
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
Hi, I am a Javascript apprentice. Can you help me with my project?
- Sure! What do you need?
Oh, it’s very simple, I just want to make a static webpage that shows a clock with the real time.
- Wait, why static? Why not dynamic?
I don’t know, I guess it’ll be easier.
- Well, maybe, but that’s boring, and if that’s boring you are not going to put in time, and if you’re not going to put in time, it’s going to be harder; so it’s better to start with something harder in order to make it easier.
You know that doesn’t make sense right?
- When you learn Javascript you’ll get it.
Okay, so I want to parse this date first to make the clock be universal for all the regions.
- You’re not going to do that by yourself right? You know what they say, don’t repeat yourself!
But it’s just two lines.
- Don’t reinvent the wheel!
Literally, Javascript has a built in library for t...
- One component per file!
I’m lost.
- It happens, and you’ll get lost managing your files as well. You should use Webpack or Browserify for managing your modules.
Doesn’t Javascript include that already?
- Yes, but some people still have previous versions of ECMAScript, so it wouldn’t be compatible.
What’s ECMAScript?
- Javascript
Why is it called ECMAScript then?
- It’s called both ways. Anyways, after you install Webpack to manage your modules, you still need a module and dependency manager, such as bower, or node package manager or yarn.
What does that have to do with my page?
- So you can install AngularJS.
What’s AngularJS?
- A Javascript framework that allows you to do complex stuff easily, such as two way data binding!
Oh, that’s great, so if I modify one sentence on a part of the page, it will automatically refresh the other part of the page which is related to the first one and viceversa?
- Exactly! Except two way data binding is not recommended, since you don’t want child components to edit the parent components of your app.
Then why make two way data binding in the first place?
- It’s backed up by Google. You just don’t get it do you?
I have installed AngularJS now, but it seems I have to redefine something called a... directive?
- AngularJS is old now, you should start using Angular, aka Angular 2.
But it’s the same name... wtf! Only 3 minutes have passed since we started talking, how are they in Angular 2 already?
- You mean 3.
2.
- 3.
4?
- 5.
6?
- Exactly.
Okay, I now know Angular 6.0, and use a component based architecture using only a one way data binding, I have read and started using the Design Patterns already described to solve my problem without reinventing the wheel using libraries such as lodash and D3 for a world map visualization of my clock as well as moment to parse the dates correctly. I also used ECMAScript 6 with Babel to secure backwards compatibility.
- That’s good.
Really?
- Yes, except you didn’t concatenate your html into templates that can be under a super Javascript file which can, then, be concatenated along all your Javascript files and finally be minimized in order to reduce latency. And automate all that process using Gulp while testing every single unit of your code using Jasmine or protractor or just the Angular built in unit tester.
I did.
- But did you use TypeScript?36 -
Today, I learned the shortest command which will determine if a ping from your machine can reach the Internet:
ping 1.1
This parses as 1.0.0.1, which thanks to Cloudflare, is now the IP address of an Internet-facing machine which responds to ICMP pings.
Oh, you can also use this trick to parse 10.0.0.x from `10.x` or 127.0.0.1 from `127.1`. It's just like IPv6's :: notation, except less explicit.8 -
Conversation today...
Guy: "Hey I need a real quick script to pull some values out of an XML document...is that possible?"
Me: "Uh...yeah that's pretty simple if that's all it has to do."
Guy: "Ok excellent I'll send you some files and documentation."
Me: "Ok so is this like a one time use thing or do you need to parse multiple of these?"
Guy: "Actually it needs to run all the time, on this specific PC, watch directories for any files that are added, then generate a XLSX files of the values, and also log information to a database. Etc"
Me: "Oh that adds quite a bit of complexity from what you originally said. It's going to take more time."
Guy: "But you said it was easy."
Well fuck you...12 -
Probably the biggest one in my life.
TL:DR at the bottom
A client wanted to create an online retirement calculator, sounds easy enough , i said sure.
Few days later i get an email with an excel file saying the online version has to work exactly like this and they're on a tight deadline
Having a little experience with excel, i thought eh, what could possibly go wrong, if anything i can take off the calculations from the excel file
I WAS WRONG !!!
17 Sheets, Linking each other, Passing data to each sheet to make the calculation
( Sure they had lot of stuff to calculate, like age, gender, financial group etc etc )
First thing i said to my self was, WHAT THE FREAKING FUCK IS THIS ?, WHAT YEAR IS THIS ?
After messing with it for couple of hours just to get one calculation out of it, i gave up
Thought about making a mysql database with the cell data and making the calculations, but NOOOO.
Whoever made it decided to put each cell a excel calculation ( so even if i manage to get it into a database and recode all the calculations it would be wayyy pass the deadline )
Then i had an epiphany
"What if i could just parse the excel file and get the data ?"
Did a bit of research sure enough there's a php project
( But i think it was outdated and takes about 15-25 seconds to parse, and makes a copy of the original file )
But this seemed like the best option at the time.
So downloaded the library, finished the whole thing, wrote a cron job to delete temporary files, and added a loading spinner for that delay, so people know something is happening
( and had few days to spare )
Sent the demo link to client, they were very happy with it, cause it worked same as their cute little excel file and gave the same result,
It's been live on their website for almost a year now, lot of submissions, no complains
I was feeling bit guilty just after finishing it, cause i could've done better, but not anymore
Sorry for making it so long, to understand the whole thing, you need to know the full story
TL:DR - Replicated the functionality of a 17 sheet excel calculator in php hack-ishly.8 -
"You mean to tell me that you deleted the class that holds all our labels and spin boxes together?" I said exasperatedly.
~Record scratch.mp3
~Freeze frame.mp4
"You're probably wondering how we got to this stage? Let's wind back a little, shall we?"
~reverseRecordSound.wav
A light tapping was heard at the entrance of my office.
"Oh hey [Boss] how are you doing?" I said politely
"Do you want to talk here, or do you want to talk in my office? I don't have anyone in my office right now, so..."
"Ok, we can go to your office," I said.
We walked momentarily, my eyes following the newly placed carpeting.
Some words were shared, but nothing that seemed mildly important. Just necessary things to say. Platitudes, I supposed you could call them.
We get to his office, it was wider now because of some missing furniture. I quickly grab a seat.
"So tell me what you've been working on," I said politely.
"I just finished up on our [project] that required proper saving and restoring."
"Great! How did you pull it off?" I asked excitedly.
He starts to explain to me what he did, and even opens up the UI to display the changes working correctly.
"That's pretty cool," admiring his work.
"But what's going on here? It looks like you deleted my class." I said, looking at his code.
"Oh, yeah, that. It looked like spaghetti code so I deleted it. It seemed really bulky and unnecessary for what we were doing."
"Wait, hold on," I said wildly surprised that he thought that a class with some simple setters and getters was spaghetti code.
"You mean to tell me that you deleted the class that organizes all our labels and spin boxes together?" I said exasperatedly.
"Yeah! I put everything in a list of lists."
"What, that's not efficient at all!" I exclaimed
"Well, I mean look at what you were doing here," he said, as he displays to me my old code.
"What's confusing about that?" I asked politely, but a little unnerved that he did something like this.
"Well I mean look at this," he said, now showing his "improved" code.
"We don't have that huge block of code (referring to my class) anymore filling up the file." He said almost a little too joyously.
"Ok, hold on," I said to him, waving my hand. "Go back to my code and I can show you how it is working. Here we are getting all the labels and spin boxes into their own objects." I said pointing a little further down in the code. "Down here we are returning the spin boxes we want to work with. Here and here, are setters so we can set maximum and minimum values for the spin box."
"Oh... I guess that's not that complicated. but still, that doesn't seem like really good bookkeeping." He said.
"Well, there are some people that would argue with you on that," I said, thinking about devRant.
He quickly switches back to his code and shows me what he did. "Look, here." He said pointing to his list of lists. "We have our spin boxes and labels all called and accounted for. And further down we can use a for loop to parse through them."
He then drags both our version of the code and shows the differences. I pause him for a moment
"Hold on, you mean you think this" I'm now pointing at my setters "is more spaghetti than this" I'm now pointing at his list of lists.
"I mean yeah, it makes more sense to me to do it this way for the sake of bookkeeping because I don't understand your Object Oriented Programming stuff."
...
After some time of going back and forth on this, he finally said to me.
"It doesn't matter, this is my project."
Honestly, I was a little heart broken, because it may be his project but part of me is still in there. Part of my effort in making it the best it can be is in there.
I'm sorry, but it's just as much my project as it is yours.17 -
I’m surrounded by idiots.
I’m continually reminded of that fact, but today I found something that really drives that point home.
Gather ‘round, everybody, it’s story time!
While working on a slow query ticket, I perused the code, finding several causes, and decided to run git blame on the files to see what dummy authored the mental diarrhea currently befouling my screen. As it turns out, the entire feature was written by mister legendary Apple golden boy “Finder’s Keeper” dev himself.
To give you the full scope of this mess, let me start at the frontend and work my way backward.
He wrote a javascript method that tracks whatever row was/is under the mouse in a table and dynamically removes/adds a “.row_selected” class on it. At least the js uses events (jQuery…) instead of a `setTimeout()` so it could be worse. But still, has he never heard of :hover? The function literally does nothing else, and the `selectedRow` var he stores the element reference in isn’t used elsewhere.
This function allows the user to better see the rows in the API Calls table, for which there is a also search feature — the very thing I’m tasked with fixing.
It’s worth noting that above the search feature are two inputs for a date range, with some helpful links like “last week” and “last month” … and “All”. It’s also worth noting that this table is for displaying search results of all the API requests and their responses for a given merchant… this table is enormous.
This search field for this table queries the backend on every character the user types. There’s no debouncing, no submit event, etc., so it triggers on every keystroke. The actual request runs through a layer of abstraction to parse out and log the user-entered date range, figure out where the request came from, and to map out some column names or add additional ones. It also does some hard to follow (and amazingly not injectable) orm condition building. It’s a mess of functional ugly.
The important columns in the table this query ultimately searches are not indexed, despite it only looking for “create_order” records — the largest of twenty-some types in the table. It also uses partial text matching (again: on. every. single. keystroke.) across two varchar(255)s that only ever hold <16 chars — and of which users only ever care about one at a time. After all of this, it filters the results based on some uncommented regexes, and worst of all: instead of fetching only one page’s worth of results like you’d expect, it fetches all of them at once and then discards what isn’t included by the paginator. So not only is this a guaranteed full table scan with partial text matching for every query (over millions to hundreds of millions of records), it’s that same full table scan for every single keystroke while the user types, and all but 25 records (user-selectable) get discarded — and then requeried when the user looks at the next page of results.
What the bloody fucking hell? I’d swear this idiot is an intern, but his code does (amazingly) actually work.
No wonder this search field nearly crashed one of the servers when someone actually tried using it.
Asdfajsdfk.21 -
Spent most of the day debugging issues with a new release. Logging tool was saying we were getting HTTP 400’s and 500’s from the backend. Couldn’t figure it out.
Eventually found the backend sometimes sends down successful responses but with statusCode 500 for no reason what so ever. Got so annoyed ... but said the 400’s must be us so can’t blame them for everything.
Turns out backend also sometimes does the opposite. Sends down errors with HTTP 200’s. A junior app Dev was apparently so annoyed that backend wouldn’t fix it, that he wrote code to parse the response, if it contained an error, re-wrote the statusCode to 400 and then passed the response up to the next layer. He never documented it before he left.
Saving the best part for last. Backend says their code is fine, it must be one of the other layers (load balancers, proxies etc) managed by one of the other teams in the company ... we didn’t contact any of these teams, no no no, that would require effort. No we’ve just blamed them privately and that’s that.
#successfulRelease4 -
Backend internship interview
They: Can you reverse the given string without using pointers? (C++)
Me: Yeah, sure
*Then I start explaining how I am gonna approach the problem and such*
They: Ok, we understand that you can do it, now can you write a front-end that has a couple of routes. Also, these routes should have some sort of list views because we want you to print information **attention** that you are going to parse from Amazon inside those list views.
Me: *dumbfounded and trying to explain that am not a front-end developer*
They: But we still want you to do this.3 -
I send a PR to your GitHub repo.
You close it without a word.
I tell you that your lib crashes because you're trying to parse JavaScript with a (bad) regex, but you keep insisting that no, there exist no problem, and even if you barely know what "parsing" means, you keep denying in front of the evidence.
Well fuck you and your shitty project. I'll keep using my fucking fork.
And if you're reading this, well, fuck you twice. Moron.10 -
Ok, rant incoming.
Dates. Frigging dates. Apparently we as a species are so bloody incompetent we cannot even decide on a one format for how to write today. No, instead we have one for every language and framework, because every moron thinks they know better how to write the date. All of them equivalent and all of them different enough to make me start lactating out of frustration trying to parse this garbage... And when you finally manage to parse it on one platform it turns out that your ORM just decided to use the less common version of the date, and have fun converting one to the other. I hope that ever time someone comes up with a new date format will be hit in a face with a red hot frying pan untill they give up programming in favour of growing cactuses.11 -
When I found out my JSON didn't parse because I used single instead of double quotes after two hours
 8
8 -
Had an interview in a MNC company.
He: Propose a solution for reading huge logs file like 1 GB and parse errors with today's date.
Me: Gave two solution, one with regex and second with buffering the logs (reason: reading the entire in same shot will cause cpu spike with huge memory consumption) and I fell in love with my second approach. By the way it was on paper.
He: (Without seeing the logic) Your syntax is wrong.
Me: Got frustrated who the hell checks syntax in interview. I asked how may years of experience you have?
He: 10 years.
Me: I don't wanna continue, and I left.5 -
I know you guys probably have seen the worst of the worst...
But have you seen a js used to generate xml and send it to backend as json then parse it to xml? No template literals btw so there’s a lot of multiline with lots of + here and there
Or using sql to request web service?9 -
Ah certbot you sexy pain in the ass.
# certbot renew
> "Error: unable to parse files ..."
> 2 certificates renewed.
🤔I don't know how you worked, but you keep working!!2 -
Interviewer: "Using this 2D array and calculate.."
Me: "This input isn't a 2D array though. Do you want me to parse or construct a 2D array then.."
"It is a 2D array."
"Uh.. ok..and if it's not what if we.."
"Look my notes say you must use this input, and treat it as a 2D Array"
"What if I wrote a function for a 2D array similar to this input, but actually a 2D array"
"You must use only the input provided"
Me: does rain dance code for 20 minutes.
Interviewer: "hmm, maybe it wasn't a 2D Array. I like your efforts but that's all the time we have today."
I promise I can code, sometimes. It does help to have correct questions to give correct answers.1 -
The tech stack at my current gig is the worst shit I’ve ever dealt with...
I can’t fucking stand programs, especially browser based programs, to open new windows. New tab, okay sure, ideally I just want the current tab I’m on to update when I click on a link.
Ticketing system: Autotask
Fucking opens up with a crappy piss poor sorting method and no proper filtering for ticket views. Nope you have to go create a fucking dashboard to parse/filter the shit you want to see. So I either have to go create a metric-arse tonne of custom ticket views and switch between them or just use the default turdburger view. Add to that that when I click on a ticket, it opens another fucking window with the ticket information. If I want to do time entry, it just feels some primal need to open another fucking window!!! Then even if I mark the ticket complete it just minimizes the goddamn second ticket window. So my jankbox-supreme PC that my company provided gets to strugglepuff along trying to keep 10 million chrome windows open. Yeah, sure 6GB of ram is great for IT work, especially when using hot steaming piles of trashjuice software!
I have to manually close these windows regularly throughout the day or the system just shits the bed and halts.
RMM tool: Continuum
This fucker takes the goddamn soggy waffle award for being utterly fucking useless. Same problem with the windows as autotask except this special snowflake likes to open a login prompt as a full-fuck-mothering-new window when we need to open a LMI rescue session!!! I need to enter a username and a password. That’s it! I don’t need a full screen window to enter credentials! FUCK!!! Btw the LMI tools only work like 70% of the time and drag ass compared to literally every other remote support tool I’ve ever used. I’ve found that it’s sometimes just faster to walk someone through enabling RDP on their system then remoting in from another system where LMI didn’t decide to be fully suicidal and just kill itself.
Our fucking chief asshat and sergeant fucknuts mcdoogal can’t fucking setup anything so the antivirus software is pushed to all client systems but everything is just set to the default site settings. Absolutely zero care or thought or effort was put forth and these gorilla spunk drinking, rimjob jockey motherfuckers sell this as a managed AntiVirus.
We use a shitty password manager than no one besides I use because there is a fully unencrypted oneNote notebook that everyone uses because fuck security right? “Sometimes it’s just faster to have the passwords at the ready without having to log into the password manager.” Chief Asshat in my first week on the job.
Not to mention that windows server is unlicensed in almost every client environment, the domain admin password is same across multiple client sites, is the same password to log into firewalls, and office 365 environments!!!
I’ve brought up tons of ways to fix these problems, but they have their heads so far up their own asses getting high on undeserved smugness since “they have been in business for almost ten years”. Like, Whoop Dee MotherFucking Doo! You have only been lucky to skate by with this dumpster fire you call a software stack, you could probably fill 10 olympic sized swimming pools to the brim with the logarrhea that flows from your gullets not only to us but also to your customers, and you won’t implement anything that is good for you, your company, or your poor clients because you take ten minutes to try and understand something new.
I’m fucking livid because I’m stuck in a position where I can’t just quit and work on my business full time. I’m married and have a 6m old baby. Between both my wife and I working we barely make ends meet and there’s absolutely zero reason that I couldn’t be providing better service to customers without having to lie through my teeth to them and I could easily support my family and be about 264826290461% happier!
But because we make so little, I can’t scrap together enough money to get Terranimbus (my startup) bootstrapped. We have zero expendable/savable income each month and it’s killing my soul. It’s so fucking frustrating knowing that a little time and some capital is all that stands between a better life for my family and I and being able to provide a better overall service out there over these kinds of shady as fuck knob gobblers.5 -
!dev && feelsbadman
I don't know what to think.
All I know is that I just went reaaaaal close to a disaster.
Friday morning, my "scariest" manager (as in, if you have to meet with him, it's usally for something serious) told me that he needed to see me on monday (so today) with the lead dev, the project manager and the dude who recruited me.
