device/s ranges somewhere around $600. It's gonna be fun!
P.S. Suggestions welcome, particularly if it's about a substitute for the ODroid HC1. 8
8 -
I really want to build a raspberry pi cluster but I don't know what to do with it...
Has anyone of you ever built a raspi cluster?
What could I do with it?9 -
I don't like when client decide which tech use in the project. I got some weird tech request like:
1. Move existing database from postgresql to Hadoop because hadoop is Big Data (is kinda move from amazon rds to amazon s3 just why? have you index, cluster your postgresql table?)
2. Move from mysql to postgresql because mysql cause deadlock (maybe their previous developer just fucking moron)
In this situation we just explain why we don't use that and propose alternative solution. If they insist with their solution either ignore it or decide not continuing the project.5 -
Give me a second to get my todo list.
- get a office/server room built
- setup a home kubernetes cluster
- create an open-source ActivityPub whatsapp clone
- unify existing ActivityPub implementations where an account on one can be used on others
- finish dockerssh
- create an irc bridge for signal messenger.
- find a way to fully provision linux workstations fully unattended2 -
Oh my.. I think I'm enjoying molesting kubernetes :)
A while ago I got pissed at k8s because with 1.24 they brought backward-incompatible changes, ruling my cluster broken. Then I thought to myself: "why not create a Docker image that would run kubernetes inside? Separate images for control plane, agent and client"
Took me a while, but I think tonight I've had a breakthrough (I love how linux works...)!! The control-plane is spinning up!! Running on containerd
Still needs some work and polishing, but hey! Ephemeral k8s installation with a single docker-run command sure sounds tempting!
P.S. Yes, I know there is `kind` and 'kinder', but I'm reluctant to install a separate tool that installs a set of tools for me. Kind of... too shady. Too many moving parts. Too deeply hidden parts I may have to fix. Having a dumb-simple Dockerfile gives me the openness, flexibility and simplicity I want. + I can always use it as a base image to add my customizations later on! Reinstalling a cluster would be a breeeeeeze6 -
Screw DataStage
Screw Saleforce
Screw the $25k/week Vendor who finishes work maybe 60% complete, if I’m being generous.
Screw the business rushing to us to fix their shadow IT cluster.5 -
## Learning k8s
Okay, that's kind of obvious, I just have no idea why I didn't think of it..
I've made a cluster out of a rpi, a i7 PC and a dell xps lappy. Lappy is a master and the other two are worker nodes.
I've noticed that the rpi tends to hardly ever run any of my pods. It's only got 3 of them assigned and neither of them work. They all say: "Back-off restarting failed container" as a sole message in pod's description and the log only says 'standard_init_linux.go:211: exec user process caused "exec format error"' - also the only entry.
Tried running the same image locally on the XPS, via docker run -- works flawlessly (apart from being detached from the cluster of other instances).
Tried to redeploy k8s.yaml -- still raspberry keeps failing.
wtf...
And then it came to me. Wait.. You idiot.. Now ssh to that rpi and run that container manually. Et voila! "docker: no matching manifest for linux/arm/v7 in the manifest list entries."
IDK whether it's lack of sleep or what, but I have missed the obvious -- while docker IS cross-platform, it's not a VM and it does not change the instructions' set supported by the node's cpu. Effectively meaning that the dockerized app is not guaranteed to work on any platform there is!
Shit. I'll have to assemble my own image I guess. It sucks, since I'll have to use CentOS, which is oh-so-heavy compared to Alpine :( Since one of the dependencies does not run well there..
Shit.
Learning k8s is sometimes so frustrating :)2 -
fuck.. FUCK FUCK FUCK!!!
I'mma fakin EXPLODE!
It was supposed to be a week, maybe two weeks long gig MAX. Now I'm on my 3rd (or 4th) week and still got plenty on my plate. I'm freaking STRESSED. Yelling at people for no reason, just because they interrupt my train of thought, raise a hand, walk by, breathe, stay quiet or simply are.
FUCK!
Pressure from all the fronts, and no time to rest. Sleeping 3-5 hours, falling asleep with this nonsense and breaking the day with it too.
And now I'm fucking FINALLY CLOSE, I can see the light at the end of the tunne<<<<<TTTOOOOOOOOOOOOOTTTTT>>>>>>>
All that was left was to finish up configuring a firewall and set up alerting. I got storage sorted out, customized a CSI provider to make it work across the cluster, raised, idk, a gazillion issues in GH in various repositories I depend on, practically debugged their issues and reported them.
Today I'm on firewall. Liason with the client is pressured by the client bcz I'm already overdue. He propagates that pressure on to me. I have work. I have family, I have this side gig. I have people nagging me to rest. I have other commitments (you know.. eating (I practically finish my meal in under 3 minutes; incl. the 2min in the µ-wave), shitting (I plan it ahead so I could google issues on my phone while there), etc.)
A fucking firewall was left... I configured it as it should be, and... the cluster stopped...clustering. inter-node comms stopped. `lsof` shows that for some reason nodes are accessing LAN IPs through their WAN NIC (go figure!!!) -- that's why they don't work!!
Sooo.. my colleagues suggest me to make it faster/quicker and more secure -- disable public IPs and use a private LB. I spent this whole day trying to implement it. I set up bastion hosts, managed to hack private SSH key into them upon setup, FINALLY managed to make ssh work and the user_data script to trigger, only to find out that...
~]# ping 1.1.1.1
ping: connect: Network is unreachable
~]#
... there's no nat.
THERE"S NO FUCKING NAT!!!
HOW CAN THERE BE NO NAT!?!?!????? MY HOME LAPTOP HAS A NAT, MY PHONE HAS A NAT, EVEN MY CAT HAS A MOTHER HUGGING NAT, AND THIS FUCKING INFRA HAS NO FUCKING NAT???????????????????????
ALready under loads of pressure, and the whole day is wasted. And now I'll be spending time to fucking UNDO everything I did today. Not try something new. But UNDO. And hour or more for just that...
I don't usually drink, but recently that bottom shelf bottle of Captain Morgan that smells and tastes like a bottle of medical spirit starts to feel very tempting.
Soo.. how's your day2 -
i found playing with arduino is never-ending fun. and then i tried Raspi and feeling the same. now i buy a bunch of raspi and trying to cluster them up, just for another random project.
yeah this is clearly nonsense. this is myself when my boredom gets high enough. No, vacation is not helping, trust me i've been camping in a jungle for 5 days and the next week i go to the beach. this is bad.
making things worse, My way of life is like any ordinary people (or maybe a developers) but turned upside down for example I program, learning for fun, and going vacation is just another medical need that i need to follow.
I am an university student, studying IT. I've been programming since 6, and geeking anything around technology and astronomy till now. this is my third semester and i don't get challanged enough for this kind of curricullum. i need some kind of project that even i don't think about any number of money anymore, but just enough to challange me up. just need to get rid my boredom.
sorry for ranting from a to z, this is just buzzing around my mind. -
Where can i get good second hand servers, am planning to homelab cluster. Will appreciate any pointers ...8
-
I hope my boss learned his lesson: dd if=/dev/zero of=[hdd storing DB about VM cluster]
- is a very very bad idea...10 -
More and more, I am getting frustrated/depressed from the attitude of our customers who complain, moan and get angry about issues in their infrastructure, while at the same time, refusing to pay more so the issues could be mitigated.
Like, a client's angry with us today for having one of their non-production-critical databases inaccessible for... Hmm... About 8 hours now (So a whole workday).
Like... I get it, some of your employees couldn't work with it offline, but like... What the hell do we do? You keep data from as far back as several years ago in there, without partitioning, without exports, in a mix of innodb and myisam, so when the DB crashes, and its replication has to be reset from zero, reimporting all the data takes hours upon hours, and importing .sql files just takes time.
Or another client who got angry when their app fell out of the internet, cuz one of their myisam-based log tables crashed, and had to be repaired, with data spanning several years back, meaning it took hours to fix...
The more I work with these "basic" and "simple" infrastructure designs that is *not* redundant, or HA, the more I wonder -- How do the big names out there do it? How do you design systems with fault tolerance so a single DB table crash doesn't lead to the whole app getting inaccessible?
We have... One, exactly one, client, who uses MariaDB with Gallera, and that cluster is *amazing*, it just keeps chugging along, without a care in the world. But it cost them quite a lot, as they had to buy 3 DB servers, instead of 1...1 -
I've never been a big fan of the "Cloud hype".
Take today for example. What decent persistent storage options do I have for my EKS cluster?
- EBS -- does not support ReadWriteMany, meaning all the pods mounting that volume will have to be physically running on the same server. No HA, no HP. Bummer
- EFS -- expensive. On top of that, its performance is utter shit. Sure, I could buy more IOPS, but then again.. even more expensive.
S3 -- half-assed filesystem. Does not support O_APPEND, so basically any file modifications will have to be in a
`createFile(file+"_new", readAll(file) + new_data); removeFile(file); renameFile(file + "_new", file);`
way.
ON TOP of that, the s3 CSI has even more limitations, limiting my ability to cross-mount volumes across different applications (permission issues)
I'm running out of options. And this does not help my distrust in cloud infras... 9
9 -
From HTML CSS javascript to some voodoo WPF xaml and c#, mvvm and databinding dependency inject cluster bomb to my brain god Microsoft just put a tutorial out like a normal group of people. where you do examples of projects. I'm 2 weeks in and this still makes no sense5
-
## Learning k8s
Sooo yeah, 2 days have been wasted only because I did not reset my cluster correctly the first time. Prolly some iptables rules were left that prevented me from using DNS. Nothing worked...
2 fucking days..
2 FUCKING DAYS!!! F!!!11 -
It seems he is trying to replace HTML with svg and canvas when basic html and css can be used to make beautiful dashboards.
Like i anticipated it is gonna be a ux cluster fuck, where most of the website is an ugly bootstrap contraception and some parts gonna look like futuristic. -
Monitoring tools madness: quest foglight.
So, setting a blackout for an FMS "HA cluster" (which does not work due to a bug infested custom jboss implementation) can bring the servers down... And no way to bring them back up.
This brilliant piece of enterprise APM software costs 600.000€ for a 5year license.
I,ve added more drama (logs, threaddumps, support bundles and screenshots) to the support portal...
45 cases now in total, oldest case still open date 2017...
Fuck you quest software4 -
launched major version today which has been in development nearly 2 years. daily bugfix builds for the next month or so until it's stable as we slowly rollout one cluster at a time. going to be my first time on production bugfix duty. man it feels cool to be a full time software engineer.
-
Dear AWS, your Elasticsearch service is a bogus pile of shit-engorged horse fly larvae. Not only do you give no useful visibility into what's happening with the cluster (making diagnosis a sadistic guessing game), you lock down the fucking settings API, making it impossible to debug!! But your excellent support is on it! I wonder if I'll hear back from them this week with another inane suggestion like "increase the node count". Meanwhile the rest of my system is limping along, sometimes getting data where it's supposed to be while I keep fake-smiling and reassuring management and customers that "I'm working on it". If you're going to offer a service either make sure it works or get the fuck out of my way. I'll be moving my cluster back to EC2 and you can go do a back flip off a skyscraper. I need a drink2
-
In three days my team closes the book on this monolithic cluster of a project that I thought would never end! I feel like Christmas is coming. Hopefully the PM doesn’t let the business throw us into another scope-less pit like this again! 😩3
-
Is it normal for "enterprise" software to have 14+ pages of known issues in the release notes, including issue descriptions that use phrases like "may lead to data corruption" and "may cause the cluster to crash"??2
-
They say that runing the same command over and over again is a sign of insanity.
LIKE HELL IT IS!!!
I've been running `terraform apply` for the last hour (trying to dump an EKS token in plain-text, because my k8s-related providers failed to auth to the cluster), and miraculously the problem went away. Now the error is no more.
Insanity?
I beg to differ!
Narf! 2
2 -
If you would have a cluster made of 10 RPi, what would you do? I'm looking for fun project to make and I'm willing to learn new things.7
-
My final year taking a B.Sc. I'm writing up my Distributed Systems project, the day before handing it in. It's on top of Transis, and source code is "stored" in RCS (yes, I'm that old). The project is a reliable system administration tool, that performs the same action across a cluster with guaranteed semantics.
I'm very proud of the semantics, but cannot figure out why the subdirectory installation stuff works almost but not quite. Here's my sequence of actions:
1. Install across all machines.
2. Manually see it's broken.
3. "rm -rf *".
4. Repeat.
What in to discover is that the subdirectory installation always finishes off in a current directory 1 level higher than where it started. Oh, and the entire cluster sees my NFS home directory. Oh, and I'm running each cluster member in a deep subdirectory of my dev directory. Oh, and my RCS files live in a subdirectory of my dev directory.
All of a sudden, my 5 concurrent "rm -rf *"s were printing weird error messages about ENOENT and not being able to find some inodes. In a belated flash of brilliance, I figure out all the above, and also that I've just deleted my dev directory. 5 times, concurrently. And the RCS files.
That was the day a kindly sysadmin taught me than NetApps have these .snapshot directories. -
*The one where he breaks ssh*
TL;DR: Minikube's dick is too big, and my ass wasnt ready.
So there was a time about 2 weeks ago where i wanted to try and set up a minikube cluster using SOP, and that actually went okay, aside from having to move over to a completely different server after discovering that my processor doesn't support virtualization.
So i set it up on my other server, and everything immediately starts going to shit; i can no longer run commands without processor latency. Also top shows 200% CPU usage. Maybe i should stop... NAHHH... so i continue on, and the biggest fuck up was starting up the nginx pods. I have 6 of them, and the moment i try and stand up my custom container which was the WHOLE POINT of this whole exercise, i lose ssh access and cant get back in. I go over to the server and kill the minikube and virtualbox processes, and everything's back to normal.6 -
## Learning k8s
Interesting. So sometimes k8s network goes down. Apparently it's a pitfall that has been logged with vendor but not yet fixed. If on either of the nodes networking service is restarted (i.e. you connect to VPN, plug in an USB wifi dongle, etc..) -- you will lose the flannel.1 interface. As a result you will NOT be able to use kube-dns (because it's unreachable) not will you access ClusterIPs on other nodes. Deleting flannel and allowing it to restart on control place brings it back to operational.
And yet another note.. If you're making a k8s cluster at home and you are planning to control it via your lappy -- DO NOT set up control plane on your lappy :) If you are away from home you'll have a hard time connecting back to your cluster.