The meeting was like an arena of 4 vs 1, where they all 4 had problem with the work I do, as in I make a lot of small but stupid mistakes that wastes everyone's time. As an excuse, I suffer from sleep apnea so I wake up as tired I am when I go to sleep, and I snore loud as fuck. I've heard some records, it's not even human. (I'm 1m85-ish for 125 kg, it's BIG but with my morphology it's not like I'm a ball of fat)
Anyway. And since it's not the first time they're reproaching me this kind of stuff, they were all... really angry. Because I'm a nice guy, competent and all but not productive enough and easily distracted.
So, when the manager asked me to meet me, it was to fire me. However, during the lunch break, the lead dev found a solution: I get out of the current project I was in until this morning, and I write all the functional tests for all the projects, because they all lack quality and we sometimes deliver regresses.
They proposed me this in a way I could refuse, and I'd get fired because they had no other options. Obviously, I said yes, I'm not stupid enough to decline a possibilty to avoid a monstruous shitstorm that would have cut me my studies, the money for taxes, and a lot of fun to find a job as fast as possible.
But what surprised me the most is that they were genuinely glad I accepted, like, even though I made my shit ton of mistakes, they weren't pleased at all to get rid of me.
And in a way, I'm the one who won in this story, since I don't have to work with Drupal anymore, excepted to parse the website to write my tests, but my nightmare fuel is finally gone *.*
I don't know where to finish with this rant, but I needed to vent this whole thing, to write it somewhere so I can move forward.
I wish y'all a nice week.3 -
Senior colleagues insisting on ALWAYS returning HTTP status 200 and sticking any error codes in the contained JSON response instead of using 4×× or 5×× statuses.
Bad input? Failed connections? Missing authorization? Doesn't matter, you get an OK. Wanna know if the request actually succeeded? Fuck you, parse potential kilobytes of JSON to get to the error code!
Am I the asshole or is that defeating the purpose of a status code?!13 -
writing an assembler for my compiler, Manticore.
Currently working on writing a hand written parser and parse tree node system. 7
7 -
One thing I learnt after over two years of working as a programmer is that sometimes making your code DRY is less important than making your code readable, ESPECIALLY if you're working on a shared codebase. All those abstractions and metaprogramming may look good in your eyes, but might cause your teammates their coding time because they need to parse your mini-framework. So code wisely and choose the best approach that works FOR YOUR TEAM.7
-
I know it's not done yet but OOOOOH boy I'm proud already.
Writing a JSON parser in Lua and MMMM it can parse arrays! It converts to valid Lua types, respects the different quotation marks, works with nested objects, and even is fault-tolerant to a degree (ignoring most invalid syntax)
Here's the JSON array I wrote to test, the call to my function, and another call to another function I wrote to pretty print the result. You can see the types are correctly parsed, and the indentation shows the nested structure! (You can see the auto-key re-start at 1)
Very proud. Just gotta make it work for key/value objects (curly bracket bois) and I'm golden! (Easier said than done. Also it's 3am so fuck, dude)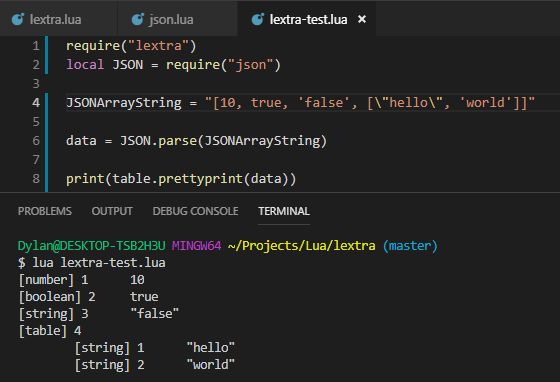 15
15 -
Doing linguistic research where I need to parse 2000 files of a total of 36 GB. Since we are using python the first thing I thought was to implement multi threading. Now I changed the total runtime from three days to like one day and a half. But then when I checked the activity monitor I saw only 20 percent of the CPU usage. After a searching process I started to understand how multi threading and multi processing works. Moral of the story: if you want to ping a website till they block you or do easy tasks that will not use up all power of one core, do multi thrading. If you need to do something complicated that can easily consume all the powers of a single CPU core, split up the work and do multi processing. In my case, when I tried to grab information from a website, I did multi thrading since the work is easy and I really wanted to pin the website 16 times simultaneously but only have 4 cores. But when it come to text processing which a single file will take 80 percent of cpu, split it up and do multi processing.
This is just a post for those who are confused with when to use which.12 -
A dev team has been spending the past couple of weeks working on a 'generic rule engine' to validate a marketing process. The “Buy 5, get 10% off” kind of promotions.
The UI has all the great bits, drop-downs, various data lookups, etc etc..
What the dev is storing the database is the actual string representation FieldA=“Buy 5, get 10% off” that is “built” from the UI.
Might be OK, but now they want to apply that string to an actual order. Extract ‘5’, the word ‘Buy’ to apply to the purchase quantity rule, ‘10%’ and the word ‘off’ to subtract from the total.
Dev asked me:
Dev: “How can I use reflection to parse the string and determine what are integers, decimals, and percents?”
Me: “That sounds complicated. Why would you do that?”
Dev: “It’s only a string. Parsing it was easy. First we need to know how to extract numbers and be able to compare them.”
Me: “I’ve seen the data structures, wouldn’t it be easier to serialize the objects to JSON and store the string in the database? When you deserialize, you won’t have to parse or do any kind of reflection. You should try to keep the rule behavior as simple as possible. Developing your own tokenizer that relies on reflection and hoping the UI doesn’t change isn’t going to be reliable.”
Dev: “Tokens!...yea…tokens…that’s what we want. I’ll come up with a tokenizing algorithm that can utilize recursion and reflection to extract all the comparable data structures.”
Me: “Wow…uh…no, don’t do that. The UI already has to map the data, just make it easy on yourself and serialize that object. It’s like one line of code to serialize and deserialize.”
Dev: “I don’t know…sounds like magic. Using tokens seems like the more straightforward O-O approach. Thanks anyway.”
I probably getting too old to keep up with these kids, I have no idea what the frack he was talking about. Not sure if they are too smart or I’m too stupid/lazy. Either way, I keeping my name as far away from that project as possible.4 -
Woke up at 5am with the realization that I could use regular expressions to parse the string representation of regular expressions to build this program to parse regular expressions into more human-readable English.
I am so tired.5 -
>Middle of night
>css not getting applied conditionally
>a simple ng-class
>me raging
>fuck angular's digest loop
>fuck dom and not giving parse errors
>fuck my life
>Coworker is also confused
>after 1hr, what it could be
>A typo, ifStudent->isStudent
>😑3 -
I fucking hate the web guy.
He says - make a pop-up of the raw text you're receiving (in the app) so that I can test it easily while I fix it.
I did it.
Now he laughs and says - I think you searched for it and simply copied from wrong example. All you had to do was handle the text and parse it and display it blablabla instead of simply popping up the raw text.
Thank you I flipping KNOW all of that, you stuck up obnoxious frog. I did it that way initially and uploaded it coz you SAID so! Why do you ALWAYS have to talk like I know nothing!?5 -
I've optimised so many things in my time I can't remember most of them.
Most recently, something had to be the equivalent off `"literal" LIKE column` with a million rows to compare. It would take around a second average each literal to lookup for a service that needs to be high load and low latency. This isn't an easy case to optimise, many people would consider it impossible.
It took my a couple of hours to reverse engineer the data and implement a few hundred line implementation that would look it up in 1ms average with the worst possible case being very rare and not too distant from this.
In another case there was a lookup of arbitrary time spans that most people would not bother to cache because the input parameters are too short lived and variable to make a difference. I replaced the 50000+ line application acting as a middle man between the application and database with 500 lines of code that did the look up faster and was able to implement a reasonable caching strategy. This dropped resource consumption by a minimum of factor of ten at least. Misses were cheaper and it was able to cache most cases. It also involved modifying the client library in C to stop it unnecessarily wrapping primitives in objects to the high level language which was causing it to consume excessive amounts of memory when processing huge data streams.
Another system would download a huge data set for every point of sale constantly, then parse and apply it. It had to reflect changes quickly but would download the whole dataset each time containing hundreds of thousands of rows. I whipped up a system so that a single server (barring redundancy) would download it in a loop, parse it using C which was much faster than the traditional interpreted language, then use a custom data differential format, TCP data streaming protocol, binary serialisation and LZMA compression to pipe it down to points of sale. This protocol also used versioning for catchup and differential combination for additional reduction in size. It went from being 30 seconds to a few minutes behind to using able to keep up to with in a second of changes. It was also using so much bandwidth that it would reach the limit on ADSL connections then get throttled. I looked at the traffic stats after and it dropped from dozens of terabytes a month to around a gigabyte or so a month for several hundred machines. The drop in the graphs you'd think all the machines had been turned off as that's what it looked like. It could now happily run over GPRS or 56K.
I was working on a project with a lot of data and noticed these huge tables and horrible queries. The tables were all the results of queries. Someone wrote terrible SQL then to optimise it ran it in the background with all possible variable values then store the results of joins and aggregates into new tables. On top of those tables they wrote more SQL. I wrote some new queries and query generation that wiped out thousands of lines of code immediately and operated on the original tables taking things down from 30GB and rapidly climbing to a couple GB.
Another time a piece of mathematics had to generate all possible permutations and the existing solution was factorial. I worked out how to optimise it to run n*n which believe it or not made the world of difference. Went from hardly handling anything to handling anything thrown at it. It was nice trying to get people to "freeze the system now".
I build my own frontend systems (admittedly rushed) that do what angular/react/vue aim for but with higher (maximum) performance including an in memory data base to back the UI that had layered event driven indexes and could handle referential integrity (overlay on the database only revealing items with valid integrity) or reordering and reposition events very rapidly using a custom AVL tree. You could layer indexes over it (data inheritance) that could be partial and dynamic.
So many times have I optimised things on automatic just cleaning up code normally. Hundreds, thousands of optimisations. It's what makes my clock tick.4 -
Well, if your tests fails because it expects 1557525600000 instead of 1557532800000 for a date it tells you exactly: NOTHING.
Unix timestamp have their point, yet in some cases human readability is a feature. So why the fuck don't you display them not in a human readable format?
Now if you'd see:
2019-05-10T22:00:00+00:00
vs the expected
2019-05-11T00:00:00+00:00
you'd know right away that the first date is wrong by an offset of 2 hours because somebody fucked up timezones and wasn't using a UTC calculation.
So even if want your code to rely on timestamps, at least visualize your failures in a human readable way. (In most cases I argue that keeping dates as an iso string would be JUST FUCKING FINE performance-wise.)
Why do have me parse numbers? Show me the meaningful data.
Timestamps are for computers, dates are for humans.3 -
CR: "Add x here (to y) so it fits our code standards"
> No other Y has an X. None.
CR: "Don't ever use .html_safe"
> ... Can't render html without it. Also, it's already been sanitized, literally by sanitize(), written by the security team.
CR: "Haven't seen the code yet; does X change when resetting the password?"
> The feature doesn't have or reference passwords. It doesn't touch anything even tangentially related to passwords.
> Also: GO READ THE CODE! THAT'S YOUR BLOODY JOB!
CR: "Add an 'expired?' method that returns '!active'?"
> Inactive doesn't mean expired. Yellow doesn't mean sour. There's already an 'is_expired?' method.
CR: "For logging, always use json so we can parse it. Doesn't matter if we can't read it; tools can."
CR: "For logging, never link log entries to user-readable code references; it's a security concern."
CR: "Make sure logging is human-readable and text-searchable and points back to the code."
> Confused asian guy, his hands raised.
CR: "Move this data formatting from the view into the model."
> No. Views are for formatting.
CR: "Use .html() here since you're working with html"
> .html() does not support html. It converts arrays into html.
NONE OF THIS IS USEFUL! WHY ARE YOU WASTING MY TIME IF YOU HAVEN'T EVEN READ MY CODE!?
dfjasklfagjklewrjakfljasdf4 -
[CMS of Doom™]
The gift that keeps on giving...
When you think you've seen it all after 7 months in legacy hell, you get another gift:
Let's say you use PHP, but your IQ is in the zero-ish range, then it is obvious to:
- use define() for constants in all your config.*.php files
- then include said config.*.php files multiple times
- and because define() doesn't overwrite the same constant, because it's - you know - a constant, you instead of including just do a file_get_contents() to read the PHP file as string and then parse the values by Regex.
The dev who wrote this was truly one of the devs ever.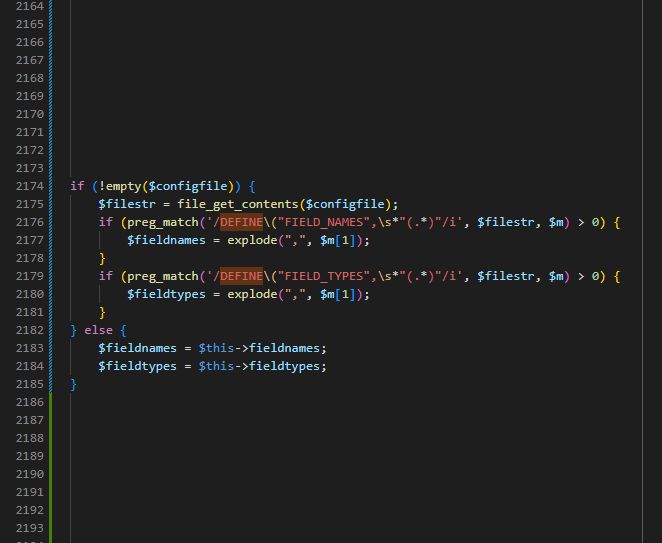 12
12 -
"I'm almost done, I'll just need to add tests!"
Booom! You did it, that was a nuke going off in my head.
No, you shouldn't just need to add tests. The tests should have been written from the get go! You most likely won't cover all the cases. You won't know if adding the tests will break your feature, as you had none, as you refactor your untested mess in order to make your code testable.
When reading your mess of a test case and the painful mocking process you went through, I silently cry out into the void: "Why oh why!? All of this suffering could have been avoided!"
Since most of the time, your mocking pain boils down to not understanding what your "unit" in your "unit test" should be.
So let it be said:
- If you want to build a parser for an XML file, then just write a function / class whose *only* purpose is: parse the XML file, return a value object. That's it. Nothing more, nothing less.
- If you want to build a parser for an XML file, it MUST NOT: download a zip, extract that zip, merge all those files to one big file, parse that big file, talk to some other random APIs as a side-effect, and then return a value object.
Because then you suddenly have to mock away a http service and deal with zip files in your test cases.
The http util of your programming language will most likely work. Your unzip library will most likely work. So just assume it working. There are valid use cases where you want to make sure you acutally send a request and get a response, yet I am talking unit test here only.
In the scope of a class, keep the public methods to a reasonable minimum. As for each public method you shall at least create one test case. If you ever have the feeling "I want to test that private method" replace that statement in your head with: "I should extract that functionality to a new class where that method public. I then can create a unit test case a for that." That new service then becomes a dependency in your current service. Problem solved.
Also, mocking away dependencies should a simple process. If your mocking process fills half the screen, your test setup is overly complicated and your class is doing too much.
That's why I currently dig functional programming so much. When you build pure functions without side effects, unit tests are easy to write. Yet you can apply pure functions to OOP as well (to a degree). Embrace immutability.
Sidenote:
It's really not helpful that a lot of developers don't understand the difference between unit, functional acceptance, integration testing. Then they wonder why they can't test something easily, write overly complex test cases, until someone points out to them: No, in the scope of unit tests, we don't need to test our persistance layer. We just assume that it works. We should only test our businsess logic. You know: "Assuming that I get that response from the database, I expect that to happen." You don't need a test db, make a real query against that, in order to test that. (That still is a valid thing to do. Yet not in the scope of unit tests.)8 -
🐉
I once wrote a room planning application on unity, to allow people in my company to book meetings using tablets attached to the room doors.
Turns out the c# Datetime object unity uses was highly localized and therefore had a different formats on each different device.
I saved those timestamps into a SQL database and eventually all devices crashed due to having some Datetime format they could not parse.
Had to fully bypass the datetime and reinvent it essentially and had to reset the database.
I think it's needless to say I'm not particularly good in dating.4 -
Don't you hate it when your co-worker does dumb things, but thinks it's the "clean code" way?
The following is a conversation between me and a co-worker, who thinks he's superior to everyone because he thinks he's the only one who read the Clean Code series. Let's call him Bill.
Me: I think the feature we need is quite simple, our application needs to call this third party API, parse the response and pass it to the next step. Why do you need to bury everything under an abstraction of 4 layers?
Bill: bEcAuSe It'S dEcOuPlInG, aNd MaKe ThE cOdE tEsTaBlE
Me: I don't know man, you only need to abstract the third party api client, and then mock it if you want. Some interfaces you define makes no sense at all. For example, this interface only has 1 concrete implementation, and I don't think it will ever have another. Besides, the concrete implementation only gets the input from the upper layer and passes it down the lower layer. Why the extra step? I feel like you're using interface just for the sake of interface.
Bill: PrOgRaMmInG tO iNtErFaCe, NoT cOnCrEtE iPlEmEnTaTiOn!!!
Me: You keep saying those words, I don't think they mean what you think they mean. But they certainly do not mean that every method argument must be an interface
Bill: BuT uNcLe BoB blah blah blah...
Me: *gives up all hope*14 -
!dev - cybersecurity related.
This is a semi hypothetical situation. I walked into this ad today and I know I'd have a conversation like this about this ad but I didn't this time, I had convo's like this, though.
*le me walking through the city centre with a friend*
*advertisement about a hearing aid which can be updated through remote connection (satellite according to the ad) pops up on screen*
Friend: Ohh that looks usefu.....
Me: Oh damn, what protocol would that use?
Does it use an encrypted connection?
How'd the receiving end parse the incoming data?
What kinda authentication might the receiving end use?
Friend: wha..........
Me: What system would the hearing aid have?
Would it be easy to gain RCE (Remote Code Execution) to that system through the satellite connection and is this managed centrally?
Could you do mitm's maybe?
What data encoding would the transmissions/applications use?
Friend: nevermind.... ._________.