A raspberry pi ir perfectly enough for a control place. And when you are away with your lappy, ssh'ing home and setting up a few iptables DNATs will do the trick
netikras@netikras-xps:~/skriptai/bin$ cat fw_kubeadm
#!/bin/bash
FW_LOCAL_IP=127.0.0.15
FW_PORT=6443
FW_PORT_INTERMED=16443
MASTER_IP=192.168.1.15
MASTER_USER=pi
FW_RULE="OUTPUT -d ${MASTER_IP} -p tcp -j DNAT --to-destination ${FW_LOCAL_IP}"
sudo iptables -t nat -A ${FW_RULE}
ssh home -p 4522 -l netikras -tt \
-L ${FW_LOCAL_IP}:${FW_PORT}:${FW_LOCAL_IP}:${FW_PORT_INTERMED} \
ssh ${MASTER_IP} -l ${MASTER_USER} -tt \
-L ${FW_LOCAL_IP}:${FW_PORT_INTERMED}:${FW_LOCAL_IP}:${FW_PORT} \
/bin/bash
# 'echo "Tunnel is open. Disconnect from this SSH session to close the tunnel and remove NAT rules" ; bash'
sudo iptables -t nat -D ${FW_RULE}
And ofc copy control plane's ~/.kube to your lappy :)3 -
This is probably the worst place to start my Rant saga but this is recent (this is one of the last few episodes of a 3 series cluster fuck of a job so you're missing out on all the straws that go into breaking the camels back and making him unaccommodating)
TL;DR I do good work, management dont like me and go out their way to try and fuck up my days
So, lets start, I'm a contractor, got funeral Tuesday, book leave, book WFH for day after.
I leave in 3 weeks, woman who is the CIO's right hand bitch takes me into a room the next day or so in the morning to discuss my WFH day. Leave on tuesday is cool but this WFH day...there's only so long until I'm gone so they want me to stay in for more face-to-face time blah blah blah (considering this woman isn't even part of the project I'm working on anymore because she decided to deflect it onto a underqualified junior with no PM experience)
So I sit there, thinking of all the blood and sweat that I have shed, the mountains I've moved just to be told to move the mountain somewhere else and whether coming in would kill me (in other words im fucking burnt out!!! I have built their GDPR database and app backend single-handedly with no requirements, project managers who can't plan and being chastised for asking for documentation/plan/anything written down and having the CIO who is also the fucking DPO ignore any emails/slack I send him relating to the project and having to keep up with a team of devs....).
So because there was a momentary silence, she decided to fill the gap
"Oh, you've done some good work so far and I wouldn't want you to ruin it all in these last 3 weeks. So just come in on the Wednesday so that we can have you here."
Hmm....yeah...i didn't notice what she had ACTUALLY said there, still thinking about can i be fucked? So she decides to add
"...there's only 3 weeks left, wouldn't want you to burn any bridges. Remember, we still have to give you a reference"
....Okay....shots fired. So i respond
"You saying, if I take a WFH day, you'll give me a bad reference?"
"Noooo no no no, not saying that, just that you've done good work and we wouldn't want you to ruin it"
"With one wfh day?"
"We just want you to come in because the developers might be coming here that week"
"Oh... I hear that...what day?"
"I dunno, it's not been booked yet"
".............................I'll think about it"
"There's nothing to consider"
*Start leaving room* "I'll think about it...."
So cool, obviously, had a think, decide to shoot over an email (or more accurately, a collection of bullets). Which basically said, in devRant translation, "Fuck y'all, I'm WFH on that day, I wish a motherfucker would fuck up my reference, we can go that way if you want it. *snaps fingers* I. WISH. YOU. WOULD! "
Woman says "I wasn't threatening you, was just saying...dont ruin your last 3 weeks, wouldn't want you to burn any bridges and that we still have to give you a reference"
What kind of Godfather comment is that?
Come in today, the CIO, who is a prick who don't like me for whatever reason, sends me long email trying to disrespect me and in the midst says "I’m sorry that you have chosen to react like this, I’m sure that [my bitch] was conveying a position that your last three weeks of contract are crucial for a smooth handover. I have made the decision to not require you to work from home on Wednesday. I understand you are on leave on Tuesday and therefore this is now extended to include Wednesday. I look forward to seeing you back in the office on Thursday. I hope this will make the situation better for all parties."
.................................thought you lot needed me in the office to ensure a smooth handover................logic..........people.............where the fuck do you get yours from!?!?!?!? All this just so they can say "We made the decision at the end :cool:" -
Announcing Covey (v0.1)!
A lightweight (or at least that's the goal) Linux cluster orchestration/management system.
https://github.com/chaabd360/covey
Why?
Because there are no systems with a (web) GUI (that I could find) that can run on a Raspberry Pi or similar.
This doesn't have a GUI!
It's coming in the next week or so (hopefully).
The codebase is shit!
I know, I'm actively refactoring it (feel free to send a PR).
What is it written in?
Go, with Postgres as the database.
Can I use it?
Go ahead and try, it's currently more in the MVP stage then at the stage where I recommend you use it.
Do you know what you're doing?
Maybe... This is my first big project in Go, and the first time I've ever used SQL. So I'm learning as I go along.8 -
The concept and execution of inter-cluster SSL along with keystores, truststores, signing, and similar just clicked in my head today. I feel the burden of undiagnosable https errors just melt off my shoulders. Any other environment tips I should know for kubernetes?
-
What CI software are you using?
Are you happy with it or what do you hate about it.
I tried 5 different CI platforms in the past week, and I did not like any of them..
Any recommendations? (Can also be self hosted, I have a k8s cluster at my disposal)
// a short rant about team city
wE uSe koTliN dSL to reduce how much configuration is needed, fuck you I ended up with even more, it's horrible I have 40+ micro services, meta runners sounded like a awesome feature until I found out you need to define one for ever single fucking project...
Oh and on top of that, you cannot use one from root parent, but also it cannot be named the same.
Why is all ci software just so retarded - sorry I really cannot put it any other way10 -
Parsing logs to create conditional insert statements cause expert morons fucked up production database cluster.
Database is partially corrupted and cannot be used and they don’t know how to fix it.2 -
Make your code available for your team members, please.
So we're working on this robotics project using ROS, a framework that enables multiple nodes in a network exchange their functionality among each other through tcp connections. Each node can be implemented and executed on your own machine, and tested with dummy inputs, but in collaboration they make a robot do fancy stuff.
The knowledgebase needs data from the image processing unit, providing this data to others with semantic context to high level planning, which uses this semantic data for decision making and calling the robot manipulation node with meaningful input, to navigate the robot's components in the environment. We use a dedicated machine, which pulls the corresponding repositories and is always kept configured correctly, to run each node, such that everybody has access to each other's work when needed.
So far so good. We tried to convince the manipulation guy (let's call him John) to run his code on our central machine, not a week, but since the first day, 5 months ago. Our cluster classification has been unavailable for 2 months, but my collegue fixed that. We still can't run the whole project without John's computer. If his machine blows up we're fucked.
Each milestone feels like a big-bang-test, fixing issues in interfaces last-minute. We see the whole demo just moments before our supervisors arrive at the door.
I just hope he doesn't get hit by a truck.2 -
A very long rant.. but I'm looking to share some experiences, maybe a different perspective.. huge changes at the company.
So my company is starting our microservices journey (we have a 359 retail websites at this moment)
First question was: What to build first?
The first thing we had to do was to decide what we wanted to build as our first microservice. We went looking for a microservice that can be used read only, consumers could easily implement without overhauling production software and is isolated from other processes.