Cybersecurity mindset much...!11 -
I'M BACK TO MY WEBDEV ADVENTURES GUYS! IT TOOK ME LIKE 4 MONTHS TO STOP BEING SO FUCKING DEPRESSED SO I CAN ACTUALLY STAND TO WORK ON IT AGAIN
I learned that the linear gradient looks cool as FUCK. Honestly not too fond of the colors I have right now, but I just wanted to have something there cause I can change it later. The page has evolved a bunch from my original concept.
My original concept was the bar in the middle just being a URL bar and having links on the sides. If I had kept that, it would have taken me a few hours to get done. But as time went on when I was working on it, my idea kept changing. Added the weather (had a forecast for a while but the code was gross and I never looked at the next days anyways, so I got rid of it and kept the current data). I wanted to attempt an RSS reader, but yesterday I was about to start writing the JavaScript to parse the feeds, then decided "nah", ended up making the space into a todo list.
The URL bar changed into a full command bar (writing the functions for the commands now, also used to config smaller things, such as the user@hostname part, maybe colors, weather data for city and API key, etc)....also it can open URLs and subreddits (that part works flawlessly). The bar uses a regex to detect if it's a legit URL (even added shit so I don't need http:// or https://), and if it's not, just search using duckduckgo (maybe I'll add a config option there too for search engines).
At this very moment it doesn't even take a second to fully load. It fetches weather data from openweathermap, parses it, and displays it, then displays the "user" name grabbing a localstorage value.
I'm considering adding a sidebar with links (configurable obviously, I want everything to be dynamic, so someone else could use my page if they wanted), but I'm not too sure about it.
It's not on git yet because I was waiting until I get some shit finished today before I commit. From the picture, I want to know if anyone has any suggestions for it. Also note that I am NOT a designer. I can't design for shit. 12
12 -
I rewrote my static website generation from jekyll to custom python code over single night.
Literally all jekyll plugins I use including seo, rss, syntax highlighting inside markdown content, sitemap, social plugins, css sass, all of it.
Now it’s around 400 lines of python code that I understand completely. I didn’t touch any existing templates and after comparing output I got even better results now and it’s working faster.
I skipped drafts as I don’t need them now.
Why ? Cause now I can make better generator for my side projects that can include some partial website generation, better modification and date handling, tree structure, etc.
What I will do now is that I will parse bunch of content to create markdown files that will be sucked by this generator to create static web pages that will flood internet lol.
Still I didn’t believe it was possible to rewrite all of it so quickly. I sit yesterday around 4pm and finished around 6am.
I started thinking that maybe I am crazy and no one can help me.9 -
4 hours! four fucking hours! f.o.u.r. h.o.u.r.s.!
It's the amount in the time domain this bug has cost me to fix. The cost in the sanity domain is immeasurable...
I swear, the god damn ass births of devs who coded this abomination should be slowly mutilated and then raped by their own severed limbs.
It took me 4 hours to figure out that their 12 year old binary CLI tool they used to generate PDFs from PHP could not handle neither HTML5 nor some linebreaks at specific places. Some part of it is due to them using REGEX to find and replace HTML tag.
Yes, I am indeed very pissed. And I need a 🥃 or 3
What we learned:
- Don't use REGEX to "parse" HTML
- Don't call random compiled CLI tools from PHP if there are PHP packages to do the same shit9 -
I feel like Stackoverflow is a fastfood for programmers mind. It gives you a solution you starve for. It may be not the best quality, but it works for now. It does not satisfy you in a long run, and may be too shallow for advancing. But it works and gives you more to think about.
I would never find a quick solution to parse a string with regex. I never thought it works this way. But hey, I'm happy.9 -
oh, it got better!
One year ago I got fed up with my daily chores at work and decided to build a robot that does them, and does them better and with higher accuracy than I could ever do (or either of my teammates). So I did it. And since it was my personal initiative, I wasn't given any spare time to work on it. So that leaves gaps between my BAU tasks and personal time after working hours.
Regardless, I spent countless hours building the thing. It's not very large, ~50k LoC, but for a single person with very little time, it's quite a project to make.
The result is a pure-Java slack-bot and a REST API that's utilized by the bot. The bot knows how to parse natural language, how to reply responses in human-friendly format and how to shout out errors in human-friendly manner. Also supports conversation contexts (e.g. asks for additional details if needed before starting some task), and some other bells and whistles. It's a pretty cool automaton with a human-friendly human-like UI.
A year goes by. Management decides that another team should take this project over. Well okay, they are the client, the code is technically theirs.
The team asks me to do the knowledge transfer. Sounds reasonable. Okay.. I'll do it. It's my baby, you are taking it over - sure, I'll teach you how to have fun with it.
Then they announce they will want to port this codebase to use an excessive, completely rudimentary framework (in this project) and hog of resources - Spring. I was startled... They have a perfectly running lightweight pure-java solution, suitable for lambdas (starts up in 0.3sec), having complete control over all the parts of the machinery. And they want to turn it into a clunky, slow monster, riddled with Reflection, limited by the framework, allowing (and often encouraging) bad coding practices.
When I asked "what problem does this codebase have that Spring is going to solve" they replied me with "none, it's just that we're more used to maintaining Spring projects"
sure... why not... My baby is too pretty and too powerful for you - make it disgusting first thing in the morning! You own it anyway..
Then I am asked to consult them on how is it best to make the port. How to destroy my perfectly isolated handlers and merge them into monstrous @Controller classes with shared contexts and stuff. So you not only want to kill my baby - you want me to advise you on how to do it best.
sure... why not...
I did what I was asked until they ran into classloader conflicts (Spring context has its own classloaders). A few months later the port is not yet complete - the Spring version does not boot up. And they accidentally mention that a demo is coming. They'll be demoing that degenerate abomination to the VP.
The port was far from ready, so they were going to use my original version. And once again they asked me "what do you think we should show in the demo?"
You took my baby. You want to mutilate it. You want me to advise on how to do that best. And now you want me to advise on "which angle would it be best to look at it".
I wasn't invited to the demo, but my colleagues were. After the demo they told me mgmt asked those devs "why are you porting it to Spring?" and they answered with "because Spring will open us lots of possibilities for maintenance and extension of this project"
That hurts.
I can take a lot. But man, that hurts.
I wonder what else have they planned for me...9 -
That moment when you're doing regex to parse regex expression stored in a file whose name you found using a regex on input. Regex-ception1
-
Me: yo DEV2 parse this string into a hashmap. Use regex, 2 rows of code are enough for the job
DEV2: implemented 40 rows of switch/if cases into nested for loop.
Please kill me 🔫🔫🔫🔫🔫🔫🇮🇹3 -
Why would you ask me the diferrence between parseInt and parseFloat? When you were the first person who was unable to fix the decimal to two using parseFloat? 😝
-
Writing a function to take a string of delimited entities, parse each character to find the separators, capture the characters in between separators, and return an array of entities.
I used this for about a year before I learned about String.split()
Yeah.1 -
When you are googling something about Parse.com for a new language and the first 35000 results are "how to parse $something in $language"
 4
4 -
I made a functional parsing layer for an API that cleans http body json. The functions return insights about the received object and the result of the parse attempt. Then I wrote validation in the controller to determine if we will reject or accept. If we reject, parse and validation information is included on the error response so that the API consumer knows exactly why it was rejected. The code was super simple to read and maintain.
I demoed to the team and there was one hold out that couldn’t understand my decision to separate parse and validate. He decided to rewrite the two layers plus both the controller and service into one spaghetti layer. The team lead avoided conflict at all cost and told me that even though it was far worse code to “give him this”. We still struggle with the spaghetti code he wrote to this day.
When sugar-coating someone’s engineering inadequacies is more important than good engineering I think about quitting. He was literally the only one on the team that didn’t get it.2 -
Who the fuck uses http code 200 for a failure. Seriously have you ever heard something about a need to parse the shit you're returning...
Now I don't know whether it's me who's wrong, but man there are more than 80 different codes defined so there really should be something for you, don't you think?
And don't give me shit like "well the request worked so we return 200 it's only that the request wasn't correct". What for a fucking peace of something are you... Those codes are for that exact reason.
Anyways I'm going to parse the shit with string compare and afterwards kill myself out of shame. Whish me luck... 4
4 -
Writing the new software dev test for our incoming interview process.
Me: And here is where we ask them to parse HTML with regex.
Lead developer: You are fucked up and the villain of this movie, multiverse and everything in between, fk u.
CMS Admin: And I thought Palpatine was evil. That is legit fucked up, fk u.16 -
Me, the only iOS dev at work one day, and colleague (who we'll call AndroidBoy), the only Android dev at work that same day (he's been working with us for less than two months). There was a change in one of the jsons we received from the server: instead of receiving a list, we now received a dictionary with strings as keys and lists as values. My iOS colleague had already made this modification on our parse function the day before.
AndroidBoy: "Hey what happened with the json?"
Me: "Oh, well instead of parsing a list, we'll parse a dictionary and get the list from each key. You basically have to do the same thing, only this time the lists are organized into categories."
AndroidBoy: "Oh, ok. But I don't know how to parse a dictionary while using Retrofit." (Context: Retrofit is a framework for request handling - correct me if I am mistaken, that's just what I've been told)
Me: "Sucks, dude, can't help ya. I've never worked with that and don't have that much exp. with Android."
I go out for a cigarette break. When I return, AndroidBoy is nowhere to be seen and suddenly I can't seem to get that data in my app. AndroidBoy comes in from the room where the backend colleagues work.
AndroidBoy: "Solved it!"
Me: "Solved what?"
AndroidBoy: "I told them to change back to a list and just put the key inside the objects of the list."
... he used the precious time of the backend colleagues to change the thing back hust because he was too lazy to search how to parse a dictionary. I was so amazed by his answer, that I didn't know whether to laugh, scream at him or punch him in the face. Not to mention the fact that now I had to revert just so he could avoid that extra work.5 -
Your data is formatted according to some ISO? Nice. You say it's easy to use and well documented? Great!
IT'S FUCKING FORMATTED WITH IRREGULAR SPACING??
What the fuck is this formatting?
Date <tab> Word <3 spaces> Some conjugated version <ONE space> Type <FIVE spaces> gender
WHAT
WHY
WHY ISNT IT XML
WHY ISNT IT JSON
WHY THE TABULATOR AND IRREGULAR SPACES
WHY DOES THE ORDER CHANGE PER LINE
WHY IS THIS IN A SINGLE 1MIL LINE FILE
help the university of oslo makes me dysphoric in their dictionaries i really dont want to parse this1 -
You know that feeling when you're coding late at night and you get an error that you just can't parse with your tired brain, and go FUCK IT ALL, FUCK IT ALL
I'm having that feeling right about now... 6
6 -
Instead of worrying about API rate limits I made my code manually parse the html from a website.
And the code still works great!4 -
Want to make someone's life a misery? Here's how.
Don't base your tech stack on any prior knowledge or what's relevant to the problem.
Instead design it around all the latest trends and badges you want to put on your resume because they're frequent key words on job postings.
Once your data goes in, you'll never get it out again. At best you'll be teased with little crumbs of data but never the whole.
I know, here's a genius idea, instead of putting data into a normal data base then using a cache, lets put it all into the cache and by the way it's a volatile cache.
Here's an idea. For something as simple as a single log lets make it use a queue that goes into a queue that goes into another queue that goes into another queue all of which are black boxes. No rhyme of reason, queues are all the rage.
Have you tried: Lets use a new fangled tangle, trust me it's safe, INSERT BIG NAME HERE uses it.
Finally it all gets flushed down into this subterranean cunt of a sewerage system and good luck getting it all out again. It's like hell except it's all shitty instead of all fiery.
All I want is to export one table, a simple log table with a few GB to CSV or heck whatever generic format it supports, that's it.
So I run the export table to file command and off it goes only less than a minute later for timeout commands to start piling up until it aborts. WTF. So then I set the most obvious timeout setting in the client, no change, then another timeout setting on the client, no change, then i try to put it in the client configuration file, no change, then I set the timeout on the export query, no change, then finally I bump the timeouts in the server config, no change, then I find someone has downloaded it from both tucows and apt, but they're using the tucows version so its real config is in /dev/database.xml (don't even ask). I increase that from seconds to a minute, it's still timing out after a minute.
In the end I have to make my own and this involves working out how to parse non-standard binary formatted data structures. It's the umpteenth time I have had to do this.
These aren't some no name solutions and it really terrifies me. All this is doing is taking some access logs, store them in one place then index by timestamp. These things are all meant to be blazing fast but grep is often faster. How the hell is such a trivial thing turned into a series of one nightmare after another? Things that should take a few minutes take days of screwing around. I don't have access logs any more because I can't access them anymore.
The terror of this isn't that it's so awful, it's that all the little kiddies doing all this jazz for the first time and using all these shit wipe buzzword driven approaches have no fucking clue it's not meant to be this difficult. I'm replacing entire tens of thousands to million line enterprise systems with a few hundred lines of code that's faster, more reliable and better in virtually every measurable way time and time again.
This is constant. It's not one offender, it's not one project, it's not one company, it's not one developer, it's the industry standard. It's all over open source software and all over dev shops. Everything is exponentially becoming more bloated and difficult than it needs to be. I'm seeing people pull up a hundred cloud instances for things that'll be happy at home with a few minutes to a week's optimisation efforts. Queries that are N*N and only take a few minutes to turn to LOG(N) but instead people renting out a fucking off huge ass SQL cluster instead that not only costs gobs of money but takes a ton of time maintaining and configuring which isn't going to be done right either.
I think most people are bullshitting when they say they have impostor syndrome but when the trend in technology is to make every fucking little trivial thing a thousand times more complex than it has to be I can see how they'd feel that way. There's so bloody much you need to do that you don't need to do these days that you either can't get anything done right or the smallest thing takes an age.
I have no idea why some people put up with some of these appliances. If you bought a dish washer that made washing dishes even harder than it was before you'd return it to the store.
Every time I see the terms enterprise, fast, big data, scalable, cloud or anything of the like I bang my head on the table. One of these days I'm going to lose my fucking tits.10 -
After three weeks looking for decent pdf parser that will handle all documents I gathered for my project I decided to write my own.
All those I tried end up with more then 10% not correctly parsed pdfs or require to much coding.
I was sceptic so I waited another week debating if it’s good idea to do it and I said yes.
Spent 16 hours straight coding pdf document extraction library and command line tool based on pdf.js
Fuck, now when I open pdf I see opcodes instead of text.
Got two more hours until client planning meeting and then I go to sleep for a while.
Time to start testing this more deeply as I have about 60k ~ 20GB pdf documents to parse and then I need to build some dependency graph out of its text.
At least it’s more funny then making boring REST API for money.4 -
When you think the code from companies like Google and Facebook is flawless, but then you look at the source code of Parse 1.5.0 and find an if statement with the condition 'browser' === 'browser'
 2
2 -
I have come across the most frustrating error i have ever dealt with.
Im trying to parse an XML doc and I keep getting UnauthorizedAccessException when trying to load the doc. I have full permissions to the directory and file, its not read only, i cant see anything immediately wrong as to why i wouldnt be able to access the file.
I searched around for hours yesterday trying a bunch of different solutions that helped other people, none of them working for me.
I post my issue on StackOverflow yesterday with some details, hoping for some help or a "youre an idiot, Its because of this" type of comment but NO.
No answers.
This is the first time Ive really needed help with something, and the first time i havent gotten any response to a post.
Do i keep trying to fix this before the deadline on Sunday? Do i say fuck it and rewrite the xml in C# to meet my needs? Is there another option that i dont even know about yet?
I need a dev duck of some sort :/39 -
Fun issue
Swedish client is unable to enter a currency conversion rate in a field and submit. 'Not a float' well we can clearly see that it is a float when he does it (0.5 for example), not an issue for us though.
Reproducing was a nightmare, eventually it boiled down to the fact that the framework we were using had automatic locale checks. Now because our numeric fields are actually weird text fields (front end nonsense), it was converting the period to be a comma (Swedish people would write 0,5 normally). And if you actually entered 0,5 the range check (0.01-1000) failed because it couldn't parse the comma (no locale check on that one)
Godamn facepalm. Really confused the hell out of us when we saw the error, had to go diving through library code. To top this off, locale checks are supposed to be disabled as of about 2 years ago
In revenge against our oppressor :PHP: on slack is now an alias for the shit emoji5 -
So I just spent the last few hours trying to get an intro of given Wikipedia articles into my Telegram bot. It turns out that Wikipedia does have an API! But unfortunately it's born as a retard.
First I looked at https://www.mediawiki.org/wiki/API and almost thought that that was a Wikipedia article about API's. I almost skipped right over it on the search results (and it turns out that I should've). Upon opening and reading that, I found a shitload of endpoints that frankly I didn't give a shit about. Come on Wikipedia, just give me the fucking data to read out.
Ctrl-F in that page and I find a tiny little link to https://mediawiki.org/wiki/... which is basically what I needed. There's an example that.. gets the data in XML form. Because JSON is clearly too much to ask for. Are you fucking braindead Wikipedia? If my application was able to parse XML/HTML/whatevers, that would be called a browser. With all due respect but I'm not gonna embed a fucking web browser in a bot. I'll leave that to the Electron "devs" that prefer raping my RAM instead.
OK so after that I found on third-party documentation (always a good sign when that's more useful, isn't it) that it does support JSON. Retardpedia just doesn't use it by default. In fact in the example query that was a parameter that wasn't even in there. Not including something crucial like that surely is a good way to let people know the feature is there. Massive kudos to you Wikipedia.. but not really. But a parameter that was in there - for fucking CORS - that was in there by default and broke the whole goddamn thing unless I REMOVED it. Yeah because CORS is so useful in a goddamn fucking API.
So I finally get to a functioning JSON response, now all that's left is parsing it. Again, I only care about the content on the page. So I curl the endpoint and trim off the bits I don't need with jq... I was left with this monstrosity.
curl "https://en.wikipedia.org/w/api.php/...=*" | jq -r '.query.pages[0].revisions[0].slots.main.content'
Just how far can you nest your JSON Wikipedia? Are you trying to find the limits of jq or something here?!
And THEN.. as an icing on the cake, the result doesn't quite look like JSON, nor does it really look like XML, but it has elements of both. I had no idea what to make of this, especially before I had a chance to look at the exact structured output of that command above (if you just pipe into jq without arguments it's much less readable).
Then a friend of mine mentioned Wikitext. Turns out that Wikipedia's API is not only retarded, even the goddamn output is. What the fuck is Wikitext even? It's the Apple of wikis apparently. Only Wikipedia uses it.