We’ve ended up with building a catalog service as our first microservice. That catalog service provides consumers of the microservice information of our catalog and its most essential information about items in the catalog.
By starting with building the catalog service the team could focus on building the microservice without any time pressure. The initial functionalities of the catalog service were being created to replace existing functionality which were working fine.
Because we choose such an isolated functionality we were able to introduce the new catalog service into production step by step. Instead of replacing the search functionality of the webshops using a big-bang approach, we choose A/B split testing to measure our changes and gradually increase the load of the microservice.
Next step: Choosing a datastore
The search engine that was in production when we started this project was making user of Solr. Due to the use of Lucene it was performing very well as a search engine, but from engineering perspective it lacked some functionalities. It came short if you wanted to run it in a cluster environment, configuring it was hard and not user friendly and last but not least, development of Solr seemed to be grinded to a halt.
Elasticsearch started entering the scene as a competitor for Solr and brought interesting features. Still using Lucene, which we were happy with, it was build with clustering in mind and being provided out of the box. Managing Elasticsearch was easy since there are REST APIs for configuration and as a fallback there are YAML configurations available.
We decided to use Elasticsearch since it provides us the strengths and capabilities of Lucene with the added joy of easy configuration, clustering and a lively community driving the project.
Even bigger challenge? Which programming language will we use
The team responsible for developing this first microservice consists out of a group web developers. So when looking for a programming language for the microservice, we went searching for a language close to their hearts and expertise. At that time a typical web developer at least had knowledge of PHP and Javascript.
What we’ve noticed during researching various languages is that almost all actions done by the catalog service will boil down to the following paradigm:
- Execute a HTTP call to fetch some JSON
- Transform JSON to a desired output
- Respond with the transformed JSON
Actions that easily can be done in a parallel and asynchronous manner and mainly consists out of transforming JSON from the source to a desired output. The programming language used for the catalog service should hold strong qualifications for those kind of actions.
Another thing to notice is that some functionalities that will be built using the catalog service will result into a high level of concurrent requests. For example the type-ahead functionality will trigger several requests to the catalog service per usage of a user.
To us, PHP and .NET at that time weren’t sufficient enough to us for building the catalog service based on the requirements we’ve set. Eventually we’ve decided to use Node.js which is better suited for the things we are looking for as described earlier. Node.js provides a non-blocking I/O model and being event driven helps us developing a high performance microservice.
The leap to start programming Node.js is relatively small since it basically is Javascript. A language that is familiar for the developers around that time. While Node.js is displaying some new concepts it is relatively easy for a developer to start using it.
The beauty of microservices and the isolation it provides, is that you can choose the best tool for that particular microservice. Not all microservices will be developed using Node.js and Elasticsearch. All kinds of combinations might arise and this is what makes the microservices architecture so flexible.
Even when Node.js or Elasticsearch turns out to be a bad choice for the catalog service it is relatively easy to switch that choice for magic ‘X’ or component ‘Z’. By focussing on creating a solid API the components that are driving that API don’t matter that much. It should do what you ask of it and when it is lacking you just replace it.
Many more headaches to come later this year ;)3 -
I like the people I work with although they are very shit, I get paid a lot and I mostly enjoy the company but..
Our scrum implementation is incredibly fucked so much so that it is not even close to scrum but our scrum master doesn't know scrum and no one else cares so we do everything fucked.
Our prs are roughly 60 file hangers at a time, we only complete 50% of our work each sprint because the stories are so fucked up, we have no testers at all, team lead insists on creating sql table designs but doesn't understand normalisation so our tables often hold 3 or 4 sets of data types just jammed in.
Our software sits broken for months on end until someone notices (pre release), our architecture is garbage or practically non existent. Our front end apps that only I know the technology have approaches dictated by team lead that has no clue of the language or framework.
Our front end app is now about 50% tech debt because project management is so ineffectual and approaches are constantly changing. For instance we used to use view models for domain transfer objects... Now we use database entities, so there is no commonality between models but the system used to have shared features relying on that..sour roles and permissions are fucked since a role is a page regardless of the pages functionality so there is no ability to toggle features, but even though I know the design is fucked I still had to implement after hours of trying to convince team lead of it. Fast forward a few months and it's a huge cluster fuck to enforce.
We have no automated testing of any sort or manual testing in place.
I know of a few security vulnerabilities I can nuke our databases with but it got ignored.
Pr reviews are obviously a nightmare since they're so big.
I just tried to talk to scrum master again about story creation since any story involving front end ui as an aspect of it is crammed in under one pointed story as sub tasks, essentially throwing away any ability to calculate velocity. Been here a year now and the scrum master doesn't know what I mean by velocity... Her entire job is scrum master.
So anyway I am thinking about leaving because I like being a developer and it is slowly making me give up on doing things to a high standard and I have no chance of improving things, but at the same time the pay is great and I like the people. -
I hate the elasticsearch backup api.
From beginning to end it's an painful experience.
I try to explain it, but I don't think I will be able to cover it all.
The core concept is:
- repository (storage for snapshots)
- snapshots (actual backup)
The first design flaw is that every backup in an repository is incremental. ES creates an incremental filesystem tree.
Some reasons why this is a bad idea:
- deletion of (older) backups is slow, as newer backups need to be checked for integrity
- you simply have to trust ES that it does the right thing (given the bugs it has... It seems like a very bad idea TM)
- you have no possibility of verification of snapshots
Workaround... Create many repositories as each new repository forces an full backup.........
The second thing: ES scales. Many nodes / es instances form a cluster.
Usually backup APIs incorporate these in their design. ES does not.
If an index spans 12 nodes and u use an network storage, yes: a maximum of 12 nodes will open an eg NFS connection and start backuping.
It might sound not so bad with 12 nodes and one index...
But it get's pretty bad with 100s of indexes and several dozen nodes...
And there is no real limiting in ES. You can plug a few holes, but all in all, when you don't plan carefully your backups, you'll get a pretty f*cked up network congestion.
So traffic shaping must be manually added. Yay...
The last thing is the API itself.
It's a... very fragile thing.
Especially in older ES releases, the documentation is like handing you a flex instead of toilet paper for a wipe.
Documentation != API != Reality.
Especially the fault handling left me more than once speechless...
Eg:
/_snapshot/storage/backup
gives you a state PARTIAL
/_snapshot/storage/backup/_status
gives you a state SUCCESS
Why? The first one is blocking and refers to the backup status itself. The second one shouldn't be blocking and refers to the backup operation.
And yes. The backup operation state is SUCCESS, while the backup state might be PARTIAL (hence no full backup was made, there were errors).
So we have now an additional API that we query that then wraps the API of elasticsearch. With all these shiny scary workarounds like polling, since some APIs are blocking which might lead to a gateway timeout...
Gateway timeout? Yes. Since some operations can run a LONG (multiple hours) time and you don't want to have a ton of open connections hogging resources... You let the loadbalancer kill it. Most operations simply run in ES in the background, while the connection was killed.
So much joy and fun, isn't it?
Now add the latest SMR scandal and a few faulty (as in SMR instead of CMD) hdds in a hundred terabyte ZFS pool and you'll get my frustration level.
PS: The cluster has several dozen terabyte and a lot od nodes. If you have good advice, you're welcome - but please think carefully about this fact.
I might have accidentially vaporized people sending me links with solutions that don't work on large scale TM.2 -
Things I say to my clients when I know that a reboot is required to fix their issue but I don't have enough evidence to prove it to them :
"... On any computing platform, we noted that the only solution to infinite loops (and similar behaviors) under cooperative preemption is to reboot the machine. While you may scoff at this hack, researchers have shown that reboot (or in general, starting over some piece of software) can be a hugely useful tool in building robust systems.
Specifically, reboot is useful because it moves software back to a known and likely more tested state. Reboots also reclaim stale or leaked resources (e.g., memory) which may otherwise be hard to handle. Finally, reboots are easy to automate. For all of these reasons, it is not uncommon in large-scale cluster Internet services for system management software to periodically reboot sets of machines in order to reset them and thus obtain the advantages listed above.
Thus, when you indeed perform a reboot, you are not just enacting some ugly hack. Rather, you are using a time-tested approach to improving the behavior of a computer system."
😎1 -
FOMO on technology is very frustrating.
i have a few freelance and hobby projects i maintain. mostly small laravel websites, go apis, etc ..
i used to get a 24$/ month droplet from digital ocean that has 4vCPUs and 8GB RAM
it was nore than enough for everything i did.
but from time to time i get a few potential clients that want huge infrastructure work on kubernetes with monitoring stacks etc...
and i dont feel capable because i am not using this on the daily, i haven't managed a full platform with monitoring and everything on k8s.
sure u can practice on minikube but u wont get to be exposed to the tiny details that come when deploying actual websites and trying to setup workflows and all that. from managing secrets to grafana and loki and Prometheus and all those.
so i ended up getting a k8s cluster on DO, and im paying 100$ a month for it and moving everything to it.
but what i hate is im paying out of pocket, and everything just requires so much resources!!!!3 -
imagine the guys in the datacenter are switching out power distribution units - and suddenly your productive database cluster reboots :)1
-
So today my teacher told me to do that project for some competition or something(frankly, I don't remember clearly what this is for). He gave us the machines we need, the CDs with the systems we have to work with. We are supposed to make a properly working Beowulf cluster from the things I've been given.
Well, no.
Fucking no.
I am really okay with making this the way my teacher wants us to do. I am okay with installing an ubuntu 16.04 server that is completly irrevelant to the project, because it's not part of the cluster. I am really okay with using some weird linux distribution on the master nobody has ever heard of. But I'm not okay when the software we've been given(including operating system) has seven pages of documentation, escpecially when fucking screenshoots of how PXE booting should look like are roughly 70% of it. No, I couldn't find a thing on the internet about it. I couldn't read the fucking manual. There was no fucking manual. There was no fucking --help. There was no motherfucking english language. Everything was motherfucking spanish, including that 7 pages long document that was supposed to guide us through our work. It was planned to be done until march. The only reason I can think of about why doing the stuff the document tells us to do would take four motherfucking months is that we'd have to learn spanish to do this. And I'm not going to do that. Not because I don't like spanish or learning. Simply because I didn't sign up for this to learn languages.
And no. I can't switch to other, human purposed software. I am only allowed to use the things the teacher has given us. Because somebody has worked on it already couple of years ago and they had left a pdf file about how to install that ubuntu server I've been writing about a while ago. Which, by the way, was the "installation guide for animals". Showing how to install a system, screenshoot after screenshot.
It took about an hour to figure out the thing supposed to handle pxe booting computers all the time was telling us that it can't work because we had to configure ethernet interface manually. Because why the fuck not.
-
And here we go, at least tell me outright that you want to farm data on how dry you can milk my cluster of personas, assholes...
 1
1 -
I'm not sure whats saddest that'll likely be doing gdpr for another two months. Or that the pm thinks we'll be ready by the deadline.3
-
AWS ECS UI wasn't designed for machines or humans.
Created a task/service/cluster with default suggested Roles.
Service task fails to get image from ECR repository using the said permissions suggested in the docs defined in the default roles.
You only had one job. 😠
How not GTD. -
AMQ cluster is misbehaving.. Master is constantly dying, slave is starting under root rather than app account, connection to AMQ DB takes 20-40 seconds (while queries execute in <0.1sec and TCP probe takes <0.01sec to succeed), monitoring is down,...
I mean it's gotta be the virus - what else could it be.2 -
Any idea to get around the cluster storage limitation?
I have to train a model on a large dataset, but the limit I have is about 39GB. There is space on my local disk but I don't know if I can store the data on my computer and have the model train on the cluster resources.1 -
Spend all day debugging simple post request. Like really what is going on. Super simple. Eyes start to bleed. Check spelling on everything. Finally find out the access-control-origin isn't set right, other dev said it was whatever so glad I'm moving on. Nope. Same error running the app from Visual Studio. Check code again. Everything works in a browser. Windows, VS, or the emulator is blocking just POST requests. I can do get requests all day.
What hell. I'm so critical of my code I spend hours pouring over something I knew was right instead of looking for network errors. I just need to trust myself I guess.
Oh and Windows Cordova apps don't support ES6 lol.1 -
Amazon what the hell.
You provide a cool RDS proxy which can be used to manage connection pooling which is especially useful for concurrent Lambda invocations.
But if you have an Aurora cluster and a read-intensive workload it is basically useless because it only sends traffic to the writer instance.
WTF?! Literally the one use case we have is the one thing it doesn’t do. AAARRRGGHHHH2 -
It was fckin mythic for me, that friday deployments etc. So we got SRE for a while and he is working sometimes with us when we can't figure something out, and thats all, all the other devops stuff is up to us - precisely me. So our kubernetes cluster decided to fuck up and guess who is sitting on friday evening fixing this crap.
Shit.1 -
Learning Pulumi with Python. Not a fan of Py, but I know my way around.
There's a dev cluster. My colleague asked me to modify Pulumi scripts for cost optimization, as the project transitioned to maintenance mode and is no longer needed on daily basis. Since I'm learning, he asked me laughing not to delete/change the static IP and not to delete the cluster.
I'm currently recreating the cluster anew for the third time :)
Gotta say, destroying a cluster is only scary the first time.4 -
It took me 48 hours ( not continuously) to fix a bug by going through a cluster fuck code of multiple modules. Tracing the error through 5 or 6 layers. And u dont get error logs right away. You need to recreate that error and see the logs on a kubernetes pod. Just to find out the bug was a duplicate.
Yes jokes are on me. I fucked up by not checking for duplicate. I steered right away on that shit dipped bug like a hungry/zombie hound. Fuck me. -
My most hated term BY FAR is "In theory". It's a lousy-ass, weak excuse for not doing shit properly while distancing yourself from the problem. Short guide: "in theory" may be used prior to or following a statement in which you have little or no confidence in.
The web server shouldn't reach the database server "in theory", it fucking does or doesn't. The SQL cluster shouldn't "in theory" fail over to a working server in case of a hardware fault. Fuck off with your irresponsibility, man up and do things properly. This is the real world, not a sandbox for your shitty dorm room code1 -
when the internal documentation examples are a connection to an unmaintained cluster
not a single person along the way could've made the default example to the cluster most people will want? its the only other cluster out of the 2 -
Storytime.
Our prometheus node, one of your oldest systems (somehow fits the Titan reference..), is about to be relieved of its duties after several years of loyal services to the crew.