And apparently I'm not the only one who found Wikipedia's API.. irritating to say the least. See e.g. https://utcc.utoronto.ca/~cks/...
Needless to say, my bot will not be getting Wikipedia integration at this point. I've seen enough. How about you make your API not retarded first Wikipedia? And hopefully this rant saves someone else the time required to wade through this clusterfuck.12 -
Job description: designing and building microservices and API contracts for enterprise use. Deep understanding of api/rest design, AWS, etc.
Interview: in this weird IDE while I stare over you, go through and parse this multi-dimensional primitive array using recursion.
...Wtf does this have to do with the role?8 -
Writing a truly crossplatform terminal library is the biggest pain in the ass.
And you thought windows was bad. They have a proper API with droves of features, freely allocatable screenbuffers, scrolling on both axes, etc.
Fucking xterm vtxxx compatible piles of shit are the problem.
Controlling kinda works eventhough the feature set is pretty bad. The really fucked up thing is reading values back. They literally get put into the input buffer. So you have to read all the actual user input before that and then somehow parse out the returned control sequence. Of course the user input has to be consumed so I have to buffer it myself. Even better is when you get a response with non printable characters which the fucking terminal will interpret as another control sequence. So when you set a window title to a ansi control sequence it would get executed when queried. Fuck this shit but I'm not giving up. I will tame this ugly, bodged together dragon7 -
Unreal Engine SDLC:
1. Start Epic
2. Wait
3. Start Unity
4. Wait
5. Open Project
6. Wait
7. Wait more
8. a bit longer...
9. (it usually crashes here, or freezes, in which case go to 1)
10. Game opened, make modifications in C++ codes
11. Wait VS to load
12. Wait VS to parse all the file in solution
13. Make changes
14. Compile
15. Run from Unreal
16. (sometimes, go to 9)
17. Goto 9
18. 9
19. Goto 9
20. Congrats on finishing the game, and losing your patience8 -
IPAY88 is the worst payment integration. They parse html data and encoded it into xml for return the data, it is not even singlet or server to server communication , tey called it the ADVANCED BACKEND SYSTEM (My arse!) For security, they ENCODE THE STRING into BASE64 and called it ENCRYPTION ! WHAT THE FUCK?
Encoding is not encryption! I qas expecting they used diffie hellman or AES or RSA etc. THEY TOLD BE ENCODING IS ENCRYPTION? WHAT THE FUCK?1 -
I thought 'atoi' was just some acronym wtf who thought it would be a good idea to name a parse function 'atoi'?9
-
Im a fucking idiot, instead of fetching some data and then immediately using it to fetch other data, i saved it in a file to parse later and fetch it into other data. And it's been running for a day now so I dont wanna stop it.7
-
People keep using Firebase and saying how cool it is, I'll laught when Google does the same that facebook did with Parse or hike prices like they did with Google Maps Recently.... People stop putting your core logic in a third party black box.. it's not going to end well...4
-
One day I want to replace all "ERROR" logs with "FUCK":
09-31-26: FUCK: Database not initialized.
09-31-26: FUCK: Unable to parse input.2 -
So a colleague and me are coding a Text Editor in C, and since i was adding a few Themes today i was wondering, what y'all using in your go to Editors and IDEs? Maybe i could include a few slightly modified versions of these themes aswell (modified in the sense of adjusted config)
The Editor is called MOSSY Editor, if someone's interested. MOSSY was some abbreviation for Model Based Syntax, since it's python implementation used a full parse tree in the background. 14
14 -
Just started my exams training! (Doing a study called Application Development).
The application doesn't sound that complicated but I have to implement a data exporting feature. Sounds alright, doesn't it?
THE 'CLIENT' DOES NOT KNOW WHAT DATA FORMAT THE FICTIVE CUSTOMERS CAN PARSE/HANDLE BUT I HAVE TO MAKE IT GENERIC SO THAT THEY CAN USE IT ANYWAYS. HOW THE FUCKING FUCK AM I SUPPOSED TO KNOW WHAT FUCKING FORMAT I SHOULD CHOOSE?!? SHOULD I TRY TO SMELL IT OR SOMETHING?
FML.2 -
Watcher: News feed for anything on the web you can parse
https://github.com/allanx2000/...
Still use it everyday
And the components in it had a few children so good example of reuseability ... And automation.
So very good return on investment. 4
4 -
Since Parse is shutting down by January 27th, I need to migrate my startup application's entire database to a new platform. What a pain. I'm thinking of doing Firebase...11
-
A service had/has been logging hundreds of errors in the development environment and I reached out to the owning process mgr that the error was occurring and perhaps a good opportunity to log additional data to help troubleshoot the issue if the problem ever made its way to production. He responded saying the error was related to a new feature they weren't going to implement in the backing dev database (TL;DR), and they know it works in production (my spidey sense goes off).
They deployed the changes to production this morning and immediately starting throwing errors (same error I sent)
Mgr messaged me a little while ago "Did you make any changes to the documentation service? We're getting this error .."
50% sure someone misspelled something in a config, but only thing they are logging is 'Unable to parse document'. Nothing that indicates an issue with the service they're using.2 -
Is your code green?
I've been thinking a lot about this for the past year. There was recently an article on this on slashdot.
I like optimising things to a reasonable degree and avoid bloat. What are some signs of code that isn't green?
* Use of technology that says its fast without real expert review and measurement. Lots of tech out their claims to be fast but actually isn't or is doing so by saturation resources while being inefficient.
* It uses caching. Many might find that counter intuitive. In technology it is surprisingly common to see people scale or cache rather than directly fixing the thing that's watt expensive which is compounded when the cache has weak coverage.
* It uses scaling. Originally scaling was a last resort. The reason is simple, it introduces excessive complexity. Today it's common to see people scale things rather than make them efficient. You end up needing ten instances when a bit of skill could bring you down to one which could scale as well but likely wont need to.
* It uses a non-trivial framework. Frameworks are rarely fast. Most will fall in the range of ten to a thousand times slower in terms of CPU usage. Memory bloat may also force the need for more instances. Frameworks written on already slow high level languages may be especially bad.
* Lacks optimisations for obvious bottlenecks.
* It runs slowly.
* It lacks even basic resource usage measurement.
Unfortunately smells are not enough on their own but are a start. Real measurement and expert review is always the only way to get an idea of if your code is reasonably green.
I find it not uncommon to see things require tens to hundreds to thousands of resources than needed if not more.
In terms of cycles that can be the difference between needing a single core and a thousand cores.
This is common in the industry but it's not because people didn't write everything in assembly. It's usually leaning toward the extreme opposite.
Optimisations are often easy and don't require writing code in binary. In fact the resulting code is often simpler. Excess complexity and inefficient code tend to go hand in hand. Sometimes a code cleaning service is all you need to enhance your green.
I once rewrote a data parsing library that had to parse a hundred MB and was a performance hotspot into C from an interpreted language. I measured it and the results were good. It had been optimised as much as possible in the interpreted version but way still 50 times faster minimum in C.
I recently stumbled upon someone's attempt to do the same and I was able to optimise the interpreted version in five minutes to be twice as fast as the C++ version.
I see opportunity to optimise everywhere in software. A billion KG CO2 could be saved easy if a few green code shops popped up. It's also often a net win. Faster software, lower costs, lower management burden... I'm thinking of starting a consultancy.
The problem is after witnessing the likes of Greta Thunberg then if that's what the next generation has in store then as far as I'm concerned the world can fucking burn and her generation along with it.6 -
My God is map development insane. I had no idea.
For starters did you know there are a hundred different satellite map providers?
Just kidding, it's more than that.
Second there appears to be tens of thousands of people whos *entire* job is either analyzing map data, or making maps.
Hell this must be some people's whole *existence*. I am humbled.
I just got done grabbing basic land cover data for a neoscav style game spanning the u.s., when I came across the MRLC land cover data set.
One file was 17GB in size.
Worked out to 1px = 30 meters in their data set. I just need it at a one mile resolution, so I need it in 54px chunks, which I'll have to average, or find medians on, or do some sort of reduction.
Ecoregions.appspot.com actually has a pretty good data set but that's still manual. I ran it through gale and theres actually imperceptible thin line borders that share a separate *shade* of their region colors with the region itself, so I ran it through a mosaic effect, to remove the vast bulk of extraneous border colors, but I'll still have to hand remove the oceans if I go with image sources.
It's not that I havent done things involved like that before, naturally I'm insane. It's just involved.
The reason for editing out the oceans is because the oceans contain a metric boatload of shades of blue.
If I'm converting pixels to tiles, I have to break it down to one color per tile.
With the oceans, the boundary between the ocean and shore (not to mention depth information on the continental shelf) ends up sharing colors when I do a palette reduction, so that's a no-go. Of course I could build the palette bu hand, from sampling the map, and then just measure the distance of each sampled rgb color to that of every color in the palette, to see what color it primarily belongs to, but as it stands ecoregions coloring of the regions has some of them *really close* in rgb value as it is.
Now what I also could do is write a script to parse the shape files, construct polygons in sdl or love2d, and save it to a surface with simplified colors, and output that to bmp.
It's perfectly doable, but technically I'm on savings and supposed to be calling companies right now to see if I can get hired instead of being a bum :P14 -
For some project, I wrote this algoritem in Java to parse a lot of XML files and save data to database. It needs to have some tricks and optimisations to run in acceptable time. I did it and in average, it run for 8-10 minutes.
After I left company they got new guy. And he didn't know Java so they switched to PHP and rewrote the whole project. He did algorithm his way. After rewrite it run around 8 hours.
I was really proud of myself and shocked they consider it acceptable.4 -
Had a bad day at work :( They gave me this code for some obscure streaming job and asked me to complete it. Only after 3 days did I realize that the LLD given to me was incorrect as the data model was updated. Another 2 more days, I was able to debug the code and run it successfully— I was able to parse the tables and generate the required frame but not able to stream it back to the output topic as per the LLD. That’s where I needed help but none of my emails/messages were replied to. The main guy who is pretty technical scheduled a code review session with me— I expected that I would run the code and he would spot it something I might’ve missed and why my streaming function isn’t working. Instead, what happened was that he grilled me on each and every line of the code (which had some obscure tables queried) and then got super mad at me saying “Why are we having this code review session if your code is not complete?”. I’m like bruh, you asked for it, and yes, the main parsing logic is done and I’m just having this issue in the last part. And he’s like “Why didn’t you tell me earlier?”. Wtf?! I left at least 5 emails and a dozen messages. He’s like this has to go live on Monday, and I’m like Ok, I’ll work in the weekend. And he’s like “Don’t tell me all these things! You’re not doing me a favor by working on weekends! How am I to ask my colleagues to connect with you separately on Saturday/Sunday? You should have done the on the weekdays itself. What were you doing this whole week?”. Bruh, I was running the code multiple times and debugging it using print statements. All while you were ignoring my attempts to reach out to you. SMH 🤦♂️ I can go on and on about this whole saga.4
-
After much muttering about making a program to parse regular expressions into more human-readable English, I think I'm finally at the point that I'd like to invite you to try it out.
Notes:
- I do not claim this is perfect. I know for a fact there are things I haven't added yet -- hexadecimals, for example. *shudder* -- and I'm sure there are edge cases I haven't figured out yet
- I would welcome any feedback.
- Please be kind.
https://github.com/AmyShackles/...8 -
Co-worker: "I'm getting files from customers which are in multiple types and encodings. Is there a way to force them to send only us-ascii so my tool gets only one kind which is easier to parse?"
Me: "Welcome to programming with arbitrary sources; you'll just have to build your tools to figure it out and not break (just rely on dozens of existing tools which you refuse to use)"1 -
This utilization shit is stupid! Seriously man what the hell! Yes yes it's an important number yes yes I don't even care. You want me to increase my utilization and at the same time be wary of the budget, which are unrealistically tight to begin with. It's freaking impossible! Who comes up with this shit?
You know what? Half of this shit ain't even my fault! A project was set for 200 hours and a guy wasted half of that trying to figure out just HOW TO CONNECT TO THE API! Like the guy only wrote 30 lines in 100 HOURS! ARE YOU FREAKING KIDDING ME! THEN YOU PASS OVER THE PROJECT TO ME AND SAY YOU HAVE ONLY 100 HOURS LEFT TO CONNECT TO THE API, GET THE DATA (WHICH BTW DOESNT EVEN EXIST), PARSE IT, AND THEN CREATE GRAPHS AND A FULLY FUNCTIONAL SOFTWARE, WITH A USER INTERFACE THAT SHOULD RUN AS AN EXECUTABLE!!!! ME? ALONE?
MAN FUCK YOU!2 -
Bad: Delete your production database
Good: Have a backup
Bad: Can't reimport it because your backup procedure uses scheme that are no longer supported for import by your cloud provider
Good: Backup are plaintext and somehow easy to parse
Bad: Spending the rest of the day writing scripts to reinsert everything.
End of the story: everything is up and running, 8hours of efforts1 -
I fix antique code for a living and regularly come across code like this, and this is actually the good stuff!
Worst usecase for a goto statement? What do you think?
int sDDIO::recvCount(int bitNumber){
if (bitNumber < 0 || bitNumber > 15) return 0; //ValidatebitNumber which has to be 0-15
//Send count request
if (!(send(String::Format(L"#{0:X2}{1}\r", id, bitNumber)) && flushTx())){
bad: //Return 0 if something went wrong
return 0;
}
String^ s = recv(L"\r"); //Receive request data
if (s->Length != 9) goto bad; //Validate lenght
s = s->Substring(3, 5); //Take only relevant bits
int value; //Try to parse value and send to bad if fails
bool result = Int32::TryParse(s, value);
if (!result) goto bad;
int count = value - _lastCount[bitNumber]; //Maximumpossible count on Moxa is 65535.
if (count < 0) count += 65536; //If the limit reached, the counter resets to 0
_lastCount[bitNumber] = value; //This avoids loosing count if the 1st request was
//made at 65530 and the 2nd request was made at 5
return count;
}4 -
The primary concept of reactive programming is great. The idea that things just naturally re-run when anything they rely on is changed is amazing. Really, I think it's the next step in programming language development and within a decade or two at least one of the top 5 programming languages will be built entirely on this principle.
BUT
Expecting every dependency to be used unconditionally is stupid. Code that checks everything it might need all the time even if a decision can be made from much less information is simply bad, inefficient code. If you want to build a list of dependencies automatically, you have to parse the source.
And I really hate that there are TONS of languages that either make the AST readable at runtime or ship with a very powerful preprocessor that could be used to analyse expressions and build dependency lists, but by its sheer popularity the language we're trying to knead into something it was never and still isn't meant to be is JavaScript.3 -
So I was designing a transformer and was looking up toroidal cores. The one I had in mind was made of a material the manufacturer calls “3E5”. Looking for a material datasheet I found a website with a download link for a material “300000”…
Dear web devs: How the fuck is that even possible? I can see what happened here but who thought whatever they were doing there was a good idea?9 -
Working on an Android app for a client who has a dev team that is developing a web app in with ember js / rails. These folks are "in charge" of the endpoints our app needs to function. Now as a native developer, I'm not a hater of a web apps way of doing things but with this particular app their dev teams seems to think that all programming languages can parse json as dynamically as javascript...
Exhibit A:
- Sample Endpoint Documentation
* GetImportantInfo
* Params: $id // id of info to get details of
* Endpoint: get-info/$id
* Method: GET
* Entity Return {SampleInfoModel}
- Example API calls in desktop REST client
* get-info/1
- response
{
"a" : 0,
"b" : false,
"c" : null
}
* get-info/2
- response
{
"a" : [null, "random date stamp"],
"b" : 3.14,
"c" : {
"z" : false,
"y" : 0.5
}
}
* get-info/3
- response
{
"a" : "false" // yes as a string
"b" : "yellow"
"c" : 1.75
}
Look, I get that js and ruby have dynamic types and a string can become a float can become a Boolean can become a cat can become an anvil. But that mess is very difficult to parse and make sense of in a stack that relies on static types.
After writing a million switch statements with cases like "is Float" or "is String" from kotlin's Any type // alias for java.Object, I throw my hands in the air and tell my boss we need to get on the phone with these folks. He agrees and we schedules a day that their main developer can come to our shop to "show us the ropes".
So the day comes and this guy shows up with his mac book pro and skinny jeans. We begin showing him the different data types coming back and explain how its bad for performance and can lead to bugs in the future if the model structure changes between different call params. He matter of factually has an epiphany and exclaims "OHHHHHH! I got you covered dawg!" and begins click clacking on his laptop to make sense of it all. We decide not to disturb him any more so he can keep working.
3 hours goes by...
He burst out of our conference room shouting "I am the greatest coder in the world! There's no problem I can't solve! Test it now!"
Weary, we begin testing the endpoints in our REST clients....
His magic fix, every single response is a quoted string of json:
example:
- old response
{
"foo" : "bar"
}
- new "improved" response
"{ \"foo\" : \"bar\" }"
smh....8 -
sr: XML is difficult format parse PDF instead.
me: (-_-)ゞ゛
checks code...
foo.fooBar = element
.match("<XMLELement>(.*)</XMLElement>")[1]
?.trim();
me: (☉_☉)7 -
Finding out how not to do it.
An example, learning how to parse HTML, and finding a stackoverflow post with the answer "use regex" triggers tech junkies so much that they actually comment a mostly accepted way of doing something.3 -
I don't get it.
I tried Kotlin on Android just for fun, and it doesn't support binary data handling, not even unsigned types until the newest version. Java suffers from the same disease.
How does one parse and process binary data streams on such a high end system? Not everything is highlevel XML or JSON today.
And it's not only an Android issue.
Python has some support for binary data, and it's powerful, but not comfortable.
I tried Ruby, Groovy, TCL, Perl and Lua, and only Lua let's you access data directly without unnecessary overhead.
C# is also akward when it comes to data types less than the processer register width.
How hard can it be to access and manipulate data in its natural and purest form?
Why do the so called modern programming language ignore this simple aspect that is needed on an everyday basis?10 -
Dockers JSON output is garbage.
First, you'll get no JSON per se.
You get a JSON string per image, Like this:
{...} LF
{...} LF
{...} LF
Then I tried to parse the labels.
It looked easy: <Key>=<Value> , delimited by comma.
Lil oneliner... Boom.
Turns out that Docker allows comma in the value line and doesn't escape it.
Great.
One liner turns into char by char parser to properly tokenize the Labels based on the last known delimiter.
I thought that this was a 5 min task.
Guess what, Docker sucks and this has turned into try and error...
For fucks sake, I hated Docker before, but this makes me more angry than anything else. Properly returning an parseable API isn't that hard :@3 -
Can we all just agree to stop actively imagining progressively harder to parse CSV formatting options? For fucks sake I’ve had to build in tolerance for quoted and unquoted data, combined data and split data, ways to split the data and recombine it, compare every data point, filter some data, only add data, only remove data, base data updates on non Boolean fields in the file, set end point matching based on arbitrary fields, column number matching, header matching, manipulate malformed urls and reassemble the file with proper ones, it goes the fuck on. CSV’s should just be simple and not hard to format. Why does everyone want to try so fucking hard to do bizarro shit?!
-
Vodafone India is so shit omfg
Run npm install, ERROR json parse error due to ssl exception
Run pip install, again ssl exception
Run gradle build, again ssl exception!!!
Now everytime i gotta make a new project or install a dependency in anything, i have to pray to the blood god that cache contains a valid/uncorrupted package dependency or else ill have to nuke cache and borrow internet from someone else.
Once i port it to some other operator, i am gonna incinerate this mf sim.12 -
API response.
For a week been working with my project manager remotely.
Then yester night had a tough one.
Me:Please send me the API endpoint so that can test it and see the response.
Him:On my side all is set just consume the response.
Me:As a practice I did first test the API using postman and the response was okay.
Me:As I had already prepared my Retrofit code to consume and parse the response I head to it.
Me:Fast forward 20 minutes into the application I realise getting some unexpected errors thanks to the guy who didn't follow my response format.
Me:I call him asking him to check how he formatted the response .
Him:He claims he formatted it as requested .
Me: Double check my work and am damn right and now raise my voice as I talk to him again and requests him to send me a screenshot of his response and I send mine.
From the screenshots turns out his response is okay as he is working from a damn localhost and my response was coming from the live server.
Feel like strangling him for wasting my previous 30 minutes2 -
If your site uses angular or react or some other piece of shit framework to load the data after the site has fucking loaded, make a public fucking api because i cant parse your shitass website from source.3
-
For God's sake why can't you just keep consistency across your fucking files? I have to parse 3 different XML files from the same source where I have "ZipCode", "zipCode" and "Code" for the same thing.
Not to mention that the file that contains all the streets in the country have literally one street node for every motherfucking street. Not one city parent and multiple street children that would make sense and would be faster to parse, but clearly that wasn't your intention you retarded cunt.2 -
Someone around here once said that they believe that Rust compiler errors are generated by first sending the compiler noise to some dude in India and then they parse the errors and send them back to the compiler.
This was not a nod against our friends from the land of India, but instead, I think, a praise.
Thus I would like to add a request to the rust devs to see if they could include more "trademark Indian" sassy remarks in the messages that the compiler generates. But I am afraid that they think I am being racist or something.
For reference: My Indian friends are all beyond sassy in the way they clap back at mfkers when having friendly arguments, I have been left with a "well, damn" in multiple occasions because I am incapable of reaching that level of sass myself.9 -
This is a general question to freelancers or devs who works on only projects, is this worth only £100 pounds:
A survey website with 19 pages. Questions changes based on previous answers. Must have drag and drop, mix and match functionality. It must be mobile friendly as well.
And we have to parse the data we get from survey to a nicely rendered webpage so the client can see it.
The deadline is 2 days10 -
As a new freelancer I didn't have much clients , so I paired with a web designer +10 years exp. who work with me as a pm and that was a bad decision.
Although I am a back-end dev , half of the projects were frontend/WordPress theme (less price than back-end projecrs) - so 30% of the projects were cancelled .
sometimes I receive project's which have requirement, like magento, I don't know anything about ,
I tried to push myself but I burned out after six month.
he deals with clients, partner with other companies ,and I don't know anything about the terms.
at the end I was like an employee without any benefits from his company .
moreover I get my money after 45 day!!!
and not all my money .
this is a project I work for another company through him
A requirement for mobile back-end server was integrating with parse and that was my first time working with Facebook parse so ....
after two weeks ..
we received email from parse that they'll shutdown their service after a year .
so we moved to Amazon sns again my first time working with aws .
at the end I can't charge for extra money but my pm became a gold partner for that company .
the only thing that made me hold is that I need some high quality projects for my c.v.
-----------
he didn't show on hangout because I need my money .
this will be my last project with him.
wow I write too much ... I feel better now .😥1 -
I don't think I've been more excited about anything than my very first application.
This was when I was just starting out with programming. I had chosen C++ as my first programming language.
A friend and I'd written a simple application to fetch XML data from a sports data server, parse it and display our favourite football (soccer, for Americans) team's fixtures and results on a GUI.
We called it Sportify. -
Which misanthropic, terrible, perverse excuse for a dogfucker decided that damned non breaking spaces (SPACES!) return false on isWhitespace? It's in the name, space, it's white, it's a fucking white space, a whitespace if you will so who do I have to kill for wasting two damned hours of my life trying to parse away those bastards?3
-
So I just spent 2 hours debugging a script that fetches data from an API. Thats all it was supposed to do. Http get some data.
It wasnt working and was giving a "parse error". Worked fine in browser.
So it turns out it was using http 0.9 (first documented http version, defined in 1991) and wasnt sending any headers. And js cant do no headers...
So yea I now have to write a tcp / http 0.9 client in js10 -
I like my log messages to indicate automatically where in the code something happened, so that I can easily identify where a message originated from while tracking down problems.
In C/C++ this is nice and easy - write a logging routine, wrap it in macros for the different log levels and have that automatically output __FILE__, __LINE__ etc.
I wanted to do something similar in NodeJS, as I'd found myself manually writing the file name in the log message and then splitting functionality out into new files and it became a mess.
The only way I found to be able to do this was to create an "Error" object and access the "stack" member of it. This is a string containing a stack backtrace, suitable for writing to console/file. I just wanted the filename/line/routine.
So I ended up splitting the string into lines, then for each of the lines, trimming the surrounding spaces (or tabs?), and parsing them to see if the stack entry is inside my logger module. The first entry outside of that module must therefore be the thing that called it, so I then parse out the routine or object and method, filename and line number.
It's a lot of clumsy work but the output is pretty neat. I just wish it were simpler!2 -
Dear developer guy who wrote this documentation node!
You're a developer yourself. Don't you know that inverse psychology is something you should avoid, because it will not work?
Thanks!
---
Okay for real, why shouldn't one parse Build.FINGERPRINT on Android? I was looking for a way to determine if the device is an emulator or not, and came across a solution using this, and read the documentation. 1
1 -
About 4-5 hours ago I wanted to make simple websocket to get input from textarea and parse it on server and somehow got myself into developing in asyncio -> aiohttp -> graphql-core -> graphql-ws -> aioredis
and svelte-> typescript
I still didn’t make the stuff I wanted but I’m very close on backend at least.
I have some frontend part somewhere in my old prototypes so it will be faster if I figure out svelte.
Still don’t understand what the fuck just happened.
Maybe it’s because I wanted try those frameworks for a long time.
All ‘simple’ examples I found have around 20-30 files for backend and same amount for frontend so more then 50 files to get this shit working.
They’re called oh irony “simple chat”.
Now I see why no one fucking understands this shit.
I’m trying to cut mine to 5 files.
I thought developers are lazy bastards who don’t like write code.
But now after this they’re all looking like adhd coders.
Looks like Monday won’t be my best day.9 -
Im a junior android dev working in a startup. Wasted whole week on trying to parse some retarded json data generated by junior backend guy.
Im talking about objects with other objects as their elements, no use of arrays.
In the end had to redo his data in proper order so I could parse properly. Fkin waste of time.
At least now I know how to do his work, and won't be afraid to confront him with detailed criticism.2 -
Unreal Engine + third party library adventures part2:
now we gotta parse everything from unreal formats, to the library formats, than back to unreal again... sigh. Why can't it just use normal data formats like everybody else? I mean, come on, strings, ints, vectors etc. they all have standart libraries. why does unreal need to make their own shiet out of it. Just why...1 -
We recently hired a new developer, fresh from uni. Very little real experience as I can see.
Unfortunately I weren't available for the interviews, so they chose a dev without me.
All his code is messy, over complicated and uses symfony framework for _everything_
He can't do shit outside of it.
He was tasked to find and replace some links in a few hundred excel documents, he spent ages trying to parse the xlsx documents and the replace the links and write to the document. Spent all day on it, with no results. Even though I often asked him how he was getting on, he said all was fine.
End of day, I get a tad furious, whip out my terminal and do the whole task in 10 minutes with basic bash4 -
Currently modifing a old Excel VBA Application. Found code which try to parse a Textbox on every change. If its a valid Number, it saves the value into a label. When saving the form the label will be parsed and validated instead of the Textbox
-
So, I'm looking into something and end up on Stack Overflow. Someone posted the question:
"Does minified javascript improve performance?"
This question was old as shit, all they way from 07/25/09, and about an Adobe Air application. (Remember that? Me neither...) It had a great, accepted, and still accurate answer, posted the same day the question was asked. Now, fast forward 8 years and on 12/08/17 (A mere 7 months ago...) the following answer was posted. I don't know what they were thinking, but here it is, complete and unabridged, with my comments in square brackets:
"I'd like to post this as a separate answer as it somewhat contrasts the accepted one: [Somewhat contrasts? More like completely contradicts...]
Yes, it does make a performance difference as it reduces parsing time - and that's often the critical thing. For me, it was even just simply linear in the size and I could get it from 12s to 4s parse time by minifying from 3MB to 1MB. [First off, your parse time should NEVER be THE critical thing, but secondly, and more importantly, WHO THE FUCK HAS 1MB OF MINIFIED JS ON A PAGE!!!]
It's not a big app either, it just has a couple of reasonable dependencies. [THERE IS ABSOFUCKINGLUTELY NOTHING REASONABLE ABOUT ANYTHING HE JUST SAID! What dependancies is he using?! You could use minified and not even gzipped jQuery, AngularJS, Vue, Ember, React, AND Dojo libraries on the SAME PAGE, AND have 118k of application code, AND STILL NOT HAVE HIT 1MB QUITE YET!!!]
So the moral of the story here is: Yes, minifying is important for performance - and not because of bandwidth, but because of parsing. [Javascript should NEVER take longer to parse then to download, even on a low powered device...]"
So, yeah, I'm at a loss for what this guy was thinking, but the thought the people like this exist, and that my browser might one day be subjected to their horrific nightmare of code terrifies me...2 -
Does anyone find the laravel documentation just lacking? It seems like it the twitter feed of documentation leaving out very important information that leaves me banging my head for hours. I really like laravel and much better than working with raw php but I wish there was an option in the drop down for additional a more flushed out version with more code examples. I understand experts don't want to parse through tons of text just to find the correct artisan command but c'mon.5
-
Trying to parse JSON to case classes and vice versa is like trying to parse HTML with regexes: A straight way to hell.
TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝S̨̥̫͎̭ͯ̿̔̀ͅ1 -
Apache why???
Your projects' page let's me view all the projects sorted by category, language, etc.
https://projects.apache.org/project...
But I can't view a description... I have to open the link...
Starts writing a scraper and realizes the project list is not static, it's loaded from a JSON document using JS... The document has all the descriptions and other info...
WHY THE FUCK DO YOU NOT SHOW THIS ON THE PAGE BUT MAKE EVERYONE OPEN ANOTHER PAGE SEE THEM...
Spends an hour writing an app in C# to parse the json because a simple Flattener isn't good enough because of the structure...
Probably going to end up creating a GUI so I can browse it more easily and Star the ones I may be interested in...3 -
That feeling when you’re working on writing a program to take differently based numbers, parse the input character by character, and return the value in different bases (dec, binary, hex, etc), get stuck, ask your partner to take a look at it and their response is along the lines of “What are you even DOING?! That doesn’t even make sense.”3
-
Trying out the new version of fasm, I realize it's good, and conclude I should update my code to work with it as there's small incompatibilities with the syntax.
So, quick flat assembler lesson: the macro system is freaking nuts, but there are limitations on the old version.
One issue, for instance, is recursive macros aren't easily possible. By "easily" I mean without resorting to black magic, of course. Utilizing the arcane power of crack, I can automatically define the same macro multiple times, up to a maximum recursion depth. But it's a flimsy patch, on top of stupid, and also has limitations. New version fixes this.
Another problem is capturing lines of code. It's not impossible, again, but a pain in the ass that requires too much drug-addled wizardry to deal with. Also fixed in new version.
Why would you want to capture lines of code? Well, because I can do this, for instance:
macro parse line {
··match a =+ b , line \{
····add a,b;
··\}
};
You can process lines of code like this. The above is a trivial example that makes no fucking sense, but essentially the assembler allows you define your own syntax, and with sufficient patience, you can use this feature to develop absolutely super fucking humongous galactic unrolls, so it's a fantastic code emitter.
Anyway, the third major issue is `{}` curlies have to be escaped according to the nesting level as seen in the example; this is due to a parser limitation. [#] hashes and [`] backticks, which are used to concatenate and stringify tokens respectively, have to be escaped as well depending on the nesting level at which the token originates. This was also fixed.
There's other minor problems but that gives you sufficient context. What happens is the new version of fasm fixes all of these problems that were either annoying me, forcing me to write much more mystical code than I'd normally agree to, and in some rare cases even limiting me in what I could do...
But "limiting" needs to be contextualized as well: I understand fasm macros well enough to write a virtual machine with them. Wish I was kidding. I called it the Arcane 9 Machine, A9M for short. Here, bitch was the prototype for the VM my fucking compiler uses: https://github.com/Liebranca/forge/...
So how am I """limited""", then? You wouldn't understand. As much as I hate to say it, that which should immediately be called into question, you're gonna have to trust me. There are many further extravagant affronts to humanity that I yearn to commit with absolute impunity, and I will NOT be DENIED.
Point is code can be rewritten in much simpler, shorter, cleaner form.
Logic can be much more intricate and sophisticated.
Recursion is no longer a problem.
Namespaces are now a thing.
Capturing -- and processing -- lines of code is easier than ever...
Nearly every problem I had with fasm is gone with this update: thusly, my power grows rather... exponentially.
And I SWEAR that I will NOT use it for good. I shall be the most corrupt, bloodthirsty, deranged tyrant ever known to this accursed digital landscape of broken souls and forgotten dreams.
*I* will reforge the world with black smoldering flame.
*I* will bury my enemies in ill-and-damned obsidian caskets.
And *I* will feed their armies to a gigantic, ravenous mass grave...
Yes... YES! This is the moment!
PREPARE THE RITUAL ROOM (https://youtube.com/watch/...)
Couriers! Ride towards the homeland! Bring word of our success.
And you, page, fetch me my sombersteel graver...
I shall inscribe the spell into these very walls...
in the ELEVENTH degree!
** MANIACAL EVIL LAUGHTER ** -
I'm doing work during the weekend. Just to parse this line of json.
Argh, what drive me nuts is after discovering that json response wasn't proper.
*sample - from what i seen*
{
head= {
data=value,
data=value,
}
}
This is my first time seeing json response with =. Since my assignment is to retrieve the response.
I cheated by calling replace over and over to correct the string of response to correct json format.
That is actually production stuff. Knowing that makes me sick to the stomach.7 -
Me: *randomly streaming myself code just because*
Friend: "So what are you doing"
Me: "I'm trying to parse a file. The specs are here - oh"
Friend: "Oh?"
Me: "I set screenshare to vs code only, so you can't see it"
Friend: "It's alright, just pass me the link"
Me: "Well, this is vs code, so I might as well check if it can display websites"
Friend: "No way you'd need that,"
>browser
* simple browser
Friend: "Please no"
"Enter url here"
Friend: "Stop!"
*loads website*
Friend: *dies of bloat*
Me: "All hail the bloat"
Friend in heaven: "Stop, your bloat will drag me down to hell"
So yeah, bloat can be useful sometimes4 -
The feature was to parse a set of fairly complex xml files following a legacy schema. Problem was, the way this was done previously did not conform to the schema so it was a guideline at best, which over the course of many years snowballed into an anarchy where clients would send in whatever and it was continuously updated per case as needed. They wanted to start enforcing their new schema while phasing out the old method.
The good news is that parsing and serialization is very testable, so I rounded up what I could find of example files and got to work. Around the same time I asked our client if they had any more examples of typical cases we need to deal with, and sure enough a couple of days later I receive a zip with hundreds of files. They also point out that I should just disregard the entire old set since they decided to outright cut support for it after all if it makes things simpler. Nice.
I finish the feature in a decent amount of time. All my local tests pass, and the CD tests pass when I push my branches. Once we push to our QA env though and the integration tests run, we get a pass rate of less than 10%.
I spend a couple of days trying to figure out what's going on, and eventually narrow it down to some wires being crossed with the new vs. old xml formats. I'm at a loss. I keep trying to chip away at it until I'm left with a minimal example, and I have one of those lean-back moments where you're just "I don't get it". My tests pass locally, but in the QA environment they fail on the same files.
We're now 3 people around my workstation including the system architect, and I'm demonstrating to the others how baffling and black magic this is. I postulate that maybe something is cached in my local environment and it's not actually testing the new files. I even deleted the old ones.
"Are you sure you deleted the right files?"
"Duh of course -- but let me check..."1 -
Half a year or so ago I threw together a quick site for an old teacher of mine. Got a bit of cash for it and all was good. Now he needs a few changes, plus a whole new interactive page. Oh well... I restructured the whole thing and wrote a bare bones templating system in PHP. It can parse markdown files, so now he can fix his own fucking spelling errors. So now the shitty piece of crap is maintainable. Thanks fucking God for that.
-
Client be like:
Pls, could you give the new Postgres user the same perms as this one other user?
Me:
Uh... Sure.
Then I find out that, for whatever reason, all of their user accounts have disabled inheritance... So, wtf.
Postgres doesn't really allow you to *copy* perms of a role A to role B. You can only grant role A to role B, but for the perms of A to carry over, B has to have inheritance allowed... Which... It doesn't.
So... After a bit of manual GRANT bla ON DATABASE foo TO user, I ping back that it is done and breath a sigh of relief.
Oooooonly... They ping back like -- Could you also copy the perms of A on all the existing objects in the schema to B???