We decided to run with another Prometheus node in the ring, that will run simultaneously with the old one, so that the new one can start to collect metrics that we need for alerting (some historic metrics are needed too..). sort of an Prometheus cluster, without the cluster fun and with 2 different Prometheus versions.
The problems with this? Well it's not the new node or the latest shit versions of Prometheus per se.
1: The node exporter.
those dudes decided to make some breaking changes in a minor update, so that you will need to run with some magic bullshittery, that the latest Prometheus can make something out of the old metrics provided by the old node exporters.
The other one is the related puppet code.
The node definitions for Prometheus were built via exported resources on the target nodes.
The code worked like a charm with only one Prometheus node, but try that with two instances in the same way.
Still WIP, but some targets are already included in the new Prometheus instance.
alerting works so far.
Can't wait to close this ticket for good.. -
Recently I've been tasked with setting up of a small /mid-size infrastructure and I've been documenting things like infrastructure design, network configuration all the way to playbooks and cluster configuration.
Since I just started with this, until now I have been doing this in a Google doc / some spread around markdown files. I would like to have a better way of having this documentation hosted internally..
I have been playing around with local installations of rtd, gitbook and mkdocs. So far, I've liked the simplicity and customizability of mkdocs.
Any other options before I commit myself to mkdocs?2 -
So today I have to get ready for the biggest competition in my life (competition is Tommorow).Its an annual competition for University undergrads where I have to build a cluster(hardware) and install the software eg(openmpi,zabbix,hpcc,hpl and some other benchmark programs) and then run the benchmarks in the hope of getting higher scores with a budget they give.i have a team of 3 other talented individuals.i hope.i do well there.
https://mybroadband.co.za/news/...2 -
Not a rant, but does anyone know of good cluster computing software for Windows? Can't find any on google2
-
I had a discussion - no, it was more a lobotomy - with one of our "experts"
I was kinda confused, as he had several grafana tabs open and an query editor...
He explained to me that he debugs and optimizes his query based on the grafana data....
Elasticsearch cluster with several hundred, different indices, > 20 TB data
I explained to him the scrape interval of 5secs, that he cannot distinguish his query from other queries, that there is far too much of an interference... Let alone that a 5 sec scrape interval is a very loooong time.....
Nope. It makes perfect sense to him and he'll continue to work like this. -
This week I am finishing my brand new and probably buggy cluster manager for vert.x based on redis.
Can't wait to start battle testing.1 -
Getting Cluster Container Servers running with a static NFS Server in the Background.
This could be called "clusterfuck", cause my mind was fucked. -
Do you ever feel your job is too demanding compared to other software engineering jobs?
I've worked in two companies for now.
First company, Kotlin microservices and we had QAs, didn't have to write a lot of tech specs and no post mortem or on call at all (not yet atleast), it was just talk to PO, he tells the business requirement, we work together to make tickets, no legacy code so was easy to know what to do for tech, no monolith to handle or anything, much easier, just code and meetings.
Current job is meetings with PO telling you what he wants, have to write a full on tech spec and also know business requirements and product knowledge as the current PO doesn't know anything about how the products work, writing huge tech specs, communicating on requests sent my clients on slack, pretty much always firefighting, the system is so fragile and legacy, coding is actually less its mostly spending hours finding out how this shittt legacy flows work (no docs) , PO pretty much does fuck all, just wants meetings and wants us to do very very stupid tedious low impacts projects. This bundled with oncall and onpoint and the absolute sheer amount of incidents our team is involved in (on average we have 4 a week LOL, varying size but they're all very annoying) and the overtime oncall benefit is so bad too, if you do get paged out of hours, you just get that hour back during work hours. In other companies like friends, you get paid for the whole time you're oncall, whether you get paged or not. I can't go out anywhere on weekends or anywhere at all during on call in case I get paged, which happens a lot. Its a cluster of a mess. This bundled with manager stoll not wanting to promote me to IC3 despite all I've done so far.
My question is, is this more normal than I think it is? Is this just how crap our career can be? Mind you I'm in the UK so not getting those mind boggling US wages sadly either. Have US colleagues in same team doing same job but obviously getting more11 -
Whats the fucking purpose of our companys dev test and prod env. Dev always only has a single instance. Sometimes clustered services run as cluster on test. Producing headaches because the clustering behaviour couldnt be seen on a single instance and Prod lacks all the nice deployment tools off dev/test. Fuck thinking you could dev then test and prod without any major reconfiguration and headaches. And all because the Storage costs is RETARDEDLY expensive because the backup EVERYTHING with ridiculess overkill. That results in headaches when requesting new servers. Took an old Workstation from the shelves and made it my vm slave so at least i could reliably deploy to test.. Fuck this process
-
Using AWS DocumentDB elastic cluster for a sharded managed MongoDB
It's ass is so heavy!! More than 15min for scaling 2 -> 3 shards!
Am I taking a bad decision?7 -
Chinese remainder theorem
So the idea is that a partial or zero knowledge proof is used for not just encryption but also for a sort of distributed ledger or proof-of-membership, in addition to being used to add new members where additional layers of distributive proofs are at it, so that rollbacks can be performed on a network to remove members or revoke content.
Data is NOT automatically distributed throughout a network, rather sharing is the equivalent of replicating and syncing data to your instance.
Therefore if you don't like something on a network or think it's a liability (hate speech for the left, violent content for the right for example), the degree to which it is not shared is the degree to which it is censored.
By automatically not showing images posted by people you're subscribed to or following, infiltrators or state level actors who post things like calls to terrorism or csam to open platforms in order to justify shutting down platforms they don't control, are cut off at the knees. Their may also be a case for tools built on AI that automatically determine if something like a thumbnail should be censored or give the user an NSFW warning before clicking a link that may appear innocuous but is actually malicious.
Server nodes may be virtual in that they are merely a graph of people connected in a group by each person in the group having a piece of a shared key.
Because Chinese remainder theorem only requires a subset of all the info in the original key it also Acts as a voting mechanism to decide whether a piece of content is allowed to be synced to an entire group or remain permanently.
Data that hasn't been verified yet may go into a case for a given cluster of users who are mutually subscribed or following in a small world graph, but at the same time it doesn't get shared out of that subgraph in may expire if enough users don't hit a like button or a retain button or a share or "verify" button.
The algorithm here then is no algorithm at all but merely the natural association process between people and their likes and dislikes directly affecting the outcome of what they see via that process of association to begin with.
We can even go so far as to dog food content that's already been synced to a graph into evolutions of the existing key such that the retention of new generations of key, dependent on the previous key, also act as a store of the data that's been synced to the members of the node.
Therefore remember that continually post content that doesn't get verified slowly falls out of the node such that eventually their content becomes merely temporary in the cases or index of the node members, driving index and node subgraph membership in an organic and natural process based purely on affiliation and identification.
Here I've sort of butchered the idea of the Chinese remainder theorem in shoehorned it into the idea of zero knowledge proofs but you can see where I'm going with this if you squint at the idea mentally and look at it at just the right angle.
The big idea was to remove the influence of centralized algorithms to begin with, and implement mechanisms such that third-party organizations that exist to discredit or shut down small platforms are hindered by the design of the platform itself.
I think if you look over the ideas here you'll see that's what the general design thrust achieves or could achieve if implemented into a platform.