Ugh. More work. Lets see... List all permissions in a schema and... Holy shit! That's thousands of tables and sequences, how tf am I ever gonna copy over all that???
Maybe I could... Disable the pager of psql, and pipe the list into a file, parse it by the magic of regex... And somehow generate a fuckload of GRANT statements? Uuuugh, but that'd kill so much time. Not to mention I'd need to find out what the individual permission letters in the output mean... And... Ugh, ye, no, too much work. Lets see if SO knows a solution!
And, surprise surprise, it did! The easiest, simplest to understand way, was to make a schema-only dump of the database, grep it for user A, substitute their name with B, and then input it back.
What I didn't expect is for the resulting filtered and altered grant list to be over 6800 LINES LONG. WHAT THE FUCK.
...And, shortly after I apply the insane number of grants... I get another ping. Turns out the customer's already figured out a way to grant all the necessary perms themselves, and I... No longer have to do anything :|
Joy. Utter, indescribable joy.
Is there any actual security reason for disabling inheritance in Postgres? (14.x) I'd think that if an account got compromised, it doesn't matter if it has the perms inherited or not, cuz you can just SET ROLE yourself to the granted role with the actual perms and go ham...3 -
Fuck Apache TIKA.
Its supposed to be a "universal file reader" or some shit. Im trying to use it as a PDF/image parser that does OCR when needed and yelds a full-file string. It does so, but the text ends up being IN THE WRONG FUCKING ORDER.
WTF would I want to parse the text out of a PDF in any order that is not the one the text is supposed to be read?!?!
"It is more efficient to work in random ordering", says the docs. No shit, really? Wouldn't it be even more efficient to just spit out random strings? Just as useful and 100% CPU-bound.
"You can add a property to forcefully put the text in the right order". THEN WHY THE FUCK IT IS NOT THE DEFAULT SETTING?
Srsly, what's the use case to a parser that yields scrambled text?!?1 -
!rant
I've tried Ionic in the past, and put off development with it because I couldn't get it to be performant without crosswalk.
In 2015, React Native put an end to the 'Are hybrid apps viable?' argument. It had a much smaller compile size, large component library, and is very reactive.
Ionic recently released news on scaling back their tools to focus on core offerings. I can't help but feel they're flogging a dead horse.
I'm sure the Ionic team has very smart people on board. Can't they see they're about to be 'Parse-ed'?1 -
So you're working on a product that basically the main thing it does is fire off http requests and parse their responses into a nice model. We've made some nice helper class that allows you to do this easily, but a simple piece of functionality is not in there yet.
You agree to add this one simple function and decide to:
- Not conform to coding standards set by the team
- Document its behavior which does NOT match the implementation
- Not write a single fucking unit test to prove it's functionality
ARE
...
YOU
...
FUCKING
...
MAD?! -
Question to the frontend devs: I'm currently trying to optimize part of our JS. How do sourcemaps influence loading/rendering Speed in the Browser?
In the `webpack.config.js` we use uglify as minimizer for js. It has the option `sourceMap` Set to `true`. Now as I understand it, this caused it to Inline a sourcemap inside the JS file (which leads to a slightly bigger file size and thus longer load time for the generated file...).
My Question: should sorcemaps be enabled for prod (minified) files? Why yes, why no? Do they help the browser parse the JS faster?12 -
Nothing gives me the feeling of power like solving my non-programmer friends' problems with a bit of programming.
My girlfriend is an architect, got at her job a task of designing how to cut facade panels. Something nearly impossible to do with her tools and insanely time consuming to do by hand - but it's actually just a subset-sum problem with more steps. After a couple of hours of tweaking the program to properly parse excel files she can export and writing the output in a format usable for her I solved what would be an incredibly tough pickle for her and her whole company.
I'm seriously proud of myself.1 -
I "fight" with another developer at the end of a school project (a website).
The "other developer" complained because he had received a lower rating than mine.
He went to the teacher telling them that I had to lower the evaluation because during the project I watched TV series, And the teacher replied: there are those who can do it and some like you do not.
He could not do it because when he concentrated he could not do anything, you think when he lost himself in TV series.
There were various quarrels because I had this attitude but a higher rating (and anyway with a product a thousand times better than his), while he gave 100% he could not do anything.5 -
Is devRant coded in Objective-C or Swift? Is the backend through Parse, Firebase, etc.? It seems to be a smooth app.7
-
It is great feeling, to leave company and leave all your crap code to others :D
500 lines bash generic wrapper to curl (just to catch and print errors, not just silently fail as most devs tell curl to do).
It was monster that used "function overload" and "subclasses" (based on dynamic source files). Also dynamically created inline AWK script to parse curl output. It kinda worked, but amount of high-level hacks I had to use was enormous.
Never use Bash when you do not have to. Even if you have experience with it. Others don't have it and will fail miserably trying to patch your code. Just leave bash for fast bridging between programs, leave python/java/c#/go or any other proper OOP language for a job. Please ? -
I was tinkering around with my linux installation and trying to decide on a new terminal to use, and I ended up compiling st (suckless terminal). On a whim, I decided to look through the source code and see how much of it I would understand.
There was a C header file called arg.h that uses the preprocessor and macros to parse argument flags and songs by setting up a switch statement in a loop, all in under 50 LoC. To use it, just wrap the switch body between ARGBEGIN and ARGEND, and that's it. The comment at the top simply read "copy me if you can", a challenge to future programmers such as myself.
It was the most beautiful, elegant solution I have ever seen. I tried to tell my girlfriend about it, but she just didn't get it. Maybe some of you will appreciate it more:
https://github.com/chjj/st/... -
This may be obvious, but debugging is all about input / algorithm / output. If there's something wrong, it's one of the three. Work with the method of elimination. Sometimes it's easy, sometimes it's not.
I'll give you an example from my situation:
I wanted to play an old DOS game on my modern PC and so I used DosBox. I made an iso from the original CD, mounted it, referred to it in the game's mount settings and launched the game.
Then, after I had saved the game and I tried to load it again, the game would say: "Could not read/write savegame". And so I thought something was amuck with my mount settings and I started fiddling with those, but it only made it worse and it gave me more (cryptic) errors.
The next approach was to save a new game and load that one. Nope, same problem.
Finally I decided to follow a DosBox tutorial for the game and load the game again.. same problem. So I think hmm.. my algorithm is correct.. my output is wrong.. so then my input must be wrong. So I decided to save the game again with these new and correct settings and low and behold, it finally loaded.
One thing to note was that when it failed to load the savegame, it was because it had done a partial save because due to incorrect mount settings it couldn't figure out all the right config folders/files/paths and my savegame ended up being corrupt with 80% of the files having 0 Bytes, which was suspicious. That usually means a file became corrupt.
And then it hit me.. if the game says: "Could not read/write", that doesn't mean the same as "Could not access the file/folder". It could access it, it just couldn't parse it. And of course.. the 'write' part of the message indicates that it messed up in writing, causing it to misread. Sometimes you really have to think about it..
Anyway, input, algorithm, output. :) -
"Go check out the EAGLE documentation so you know how to properly parse its generated xml files"
(The whole docs just says "sorry, no documentation" every fucking where, not just the part in the picture...) 3
3 -
Microsoft certsrv is returning UTF-8 on the authorization error page but UTF-16 when logging in via basic auth...
Debugged this for 2 hours today to parse the response correctly. Thanks Microsoft -
Nobody wants to maintain XSLT mappings. Being a developer, even I don't want to. So what do we do? We parse the XSLT using JAVA code in a horrible attempt create an excel with mappings. God damn it!!1
-
The fact that you have to write "__" at the start of a variable name of a class to make it private (IntelliSense is not able to parse that. So you just "cannot see" that thing, but you can use ist) tells you everything about a language that you need to know...
-
DAILY LARAVEL PROBLEMS
I need to parse a JWT with some custom claims. There's a JWT library with Laravel; documentation really lacking, kinda hardcoded to work with Laravel but whatever; it's already installed, let's see what can I do with it.
It turns out I can't say something like "take this token, parse it, tell me it's valid". Let's see how that goes.
You need to build a parsing class with a manager, some auth stuff, a parser.
To build said manager you need a provider that implements a contract, a blacklist, a factory (of what?)
To build the factory (of what?) you need a claim factory and a payload validator
To build the claim factory you need a request
To build the blacklist you need a Storage
To build the storage you need a CacheContract
To build a CacheContract you need IDK it's a mess
To build the contract you need... IDK for real
WHY LARAVEL IS SHIT: 'cause only in this framework it seems reasonable to build this clusterfuck to parse a base64 encoded string, throw some json_decode and check a signature. And have it work only to authenticate a user.1 -
Yesterday I asked a question on stack overflow about what algorithm I should use in order to parse command line strings like in gnu getopt for example.. And I've got downvoted for no GOOD FUCKING REASON. On top of that, my question is on hold. WTF?! For some time now stack overflow is becoming more and more a community of fucking cunts, arse-holes and toxic people.
Title:
" What parser algorithm is best suited for command line parsing? [on hold] "
My question:
"I want to write my own command line library from scratch. What algorithm should I use in order to parse gnu style args like in getopt for example ? I mean what's the best way other than tokenizing and parse them in a naive way? Should I try to look at LR, LL algorithms or this is way too overkill?"
Their response:
"Your question sounds like "I want to do X. What's the best way to do it?". Too broad, you need to be more specific about what problem you're having. (And keep your question clean. No meta-stuff in there.)"
I mean, what more context-specific reason should I add you dense motherfucker!? I want an algorithm to parse your momma's cunt so hard 'till it blows the fuck up. This what you want? You fucking senseless piece of garbage. God, give me a car to run over their fucking internet cable and over their head, too.7 -
Why is AWS so opaque? Every time I run into a new awkwardly name service I have to parse some redundant management speak to figure out what it does. Does it really matter to anyone that their services have special names with words like "Simple"?
-
I fucking hate people who uses complex words to describe something simple.
Describing a frame work
Show-off : "..you can define what objects/tables to expose, what values in that object you want to expose...if you are using some orm, then because you have models defined. Once you update your model, your endpoints get the new model..."
Simpleton : "something like parse..."
Wtf is 'fixedUUID'?
Show-off: "..hardcoded UUID is fixed (constant) value, with format of UUID, hardcoded UUID will be unique value between backend and frontend,
you will need to store it as constant value in your codebase ( we may encrypt/ decrypt it for security reasons)..."
Simpleton : "a secret password only u & I know"
--why whyyyyyyyyyy2 -
Budding Developer here...
I've tried to teach myself Web Dev over the past 10 yrs on/off... Sad. But now I'm actually in a developer role moved up from IT helpdesk a year ago.
In the past year I've learned SQL, SSRS, SSIS, database concepts, and.... VB6. I am a master at none due to having to cram so much in a year while taking on various projects, issues, and learning the organizations software infrastructure and processes. I also taught myself current HTML, CSS, and basic Javascript. Learning the different basic concepts with each.
Over the past couple months I've been given a new project and now learning ASP.NET and C#. Actually trying really hard to get adept at these as I'm finally doing Web Developing in my role...
I am also dealing with multiple major family issues and a near 2 yr old that we cosleep with that still doesn't sleep through the night.
Why the crap is it so easy to convert an enum to a string but takes 50 functions to convert a string to an enum???
Cast, convert, parse... Why so much logic???
When the online teacher says type why do I have to rifle through 7 different meanings in my head before I know what kind of type he's referring to??4 -
Why the hell do languages like Kotlin (Java) and C# handle dates and datetimes so needlessly complicated?
There are multiple types with different implementations and concepts like local time or time zones represented by those types. Some of them have capabilities like serialization, some of them don’t.
Parsing and encoding is tied to the types.
Why? Take Swift as an example:
It has one single Date type (including time) which represents a point in time independent of any calendar, time zone, encoding or format.
There is a DateFormatter to parse from APIs from iso or timestamps or whatever and to format to UI as a string in any language (localization), for any region, in any format.
If you just want a container for the date time components themselves (which the concept of local date time seems to be in those languages), you can use the DateComponents type. If you are interested in dates from the perspective of a calendar, there is a Calendar type.
Everything makes sense and the different concepts are decoupled from each other as they should be.
Damn! My memory about C# is a bit hazy but Kotlin, I’m disappointed in you! Date handling is a horrible mess!
Ok, I guess I can blame it on Java and JVM.6 -
-we have a huge nested object to represent this functionality.
- just save it in the DB under "settingsx" column as a stirng. No need for different columns
We had to parse it multiple times in the client and the server.
After a year in the company, I've managed to convince the team leader to move to json object at least2 -
So... I just got to the next fase where I'm being asked to do a technical test. What they ask is for me to develop an Android App with 4 different tabs:
- First tab I need to receive data from a github url, parse it and show it on a recyclerview, save it on a database, and be able to search it.
- Second tab has to show 50 elements in a recyclerview, with a header that has to fill the entire screen and when the user scrolls down, the image has to fix to the top of the screen, and never go back when you scroll up.
and two more exercises with variations but almost same difficulty.
..... to deliver at 10 a.m at the 26th of October.
......It was 07:00 p.m when I got the email
FUCK MY LIFE -
Disclaimer: I should know what I'm doing but I don't. 😢
I'm a very experienced full stack dev (15+ years), but I don't know the more modern JS frameworks. I'm trying to learn React and I have a little project I'd like to do.
I have database (in both SQLite form and JSON form). I'd like to read from it, parse it and run various displays in a shared hosting environment (that doesn't have node). So webpack. And either an API to get the data or a React compatible SQL component.
But dagnamit, I cannot find a tutorial or example with this kind of set up and I can't figure it out. What packages do I need and what kind of config?
I genuinely thought this would be a traditional and simple architecture but I'm obviously mistaken. And I'm about to turn in my developer card because I'm clearly a stupid twonk.
Has anyone done this? Do you know of any tutorials or examples of this kind of thing? Is there somewhere else I should ask this question? Thanks anyway...5 -
guide to make successful software house company for future me:
1.find shortest domain name with code / star / best / it / super / ai / - whatever banger word you find
2. parse companies work board / linkedin jobs
3. parse people profiles
4. setup email server and create fake linkedin profiles that match jobs and candidates so company looks big
5. fake c-level management so company looks big
6. spam likes and create posts generated by ai from multiple profiles
7. spam invitations to people that match job descriptions and to people working within companies posting jobs
8. offer fake candidates that match job description
9. find real but less promising candidates and offer them the job
10. tell that fake candidate is no longer available but you have someone better
success6 -
Why the fuck do I need an Accept, A content-type AND and responseType (which, by the way doesn't go with the rest of the request headers, it has to sit outside them just to fuck you up). Just so angular will stop trying to parse absolutely fucking every request as JSON?
I'm well aware my knowledge of http protocols and angulars apis's are not the best but for fuck sake. What dark book of secrets must I uncover to illuminate the strategies behind these choices?
Why, when the Accept type is text, the Content-Type is text. When the request itself is handwritten beautifully on parchment and sent via fucking carrier pigeon to the backend and returned by horse and carriage, does ANGULAR STILL TRY TO PARSE IT AS FUCKING JSON. JUST STOP.16 -
Hello ranters, I'm looking for advice in regards to a freelancing job which I haven't been paid.
In summary, I got a freelancing job in like March 2018, I had to do a simple platform with an administrator section, simple but "long", it had to be fully customizable, so I did it. I then got another project, which I also finished, both by December. I added some functionality not on the requirements and also some other asked by them, I also deployed both of them, tasks not included on the "contract". The problem is that I didn't sign a contract (my fault), it was all verbal. Since I was "friends" with them, I asked them to pay me with a motorbike (of around 2300 USD) and they agreed. Then they gave me another project which started wrong, they asked me to finish it within two weeks with a language I didn't know and other tools I also didn't know, I told them about this and agreed that could be a delay, besides, the requirements weren't totally clear and they were clarified three days after the project "started". After this, we had a discussion about how I later realized I was totally underpriced, that I hadn't been paid yet and how the dude that was like my main contact for the project told me that "my code was all nice and cool but was useless" because he clearly thought that an excel could be used as a database and din't know that I had to parse it and upload it to Firebase, which in total were about 4 million documents and this obviously took time. To not make it longer, I delivered the project 1 week later and they told me that they had to "assign" a full team of 7 members to do it from zero because I didn't deliver it on time and because when he asked me to "help them" I laughed. I first delivered like the 90%~95% of the project and he was been condescendent, he also blocked me from everywhere (hangouts, slack) and told me to "deliver what I had" to at least have something to prove that I did work. His team of "7 members" was stupid enough to not be able to at least run an npm install and npm run, they were also stupid enought to not understand what a GET request was an all and when he realized this, he asked me for the database dump and for the 100% of the project, so I also delivered it. We agreed that we were not going to work together anymore, so I asked him to pay me at least what had to be paid of the other two projects and he agreed, he also purchased a computer for me which I was paying him and was going to be discounted from the total payment. In the end, I was going to be paid 1430 USD. He asked me for my bank account and like my tax ID, for whatever he needed it. Since then, almost two weeks, he hasn't paid me, replied or even seen my messages. He also had a "partner" which was also "my friend", the huge motherfucker isn't even replying my mails or anything, so, since it was all verbal and they are being such motherfuckers, I don't know what to do. They are being such motherfuckers and I think I can't proceed legally, since there is no written contract. So what should I do? I was planning on going tomorrow but I pretty sure they won't even open the door or will tell me to wait or whatever. I seriously wanna cry, I don't get how people can be such dicks and unfair fuckers. I believe in karma but I don't think karma will give me that money and time back. :(9 -
Any Symfony expert here? I've got quite a tricky question, that I'd love to disqus with another dev.
It's about twig within symfony. I'd like to add a custom node parser, but not for an own tag, but to set some value on each template if it's not set (which can't be done with globals in this case!). I've thought about using a visitor, but from my understanding it gets executed to late, as it requires (probably) to modify the twig AST at compile/parse time.4 -
I decided to give a try to NetBeans to open a C project and see what was inside. NetBeans died trying to parse it, taking all my RAM. Goodbye NetBeans2
-
Have to upgrade Android app that connects to Bluetooth device and reads data.
I found the app creates new thread every line read from the device's Bluetooth stream, then reuses 1 object for every reading to store the state of the device in Jsonarray, then every thread creates a new thread to upload the data on cloud. Oh, I almost forget that is all working in one UI sctivity, and the same thread that parse the data updates the UI.
Deadline is next Monday and I don't know where to start editing my shit to place MY shit.
Fuck me I guess? -
I wanted to get the latest NASA APOD photo with Python. Easy, right? Nope! Firstly, their RSS feed is partly HTML, so feedparser doesn't understand it. Secondly, feedparser doesn't even get the titles of entries correctly.
Which is why I'm trying to parse it in a horrible way using Python regexp. NASA can put humans on Luna but not even get their RSS feeds to parse properly.2 -
My god why are all parser combinator libraries in Rust so bad??
Is it too much to ask for to parse a normal ass programming language with error recovery???? That's like 99.99% of what people need a parsing library for and somehow error recovery is always some weird after thought bandaged on after the fact
For fucks sake, I'm finally getting over the urge to reinvent the wheel all the time, but now all the libraries suck ass so I have to. Arrghh!17 -
!rant
Learning iOS/Swift Programmer here.
I feel like Apple’s Developer Documentation is extremely hard to parse.
For one problem, it feels like there are 50 similar ways to deal with it; but only one way will actually work.
There also aren’t enough examples in the docs for me either, they just seem to go: “Here’s some code, figure out what it’s purpose is.” for most things.
I also feel stupid, because I’m using the Hacking with Swift tutorials to learn iOS Development(Great Tutorials Though); and I don’t know how to just build an app from scratch. (i.e. creating swift files and assets and compiling from the terminal.)
And using StackOverflow feels like cheating.
Lastly, I feel awful inside when other people see my work and think I’m a genius, when really, I feel like I barely know anything at all.
I’m I alone in this observation?
Or just dumb?6 -
Incoming rant.
I have 4 years professional experience at a small shop working on a web application for property and liability insurance. The application is ASP.NET with C# as the code-behind. I have a BCS and will finish my MSIS fall 2017. I have no idea why I have the degrees. I know that when I enrolled, it seemed like they would be a nice addition to an otherwise empty resume. I was lucky enough to land my first and only development job during my sophomore year of my undergraduate program. Is this enough experience to land a new job?
I feel like I'm learning nothing at my current job. The specs that come in seem very vague to me. When asked for clarification, there is often push back, and I don't know whether that's because I don't have enough experience to parse what the client means in the two sentence spec I got or if it's because the client does not actually know what they want.
I hate my current job. My productivity is low because I spend more time trying to figure out what the client wants and analyzing an 8 year old system that has 0 documentation. I know some of you will just say, "Suck it up" at this point, but I really want another job. The only thing I like about this job is that it's 100% remote. It also pays $60k a year, so a replacement should be at least that salary.
Most postings I see require professional experience of 5 years or more, and knowledge of other frameworks. I can work on getting knowledge of the other frameworks, but will have no professional experience with them. I don't live in an area with a lot of software development jobs, and the ones I see are for non-IT organizations that want 1 person to run a distributed system from 10 or more locations. A hospital system out here wants to pay $30k a year for a guy to be both software developer for new tools as well as the helpdesk and IT support guy that's on-call for four locations in the county. I made more than that before I got into the development industry, for less work, and would rather leave than settle for something like that.
I've thought about moving to somewhere near San Francisco or San Jose, but I have my daughter to think about. I have joint custody of her, and would have to give that up in order to move out of the county.
I like programming and using it to solve problems. I like designing architectures and how all the components will interface. I like designing and normalizing databases. I like taking part in coding competitions for employers that are well-known (Amazon, Facebook, Uber, Twitch, etc.), even though I often just place middle of the pack. When that happens, I feel like I'm an imposter in this industry.
I think I have the most fun just working on small projects for personal use. My latest is an assistant calculator for the game Transport Fever to figure out cargo throughputs per annum based on the in-game timing information. Past projects have also been small. Ones I could use in a portfolio are a sudoku solver desktop application, PC/Web game in Unity that is a 3D FPS remake of Duck Hunt that allows open world exploration but locks the camera's viewpoint for shooting events, and a building assistant for Rome II: Total War that maps out all the bonuses/perks of user-specified building combinations in provinces so users can record their long term building plans without using all their turns to see the final results.
I seem to be an unproductive, average developer who dabbles in projects here and there.
This is what I want from other Ranters. Just say something. I don't care if it is, "Suck it up and get better." It could be your tips for finding and securing a new position. It could even be empathy, if such a thing exists on the Internet. Whatever you want, just say something that will help get me thinking of what the next steps in my career should be. -
Aka... How NOT to design a build system.
I must say that the winning award in that category goes without any question to SBT.
SBT is like trying to use a claymore mine to put some nails in a wall. It most likely will work somehow, but the collateral damage is extensive.
If you ask what build tool would possibly do this... It was probably SBT. Rant applies in general, but my arch nemesis is definitely SBT.
Let's start with the simplest thing: The data format you use to store.
Well. Data format. So use sth that can represent data or settings. Do *not* use a programming language, as this can neither be parsed / modified without an foreign interface or using the programming language itself...
Which is painful as fuck for automatisation, scripting and thus CI/CD.
Most important regarding the data format - keep it simple and stupid, yet precise and clean. Do not try to e.g. implement complex types - pain without gain. Plain old objects / structs, arrays, primitive types, simple as that.
No (severely) nested types, no lazy evaluation, just keep it as simple as possible. Build tools are complex enough, no need to feed the nightmare.
Data formats *must* have btw a proper encoding, looking at you Mr. XML. It should be standardized, so no crazy mfucking shit eating dev gets the idea to use whatever encoding they like.
Workflows. You know, things like
- update dependency
- compile stuff
- test run
- ...
Keep. Them. Simple.
Especially regarding settings and multiprojects.
http://lihaoyi.com/post/...
If you want to know how to absolutely never ever do it.
Again - keep. it. simple.
Make stuff configurable, allow the CLI tool used for building to pass this configuration in / allow setting of env variables. As simple as that.
Allow project settings - e.g. like repositories - to be set globally vs project wide.
Not simple are those tools who have...
- more knobs than documentation
- more layers than a wedding cake
- inheritance / merging of settings :(
- CLI and ENV have different names.
- CLI and ENV use different quoting
...
Which brings me to the CLI.
If your build tool has no CLI, it sucks. It just sucks. No discussion. It sucks, hmkay?
If your build tool has a CLI, but...
- it uses undocumented exit codes
- requires absurd or non-quoting (e.g. cannot parse quoted string)
- has unconfigurable logging
- output doesn't allow parsing
- CLI cannot be used for automatisation
It sucks, too... Again, no discussion.
Last point: Plugins and versioning.
I love plugins. And versioning.
Plugins can be a good choice to extend stuff, to scratch some specific itches.
Plugins are NOT an excuse to say: hey, we don't integrate any features or offer plugins by ourselves, go implement your own plugins for that.
That's just absurd.
(precondition: feature makes sense, like e.g. listing dependencies, checking for updates, etc - stuff that most likely anyone wants)
Versioning. Well. Here goes number one award to Node with it's broken concept of just installing multiple versions for the fuck of it.
Another award goes to tools without a locking file.
Another award goes to tools who do not support version ranges.
Yet another award goes to tools who do not support private repositories / mirrors via global configuration - makes fun bombing public mirrors to check for new versions available and getting rate limited to death.
In case someone has read so far and wonders why this rant came to be...
I've implemented a sort of on premise bot for updating dependencies for multiple build tools.
Won't be open sourced, as it is company property - but let me tell ya... Pain and pain are two different things. That was beyond pain.
That was getting your skin peeled off while being set on fire pain.
-.-5 -
I spent 2 hours fixing eclipse.
I spent another hour getting Java to parse my date and time input.
And I still have to get an SQL query running.
and I need to do 5 more problems like this for a team project.
I seriously detest being dead weight on my team, especially when it is a two person team.
This is friggin bullshit. I'm a 2nd year college CS student! I'd think I'd be a quicker programmer by know! I LEARNED TO PROGRAM IN JAVA FOR TORVALD'S SAKE!
Well. Back to work.2 -
Ok, I'm starting with C++, I want to do a couple of things without reinventing the wheel
I want to parse flags passed to my soft… — Use Boost
Ok, now I want to do some checks about filepa… — Use Boost
What about getting a file size without having to pull my hair out ? BOOST
Alright, Boost is actually the jQuery of C++, right ?6 -
Okay, yes, modsecurity WAF is amazing and all, but... When one tries to implement its rules atop an existing app that wasn't developed in accordance to the rules... That hurts.
How tf am I supposed to parse and present a 6.5GB / 22M line audit log to the client?! Just parsing that monstrosity once takes *minutes*, let alone doing any sort of sorting / analysis!
I feel sick. This is exactly why I am a sysadmin and not a programmer, I don't like writing analysis stuff, or programs more complex than a few hundred lines of bash... :|5 -
Alright, if you don't make apply a little feature, which you already use in your webpage, in your API, I'll have to fucking parse that shit.
Screw you, I'm sacrificing my free time... -
!Rant
After 6 weeks of VBA programming I was given a small side task (webcrawl, get data, parse into SMALL and I'm glad to say I have it finished with the day. This being my first ever python script I'm a little bit proud of myself. It's not clean, or nice, but it works as intended and can easily be reused.
😃😃😃 -
Every time I read "IDGAF", I can't help but parse it as a Doom cheat code, trying for a moment to recall what effect it had.
Boy I feel old1 -
So following my previous post, the issue happened again. And actually for background what I've been telling my boss, for years, we need ELK setup and integrated into all our APIs ASAP.
I think it's a punishable crime if any program is released into prod at a tech company with out real time logging/monitoring built in?
So issue still happening, user sent us the request details. So now need to find the actual now that handles the request and look into it's logs to see the details.
Now he's doing it the hard way.... Just finished took 1hr, and the best answer her can come up with is "I think .... Maybe ..."
And if course this is based on infinite data. He stopped after finding a "probably cause"
I have a script that is like promotion ELK, downloads all looks and parsed then so I can run queries to pinpoint the exact call and which log it's in. And can see what's happening around it.
We'll see what my way find but definitely does not take more than 1hr...
Loading data maybe but that's because it needs to download the logs and parse them all...
On a side note, guess I'm Beck on devrant as I have something to rant about. Though it's the same something that I was wanting about years ago... Monkeys...1 -
So I thought to myself.
Hey I'll go ahead and use python, it will make this easier than using c++.
So I start looking at python.
And I start looking at specific common functions that c/c++ and .net all offer.
Like writing a fucking png image.
And I start seeing 3rd party libs that are at version 0.2
And so I say, this is supposedly the language data people love. which would include searching gis data too right ?
Everybody touts this level for ai and machine learning and all this other bullshit but I can't even create a fucking image ? And every document points to this same lib where it comes to creating this image ? at version 0.2 ?? 20 years or more after PNG was created ?
So I look up geotiff, and see 0.4........ so..... what is this language good for again ? I can parse json in javascript and do the other things I want...
Oh scatterplot generation ? What is it being displayed in jpeg ? Maybe the jpeg implementation is good. because you know i just use scatterplots constantly. yup. most of the data I require to analyze uses scatterplots. not risk.
fun.
oh and look django.... who the fuck uses django ?
and omg it makes me format my text or the run bombs.....
jesus. rpg much ?
I'm just... I'm not seeing...
WHY ?????????
and then I have zimmermans voice buzzing in my head about just using goddamn .net24 -
The rear ducking continues. We've built a reliable translator in the dumbest fucking way possible, it's just lovely. I simply reused the structure for feeding data to the VM assembler, an array of arrays, where there's one array of (ins [args]) per node in the parse tree.
It's nice because nodes can be solved out of order without affecting the actual sequence in which the instructions are output. And if one statement (node) equals multiple instructions, you just push multiple entries to the corresponding array, or push nothing if you need to output nothing. Easy as goblin pie.
This is enough to convert an input language to the assembly-like intermediate representation we use for the virtual machine. So then there's doing it backwards: walk the same array of arrays, and map those virtual instructions to a physical architechture. I guess I could do the encoding to native binary myself, it'd certainly be interesting to try, but I'm burnt-out already so I'll just use fasm for now.
Initial test: wrote a test program in my own stupid language, ran the translator, dump output to file, assemble that with fasm, run with r2 -d.
Crashes? No.
Runs fine? Yes and no.
For fuck's sake, I don't have syscalls. Mainly because the VM doesn't have an operating system, lmao. I was testing virtual programs by just freezing state, terminating, then dumping the fucking registers and stack to the console, we have no I/O to speak of. Not even a real 'exit', VM handles that by reading a return value every step like a mentally damaged son of a bitch.
So anyway, I manually paste the linux mambo, you know:
mov rax,60
mov rdi,0
syscall
And NOW our program can end execution without crashing.
Okay then, so does the test code work correctly?
** DRUM ROLL **
Yes.
Ladies and gentlemen, mother fucking PESO is now a compiled language, and going forward I will be expectantly receiving your marriage proposals for reviewing. Oh, but not so fast, we still need a frontend...
Well, we'll handle that in the next few days. I'm just glad to be *nearly* finished with this fucking compiler, I want nothing to do with anything else ever, but we know that's not going to happen, so Lord please end my pain.
No sponsor as this rant has been paid for by tax evasion. -
So I had this JSON thingy, where I named the property containing a datetime string "timestamp".
For some reason, JS decided to convert that into a unix timestamp int on parse. Thx for nothing.6 -
Turns out Chrome really dislike to parse, save in indexedDB, query some things, and draw a graph of some JSON file.
Or, you know, maybe, an average response size of 5Mb is a bit too much.2 -
rust, where pressing autoformat won't format your code but will format your comments which are just there because you're trying to keep track of the data you're going to parse and now that shit is off the page motherfucker can you not4
-
Went on a Hackathon with two friends. They didn't do shit. This week, they told me that they only knew c#, so we should switch to that. (I use Linux so I shouldn't have accepted that) Just learned that they are going to a maths camp this week and the deadline is next Sunday. Dotnet core CANNOT PARSE FUCKING JSON. I'll rewrite it in node.js, and hope that I can type fast enough to finish in time. Fuck me, fuck my lazy friends and especially fuck Microsoft for saying that they support Linux while providing a dotnet for Linux published in 200-fucking-56
-
What are your plans for Christmas?!?!!??
I normally won't engage in societal tropes like pointless, generic, smalltalk or those questions people ask for lack of independent thought/societal trope-isms....
Here's my templated answer this year:
Background = ~2k$ in piles of tech... server upgrades components, apparently the only managed switch left in business/non-custom enterprise networking in the country/indexed for sale
(2k in what I would pay.... my tech sourcing is more base level and +4 years pro exp(yea... since age 8... really))
Foreground.... a shiny ✨️ new, wonderfully discounted for dumb reasons that i appreciate... 10Tb LFF HDD! 🥹🥲🤩
I really like raw data... enough raw data and proper context relevant high-level, custom, precise algorithms and i genuinely believe literally any questions or problems can be quantified and solved for
So... I just keep getting data, life, sourcing, stats on human behaviour... i factor everything
Yes i realise im very odd
//initial context plus curiousities
As parsed out to somewhat tangential commentary below... i cant keep making people go away for societally viewed polite engagement. Therefore, when asked again by factory sales rep who enjoys verbosity and apparent finds me extremely worth his intrigue/personal time
// additional context (and my attempt to be more parse and comment conscious)
With a bunch of initial reveals and launches startjng in a week and technically being the "owner/boss"(cringy to me so Ive officially made my title (anywhere with custom input fields) DragonOverlord...dragons being a tied in theme to all sects and no one can say DragonOverlord isn't a position... as it's clearly a class... unless you find a human more style code ignorant, comment inept, and in need of a very multilingual scribe to create a lexicon 2 steps before my code would be even follow-able without a likely, bad, headache and davinci code like adventure including the improbably well placed wise scholars that just happen to have significant unique and vital information they are willing to freely share with strangers. 49
49 -
Other build tools:
Here is a plugin, use it . Be done.
Scala Build Tool aka SBT:
Build your own plugin.
Everything is scala...
You can create by the way funny endless loops when using the wrong syntax - yet it might compile successfully. And then when you load the plugin, it works. Till it is evaluated - lazy evaluation for the fun.
Error messages are at best cryptic.
*If* you manage to get a working plugin and *if* it runs...
Surprise. Surprise.
You might need to parse the log output of SBT.
Another funny surprise: Log output isn't configurable. You can configure the log level. That's it.
So after a lot of pain stakingly putting together a fucking shitty plugin, you can now grind the rest of your brain with ...
sed.
Cause yeah. You can now use regex to parse an sbt build log and extract the necessary information.
:)
...
So....
Are we there?
Mwahahahhaa.
Only if you haven't forgotten to either disable colored output for SBT... Or take an extra mile with e.g. less -R.
Otherwise you have ASCII control characters in your file. :-)
After getting that shit to work, you now have finally a parseable build log.
Just took days instead of hours.
But that's SBT. :-)6 -
I fucking hate the person that created the ionic timepicker its such a fucking mess if you want to do anything advanced and it's so poorly documented that most of the time you just have to guess what you should do. Best part: this fucking component doesn't even use a Date Object it uses A FUCKING STRING that it parses, so I have to parse, unparse, parse, unparse. Who in their right mind thought this would be a good idea?!
What frustrated me the most was when I tried to use their min, max functionality. I used the component as a timepicker, so I ignored most of the Date Object and just initliazed them at 0. Afterwards set the hr, min, sec and did the same for the max value. Doesn't work... It just bugs out and I can only pick midnight of that day... Okay. I kid you not: tried for two hours to fix this shit. Console logged the crap out of that thing. Everything seemed right. Out of frustration I then just initlialized the max value like normal, so the date is the current date. AND SUDDENLY IT FUCKING WORKED. WHY?! FUCKING NOBODY KNOWS. WHO, WHY, WHAT?! -
I use the ICU format often for translation because it's simple enough and supported on many platforms. It's something of a standard so I can use the same translation string format and similar library functions everywhere.
ICU is like a really simple templating language, somewhere between printf and something like smarty or twig simplified and specifically intended for internationalisation.
I updated a library providing ICU compatible parsing and formatting for one of the platforms I'm using and find tests break. I assume that only thing to change is the API. ICU very rarely changes and if it did it would be unexpected for it to break the syntax in a major way without big news of a new syntax.
The main contributor of the library has changed since some time last year. Someone else picked up the project from previous contributors.