The addition of indexes in a node or "server" or "room" (being a set of users mutually subscribed to a particular tag or topic or each other), where the index is an index of text audio videos and other media including user posts that are available on the given node, in the index being titled but blind links (no pictures/media, or media verified as safe through an automatic tool) would also be useful.9 -
Can we make a cluster which is moderately powerful using all free cloud computing services available online like Google Cloud Platform, AWS, Oracle cloud, Microsoft Azure etc.3
-
TL;DR I have to bump a Redis cluster from t3.medium to m6g.large just to get enough network bandwidth even though I have no need of the extra memory.
Debugged an interesting issue today.
I am adding Elasticache to a project to reduce strain on the single node postgres DB.
Deployed a Redis replication group with 2 shards, with multi-AZ replication for resilience.
Everything was going well. We arent caching that much atm so was barely using 100Mb of memory.
Suddenly, when our US region comes online, latency skyrockets and the logs are full of Jedis timeout errors.
Still no issue with memory or node CPU.
The cause? Arbitrary network bandwidth throttling by AWS. The app currently processes about 3,000 requests per second so we were exceeding Amazons random ass allowances which arent documented anywhere.1 -
So I have a raspberry pi running nextcloud and I want to add a second one to improve the availability.
I'm new to HA clusters. What stack would you recommend?17 -
Dear Mongodb, I created the clusters in your service because you created Mongodb. I also subscribed to the "Premium" to get better service.
I get it, my card didn't have enough balance for the last 3 months but you could just convert my account to "Free".
How could you delete the cluster? You morons deleted all the data of my app of 1.5 years. You even deleted all the backups! WTF!
What's the point of buying premium service if that makes you lose the data? Fuck you!6 -
Why does Microsoft make entity migration default and every tutorial show them? I have other ways of migrating my db schema changed. Newbies come to me with this cluster already in motion and I have to help straighten it out. Then the newbie says "why do all the tutorials show it". I say because the people making the tutorials are trying to quickly create content for a tutorial.
-
I just found out i've wasted month of my life by troubleshooting wrong component.
I was unable to access my application in cluster and suspected networking and port configuration. (custom corporate setup with chaotic documentation did not help to situation)
In the end, it was caused by Jenkins, which failed on building a new container but still showed "build: success" while it deployed May version of container without any changes applied. -
How useful is my degree? I'm not sure to be honest. I did get to dive into a lot of subject matter which I find interesting and challenging. I also had to learn stuff I hate (solving matrices of differential equations). Strangely though, even though I doubt I will ever use this I am proud of myself for having slugged though it.
The teachers were helpful and supportive, I got to study in groups and had access to resources such as the university's GPU cluster.
In my day2day? So far, I cannot see anything I use directly. However, the university forced me to learn to pick up different technologies quickly, read the documentation, ask for help when your don't understand something. So, in that regard I think I profited from university.
I wasn't the best student by a long shot. My class mates helped me a lot. I struggled A LOT. Having been in the recieving end of a helping hand, o return the favour where ever I can. -
Guessing my rant free streak is over. Trying to connect to a mongo atlas cluster. Just migrated from mlab as mongo Inc is discontinuing the heroku add on.
Migration went well. I can connect to atlas cluster via mongo shell.
Reactive mongo claims it supports dns seed list. I add mongodb+srv connection string. Doesn't work.
I go back to atlas and allow all ips access (migrating staging dB first to make sure all is well so I can whitelist all ips) - > send a request-> mongo error. No primary node is available.
Disconnect from my network, connect to another network, same thing. I push the connection string to my server, test using an ssl connection to make a request, still no primary node available. I am about to lose my mind. -
What do you guys think about deploying elastic search on App Engine Custom Runtime?
(Basically, an empty folder with an elastic search Dockerfile.)
I think it's a good idea: you can now deploy your code and storage application (Elastic search, Redis, etc) as services on your cluster.
You can use GCP magic to auto scale those services, you have so many good stuff that come with it.
And it's inside the same network as your services running in the same AppEngine project.1 -
FUCK.... FUCK THE FUCK
When I test my app everything works
When someone tests SHIT doesn't work on signing up user
WTF !!!!!
if you have the time try registering
Info doesn't hve to be legit
Just make sure password is >= 4 characters
https://lenode.herokuapp.com5 -
Best book/source for learning everything devops'y'/kubernetes?
(Given that I have some sort of experience in Dockers, hosting websites and know a fracture of aws archeticture, but lack in good "cloud" thinking skills, scalability, understanding costs for production applications, cluster size, etc...) -
Learning to like manjaro, a lot, setting up i3 for a workstation and kubernetes cluster with a couple of manjaro workstations with just the cli installed... few gotchas on the way, get Hyper-V enhanced mode working but get a message session error on dbus launch - easy fix it is already launched by lightdm, the cli install doesn't start the network driver by default but can get a whole 3 node k8s cluster running in under an hour from scratch and forward i3 to a nice, fast, little windows x-server that I got for free with Microsoft reward points.. winning!
-
I’m picturing some giant over mind
A huge cluster of computers and what is actually happening to explain the theft and stupidity that makes
The world seem like the last scene
In the movie repo
Men is they’re feeding their hungry growing baby all the pilfered videos and pictures they can and the brain was designed to be a piece of garbage like them with no regard for human life
Yep
That seems about right
Something from a sci-fi horror film mixed with the plot of that movie where all the humans were inbred morons in the future4 -
Any ideas how to skill up devops ? Currently in company im doing simple things with kubernetes, aws, terraform and circleci, and the whole idea click to create your inba cluster is interesting, smells like a few steps from cybersecurity!
Soo i decided to write an app, with two environments, which are staging and prod, configure some ci pipeline, kubernetes deployments and terraform, everything with usage of aws, and then when i will be okay with it, send cv's as devops and change career path.
Seems legit or waste of time ?2 -
Hazelcast
Works great, until it doesn't because of network partitions. Then your cluster needs restarting. -
I’m trying to add caching functionality in my scalable spark cluster on Docker. I am able to add redis to my Docker container, but that doesn’t add redis-CLI or any other useful tools that I need. And there are some redis-cache projects on PyPi, but they are very old and not compatible with python3.5
-
Finally have my DCOS cluster running! On paper this should be amazing. But I have now figured out that the front end Devs have about 400 uncommitted HTML templates, which means I cannot proceed with out severe chaos! I spend so much time creating an awesome data centre, only to be thwarted by other peoples laziness!
 4
4 -
How can it be a galera cluster with three DB servers (running in docker) is slower than a single docker container with mariadb under the same load?5
-
Anybody got experience with Rancher (https://rancher.com) on Ubuntu?
Checked it out and it looks really well made. You can build a Cluster in Minutes and mount a phyisical storage to it.
Im planning to drop a Full Stack Root Server with it and would be really glad to hear on your opinions 😁3 -
So I was very bored this week and deceided to get my head wrapped around Kubernetes and the hype around it. After trying to get a cluster run on my old contano servers I almost lose my nerve and just went for DigitalOcean. Holy shit I am impressed by the service. 30 seconds TTL DNS, hourly rate billing and spinning a scaleable cluster in only minutes. I fell in love1
-
If anyone is looking for a great tutorial on getting started with a docker cluster check out https://dockerswarm.rocks/
I had a 4 node cluster up on Digital Ocean with Traefik + Lets Encrypt, Prometheus, Portainer, Grafana all that good stuff in under 2 hours. Not much longer to test a basic WP and Next Cloud container with full SSL. Neat stuff. Just burning through $100 credit for testing but it's been fun5 -
wanted to set up a k3s cluster with my pi's. took me a fucking whole day to find useful ansible playbooks (which I needed to fix because outdated).
I want to habe metallb and nginx ingress running, so that differs from the default.
and now i spent the whole day trying to install a fucking pi hole and for some reason metallb does not fart out an external ip for the pi hole.
found several issues regarding this matter.
maaaan i am completely new to this whole clusterfuck and i feel a bit overwhelmed atm. i thought this would be easier. am i just an idiot?8 -
Debugging Spark errors is frustrating. Been running a model which takes an hour only to come across errors. And it's not even related to my code. Something to do with the cluster. FML1
-
For a Node API is there a difference between starting cluster mode using a PM2 vs calling cluster.fork() inside the first instance?
I have some apps that create the cluster internally and others via PM2 but I don't know why or why it makes a difference... Other than the cluster processes not showing up in pm2 list1 -
Sophomore year starting soon so I'm looking for new project (s) to complete in parallel with the studies.
Some are more design-y and some more backend-y but I recently started getting better at designing so :)
1) Learn some fragment shader stuff. I've always been messing around with graphics and have a game on steam, so I think that's a good idea to be paired with signal processing.
2) Reactive web services. Preferably with spring-boot or vert.x but
3) I would also like to dive into golang (and make some reactive thing with it)
4) WebAssembly seems nice... But I got some concerns
5) exercise making wireframes -> CSS (with some js)
6) I've never really done any real backed work with nodejs, except serving and aot compiling js, or doing gulp tasks
7) Implementing a whole project, or a fraction of it as serverless on aws
* I'm definitely going to use a couple very simple services to make a docker swarm with load balancing, etc, just because I know how everything works but got no practical knowledge
8) Design an esports jersey for the university department I'm in (shouldn't take long)
So what do you guys think? Recommendations are welcome :)
P.S. last year in review:
> A webapp running on a raspberry pi powering a reflex testing game on gpio (java/spring-boot , codename: buttonmasher)
> small Elastic search cluster to monitor some random university servers through kibana dashboards
> laser tracking on wall of *any* colour and variable light conditions via a webcam (opencv) , controlling the mouse pointer, whether you run it against a projector or any wall
> jstrain.herokuapp.com => a small JavaScript powered tool with a DSL to help you train more efficiently without a coach
> Various random Photoshop stuff -
So on my new position I get to work on Spark jobs. Never had to work with the infamous big data technologies. I never thought this would get SO frustrating for all the wrong reasons.
I'm currently trying to introduce integration tests for some Spark job I wrote. This isn't trivial though, as the data comes from several HBase tables. Mocking everything simply isn't feasible. So why not use the integrated HBaseTestingUtility? With it you can start a mini cluster that runs all nessecary services in the scope of your test.
Sounds great, eh? WRONG. Firstly the used mapr dependencies get in the way. The baked in configuration tries to automatically authenticate with your local cluster through Kerberos. Of course this doesn't work. And of course there is no way to reconfigure this as it happens IN A FUCKING STATIC BLOCK. AHHHH.
Ok. So after calming down I "simply" had to exclude all mapr dependencies and replace them with vanilla ones. After two days of dependency hell it FINALLY works!
...or does it? Well now we need test data. For that we got a map reduce algorithm that can import dumps. Sounds again, great, eh? WROOOONNNG.
The fucking map reduce mini cluster can't start, as it tries to write a symlink. Now take a wild guess what the sys admin here blocked. Yepp. TWO DAYS OF WORK RENDERED USELESS, BECAUSE OF SOME FUCKING SECURITY SETTING.
This is fine. -
who ever developed a cluster fuck of this platform called zoho cliq
fuck you!!!!!!
the mobile app doesn't even login -
It started with a gut-wrenching realization. I’d been duped. Months earlier, I’d poured $133,000 into what I thought was a golden opportunity a cryptocurrency investment platform promising astronomical returns. The website was sleek, the testimonials glowed, and the numbers in my account dashboard climbed steadily. I’d watched my Bitcoin grow, or so I thought, until the day I tried to withdraw it. That’s when the excuses began: “Processing delays,” “Additional verification required,” and finally, a demand for a hefty “release fee.” Then, silence. The platform vanished overnight, taking my money with it. I was left staring at a blank screen, my savings gone, and a bitter taste of shame in my mouth.I didn’t know where to turn. The police shrugged cybercrime was a black hole they couldn’t navigate. Friends offered sympathy but no solutions. I spent sleepless nights scouring forums, reading about others who’d lost everything to similar scams. That’s when I stumbled across a thread mentioning a group specializing in crypto recovery. They didn’t promise miracles, but they had a reputation for results. Desperate, I reached out.The first contact was a breath of fresh air. I sent an email explaining my situation dates, transactions, screenshots, everything I could scrape together. Within hours, I got a reply. No fluff, no false hope, just a clear request for more details and a promise to assess my case. I hesitated, wary of another scam, but something about their professionalism nudged me forward. I handed over my evidence: the wallet addresses I’d sent my Bitcoin to, the emails from the fake platform, even the login credentials I’d used before the site disappeared.The process kicked off fast. They explained that scammers often move funds through a web of wallets to obscure their tracks, but Bitcoin’s blockchain leaves a trail if you know how to follow it. That’s where their expertise came in. They had tools and know-how I couldn’t dream of, tracing the flow of my coins across the network. I didn’t understand the technical jargon hash rates, mixing services, cold wallets but I didn’t need to. They kept me in the loop with updates: “We’ve identified the initial transfer,” “The funds split here,” “We’re narrowing down the endpoints.” Hours passed , and I oscillated between hope and dread. Then came the breakthrough. They’d pinpointed where my Bitcoin had landed a cluster of wallets tied to the scammers. Some of it had been cashed out, but a chunk remained intact, sitting in a digital vault the crooks thought was untouchable. I didn’t ask too many questions about that part; I just wanted results. They pressured the right points, leveraging the blockchain evidence to freeze the wallets holding my funds before the scammers could liquidate them. Next morning, I woke up to an email that made my heart skip. “We’ve secured access to a portion of your assets.” Not all of it some had slipped through the cracks but $133,000 worth of Bitcoin, my original investment, was recoverable. They walked me through the final steps: setting up a secure wallet, verifying the transfer, watching the coins land. When I saw the balance tick up on my screen, I sat there, stunned. It was real. My money was back.The ordeal wasn’t painless. I’d lost time, sleep, and a bit of faith in humanity. But the team at Alpha Spy Nest Recovery turned a nightmare into a second chance. I’ll never forget what they did. In a world full of thieves, they were the ones who fought to make things right. Contacts below: WhatsApp: +14159714490
 1
1 -
FUCK YOU AWS Elasticsearch!!
Fucking lossing data on cluster upgrade. Fuck you! Now I have to rebuild the goddann records from Postgres database entries.
Cunt AWS ES. Screw you!



























































































































































































{kind=link}
Top Tags
Weekly Rant
View