Though the library is heavily advertised as using ICU it has now switched to using a custom extended format that's not fully compatible and that is being driven by use case demand rather than standardisation.
Seems like a nice chap but has also decided for a major paradigm shift for the library.
The ICU format only parses ICU templates for string substitution and formatting. The new format tries to parse anything that looks XML like as well but with much more strict rules only supporting a tiny subset of XML and failing to preserve what would otherwise be string literals.
Has anyone else seen this happen after the handover of an opensource library where the paradigm shifts?3 -
We had almost finished integration of debit card depositing for our application.
Yesterday, the clients told us they signed a contract with a new provider.
This is after telling us they'd signed the contract with the previous provider, but as it turns out, that's a lie.
So we have to scrap the entirety of the last 8 days work because the new provider is a shareholder in the client's company now.
The new provider doesn't have an SDK for our language, and what they do have is XML.
It's time to parse, I guess. -
So I'm working on a snippet of JS to generate widgets for a custom data dashboard at the moment, in a project where I've been paired with a junior "developer" (he's more of a junior script monkey though), which is just plain painful...
Recently he wrote up a long message bitching about how my library API keeps changing, making it impossible for him to get any of his work done.. This particular message even made references to "writing his own widget library" and "stabbing me in the eye".
It's currently at version 0.1.0-ALPHA, just by the way. Major version 0 mother fucker.
Anyways, one of my colleagues stepped in the other day to try help him with the front-end stuff, which finally helped me get the feedback I was asking for. At which point we found out he's still currently working off a build I gave him 4 fucking weeks back.
Honestly though, I'd both love and hate to see him try make a library to do this: pull data from a non-standards company data API, parse said data from unnamed number arrays nested up to 4 levels deep, then morph that data into one of four different charts or one of five made up of custom markup.
All he has to do is create a UI to configure and present my widgets, but he can't even figure out how to integrate dependency management into his front-end project.
O.o
OMG. Can I stab him?? Pretty please?1 -
When the backend service you use religiously decides its going to shut down, and the only other real alternative for you is Firebase... But doesn't have a Xamarin/C# API... fml...3
-
Recently we got a new project assigned and as always you are hyped, really really hyped...........
We were supposed to find all kind of driver updates (especially bios ones) for all devices the company owns. So first of all we thought:
EAAAASY! A little bit of web crawling, regex, etc.
.
.
.
.
B
U
U
U
U
T
!
We were sooooo soooo wrong these fucking manufacturer websites are absolutely awful to crawl or parse and nowadays there are no proper FTP Servers or something else anymore you could use to get the information. Every subsite is little bit different...
While coding and literally brute forcing possible urls (there was some kind of vague pattern) we learned AGAIN to appreciate proper developed and designed websites. Especially by devs who may have some more usage scenarios in mind for their site than simple human clients.
So thank you to all of you awesome web developers who design proper websites and web tools!
All in all it took us 2 weeks to come up with a proper solution (by the way we are a smal team of 3 devs) which somewhat works reliable and can deal with site changes etc. -
Built the most generic file importer.
So a customer had his SAP system giving us some 5 million barcodes in a csv which we needed to parse. But as there could be different file types and I thought the handling would always include the same steps I made them configurable through function pointers. - Did not want to make it as spooky as the rest of the code base where the function pointers were buried deep in some shared memory configs, which might even change at run time, but rather I statically used the member functions of my class. Just to poke fun on the ugly C++ syntax of member function pointers. I still shudder at the thought some poor soul now has to maintain that code.
(For the actual parsing I actually used a one liner in awk which was churning through the records in one minute which was faster than the SAP guys seemed to be accustomed to.) -
Amazon is screwing with me.... So I was writing that Prime Recently Added Videos scraper but it's turning out that the Search results pages' layout changes each time. Like they're running multiple versions of the search engine that return the page in different layouts...
So after figuring out one of them... The whole thing breaks since I need to parse a different html layout...2 -
Just came across this on a forum while researching something:
"
Hello, sorry that I didn't check the TOS myself. I just had this thought and figured it'd be easier to parse for someone with the mental model already stored. I'm sorry if this is lazy, but promise I'll pay it forward.
"
As a dev, who frequently has to build FAQ's, Support forums, make sure T&C's get displayed again when changed etc etc. The above offends me to my very core.
So much so, I have been unable to continue researching, and now fixated on finding some way to make him regret his actions. -
Give me a single reason, why someone will use XML over JSON. I am trying to parse a XML file in Java and it builds a null document everytime. HELP!!5
-
Joined a hackathon for an app which requires a server to help parse a few things and send push notifications. Looked up Google push notifications and it seemed decent so I just bookmarked it and left it there for reference during the hackathon. Biiigggg mistake. No idea how to implement the server, couldn't find a tutorial that explains enough for a newbie like me and the Google site didn't help much either. Welp. Google cloud messaging. Never gonna like those words ever.1
-
At work we use a custom python library to parse XML responses from an internal API to objects. I literally spent half an hour pondering why an if statement was misbehaving. Turns out it parsed <tag>false<\tag> as obj.tag = 'false' instead of the boolean False which obviously made "if obj.tag:" misbehave 😒
-
Whyyy has to be the price in xml import in format impossible to parse. Please use a fucking dot next time, thanks!8
-
Just started doing my project for Java Class, a Polynomial Calculator App.
Get it done, get a dozen errors. Fix every bug. Find other bugs when inputting.
Brainstorm 5 minutes and realize I could change the way I write the polynomial at input.
Change 20 lines of code that do String, Split, Run through the split and check for coefficient and power, parse them to float in an array to specific positiona - to 5 simple lines.
Program works fine. No more previous errors.
Have the great idea to add the following:
-If you divide the Polynomial by 0 output "Are you retarded?"
P.s. I'm happy about my first project even if I hate Java.4 -
When the library you're using doesn't follow semver and introduces breaking changes with a path version... (I'm looking at you, ParseServer!)1
-
Today I learned how to read extract and parse a multi lvl XML file in Perl, only took 4 hours to make the script from 0 knowledge of Perl.
-
!rant
Who else uses Excel to analyze and make charts using normalized log data? (writes apps to parse and normalize them)
Or is there a better way to inspect server logs?6 -
I was tasked to parse some complex output oft another application so that it can be displayed nicely in our Frontend. The output had lots of inconsistencies and exceptions - I spent the entire fucking day to wrote the craziest regex I have ever written in my entire life. With a few minor issues it worked pretty well. I was happy... Then a colleague came into my room, peeked into my screen..
Him: "You are aware you can just specify a --json flag to get json output?"
Me: "..."
*long silence*
Me: 😵🔨
Please end my life. -
I had this teacher who was teaching us how to use java and .NET to parse XML data to an excel sheet. Let's say every week i was spending at least 2 hours finding bugs in the excel formatting and telling it to the teacher.
This happened for few weeks and when the project ended I could see how tired of he was.
To this day me and my colleague still rant about that -
So, I started fiddling around APIs which returned data in JSON and parse that data in PHP and it feels so good.... Past 3 days I've been in deep learning PHP and practically $this is the best thing....
I need recommendations for such APIs, so far I've used
1. Chuck Norris Jokes (http://api.icndb.com/jokes/random/)
2. User's IP Address and details (http://ip-api.com/php/)
What would you recommend, let me know..1 -
Probably my least favourite thing about Microsoft's pretend Git suppoort is how Visual Studio doesn't show reasonable merges for csproj files when Git's own annotations in those files are almost always optimal, and they could literally just parse out those diff markers.
Instead they have a custom dummy diff engine that marks the entire contents of both files as conflicting.
Or they could do the sensible, ideal thing and diff the XML DOM, but that may set the bar too high.3 -
The bug: Some string values for an identifier property in the data objects are being sent from our frontend prefixed with a '0'. Sometimes. When it happens, it usually gets stripped away again by the time it's passed to our backend. But not always.
This 0 is never explicitly set anywhere. I even searched for a few variants of " = 0" in both the frontend and backend projects without receiving any results. You might already be suspecting where this is going.
So it turns out.
The data object which holds this value is being initialized in the aspnet (don't ask) backend and passed to the frontend, which then hydrates it. This value is always an integer number, albeit incidentally so which is why string is used as the actual type. When this object is initialized, it's hardcoded with an anonymous type where this property is set as int because I guess someone figured "it's always an int though". Being a typed language, primitive scalars can't be null objects which means the property's value becomes the concrete int 0.
Okay weird. I can think of better ways of doing this but let's just set it to string as I can't start overhauling things right now. Let's just go find where this value is somehow concatenated into the incoming parameter.
You see, this happens because at the point where the frontend sets this value, it may be an int or string depending on where it came from, and I guess someone figured that in order to cast it to string you just go prop += arg seeing as the prop is empty string and all. Because explicitly casting it or - as much as I get a rash whenever I see it - going prop = "" + arg would be too verbose and unoriginal.
Bonus round: How come the 0 only sometimes made it all the way to our backend? The thing is that this bug has been fixed before. The fix is that because this string is "always" an int, you can parse it to int before passing it to the backend in case it has leading zeroes. This path is only taken in certain views because someone forgot to copypaste their fix into all the places this is repeated.
Sometimes you find a bug and you are just somehow more grumpy after fixing it.1 -
Today I started a project in which I must parse and extract some features from orders. Features can be product names, options, custom data and more and then do some validations/processing.
The (main) problem ? All I have is a String per order and of course most of the product/options have either change or been deleted.
I want to sudo rm -rf myself 😞 -
I had to do a modular deduplication project that could read, parse and clean up the data.
The data? Personal information: Name, Surname, phone, address and more.
Imagine the zip code in any of the following formats: ####AA, #### AA. Names with and without dashes. Address with(out) spaces, dashes, underscores etc. as well as typos! Now clean it up, and dedup.
But what files have priority over another? What data is newer? How to process address changes?
Deadline: 2 moths, impossible deadline for a (at the time - 4 years ago - rookie developer)
Anyway, night before the deadline, code was running somewhat (Java) and was able to get a Regexed address cleanup of about 70 - 80%.
My boss comes in to check the progress, sits me down next to him and says: Not good enough, let's do it together tonight, it was 4pm, day normally ends at 5pm.
No thank you, I can't do that. if you don't want this code, then I can't meet your deadline.
bye -
!rant
Just did some really satisfying refactoring. Much happier with my work now. Its a little cli app to poll M-bus devices and write the data to file if the user wants. Can scan the whole range, search for specific devices and VIFE codes, parse an input file for lots of the previous data and one or two other things.
How's everyone's else's weekend? -
So in regards to my last post, built up the app some more all tested, working locally. Pushed to heroku, envs set, add-ons added only MongoLab and sendgrid. Go to test, 422 errors on POST requests and JSON parse errors.
Why? How? What? 😂4 -
Gson is an excellent library every Java/Android developer should know. You can easily parse a Json or XML network response into a POJO class and get ready to go. But the guys who started the project I currently support found a better, smarter, slicker way to parse network responses into memory:
ArrayList<ArrayList<HashMap<String, String>>>
I would love to meet the genius who came up with this idea. I mean, you can parse absolutely any API response without even having to define stupid Java classes or importing libraries! And also you can reutilize the same scheme for literally all Java projects that handle API responses! Wonderful -
For a little background on the sort of stuff I'm dealing with, check out my last rant.
Anyways, I'm testing this pipeline at work and was just reminded of the fucktarded way a "software engineer", who had a bachelor's biology degree, decided to handle a json file.
The script is question is loading a json file containing an array of objects. The script is written in perl. There's a JSON module. Use that? Fuck no! Let's rather perform an in-place sed command on the file substituting the commas separating objects in the array with newlines, then proceed to read the file line-by-line and parse out the tokens manually. Mind you, in the process of adding the newlines he didn't keep the commas, so now all of these json files his bullshit handled are invalid json that cannot be parsed.
The dumb ass was lucky the data in the file is always output upstream as a single line and the tokens for each object are always in the same order, so that never led to problems. But now, months later after I fixed his stupidity I am being reminded of it again as I'm testing and debugging some old projects as part of regression testing new changes I'm making.
TL;DR Fuck dumbwit motherfuckers who can't even google search "parsing a json file" and doing literally anything that is less fucktarded than manually parsing a json file2 -
I'm currently working on a project that scrapes the SEC's EDGAR website for type 4 filings.
I currently have the required data in raw text format that somehow looks like xml, i really can't tell what it is but i'm trying to parse this data into json.
I've not parsed something as complex as this before and will appreciate any form of pointers as to how to go about this.
i have attached a screenshot of one sample.
this link fetches the data of a single filing in text format.
https://sec.gov/Archives/edgar/... 5
5 -
Part 3
https://devrant.com/rants/9881158/...
I dropped subtitles and started extracting audio from movie, after that I use whisper to convert speech to text.
I parse srt from whisper, adjust timestamps to get >= arbitrary amount of voice seconds. I put text to vector database with timestamps and movie file name.
I query database by ex. “I don’t know” and extract first n results, after that I walk trough movies and extract parts with found text.
I normalize and merge parts into one movie.
Results are satisfying so now I decided to try to find a common dialogue that I can watch by combining multiple persons speaking from multiple movies.
Might also try to extract person from one movie and put it to other movie.2 -
In regards to my last string of posts regarding react and Auth, I got it working the bearer token is being passed but now just getting XML errors every time I submit a form. All the data being passed is JSON. I've created a stackoverflow question https://stackoverflow.com/questions... as I'm getting nowhere and SO really isn't helping either. So if anyone wants to take a stab, go for it.11
-
I completely *detest* that the MongoDB *shell* is just a fucking jS interpreter with extra API calls sprinkled on top and whoever came up with that idea should have all their commits reverted immediately, working with that thing is a punishment!
I don't even know a way to parse and chew through the json it spits out in my own json viewers, as it's "Extended", and none of my editors understand that!
Ugh, haven't been this frustrated with a tool for a while...5 -
I had a pretty good day.
I had my first pay raise as a dev;) not huge but i wasnt expecting one for another 4months ;)
And i was working on a security scrip for after effect plugins. The thing is called Extendscript and is built on top of ecma3. Yeah javascript version from 1999. Hashing stuff gave me different results. Took me about a week to realise that the string buffer were different and i had to parse in latin something to have the same matching buffers. What a hassle man. Let alone trying to make it work with Windows terminal which after starting with Linux then mac, windows seems sooo sucky.
But yeah its my first security scripts so 2 main achievements for me today! Ive waited 4 years to reach a level where i now feel like a real professional dev. ;) sry not a rant ;) -
Why tf are you telling me that I get to choose the format of the text that I'll need to parse later if you keep using any other freakin possible format on earth except for the one I chose 😠
-
I'm building a script parser to make mods for a game I like. The first step is to write an importer.
The documentation is nonexistent and I'm delving into byte manipulation, which I'm not familiar with - at all. I'm porting existing code from Java to C#, and everything is similar but different enough that I can't always just to a 1:1 transfer.
I get everything working, cleaned up and split into classes so I can write the exporter.
I do an import and the file won't parse. I try all previously know working files and still no good. I clean, rebuild, clean rebuild, run, debug, restart my computer, clear my cache, clean, rebuild. No good.
IT WAS WORKING 5 MINUTES AGO
Proceed to revert to every version from the last hour. No dice.
I was in the wrong folder the whole time.
Navigate to the proper folder, open the filename I know to be good and bingo, works like a charm.
The same project caused me headaches because I had a "== -1", when it should have been "== 1". Between my inexperience with byte manipulation and my untreated astigmatism, I was nearly sent to the shadow realm fixing that.3 -
!rant
Im fckin in love with parse-server!!!
How easily she configured and run smoothly behind my backend makes me want to marry her.
And I'm amazed with the fact she's not popular -
Changed the nodejs template engine because i though its unable to parse nested object. After the second engine had the same error i checked the properties of the mongoose "populated" object and its mongooses fault.. wasted 4-5 hours of debugging just because of a missleading console.log ... FUCK!1
-
Friend and me from the university need to write a program to parse Value-Change-Dumps from different files, and merge them together in a new file to easily compare them. This project last for the whole semester. The program was for one of the professors and we need to meet with him and give him an introduction how to use the program (was cli & gui based)
Long story short: enter office, give him the link to git repo. He clones it. Clicks on it and boom. Python error. Some Tkinter Error. OK ok after a few minutes we solved the issue by installing some additional packages and our program starts. But it doesn't work. About 80% of the buttons did nothing. WTF!??
Oh. We used git flow for fun and haven't moved the development branch to master and he cloned outdated code. We need nearly 30 minutes to solve this. 🤔And I'm just happy that this professor was just a calm guy . He was also happy because now he does not need to run multiple instances of GtkWave to compare his simulation results. -
Terraform + helm-chart ... I really ned a break. Who the fuck invented this shit.
The HCL format sucks
The documentation sucks
The dev tools suck
The debug output sucks
But I'm ok with that, I can manage.
But today really it shot the bird ... I can't have a fucking comma in a string? Because idk why the fuck helm-release tries to parse that fucking string and wants to make an array or whatever out of it? Why, you fucking abomination?
Something in the docs? Nah, who reads them anyway.
Because you know it's totally not strange that a string is analyse and oh wait there's a comma in it, the dev surely wants me to make an array out of it, because you know ...
So now I have to escape my fucking comma to prevent it to parse my fucking string. I just want to have a fucking string you hideous monstrosity ....1 -
A young new dev was working on his first ticket, about a bug during parsing of an uploaded excel file. Our issue was that if the file contained an empty line, all remaining rows were ignored. So the task included extending our tests to cover this case. After 2 weeks (!), his merge request comes in. His idea (without ever asking for help) was to parse the whole file (in some cases huge) in the production code a second time, just to count the rows (!!) and save the count in a public static int field, which was verified in his new test.2
-
So for wrok i need a js lib that can parse and extract elements from a HTML response.
Been thinking about it in the back of my mind for a few days now and just realized the answer has been in front of me all along...
This is an app wrote for myself a few months ago that checks a site for updates... its built with React Native... 2
2 -
Hello, anybody knows about any api that can parse delivery parcel tracking code and detect wich transporter it is and get the tracking infos ?2
-
Okay, I hope a few people can help me with this; what are the benefits/reasons to use MS technologies? I'm talking about .NET, ASP, Windows Server, Powershell...
I've never understood it. I love Nodejs because you don't have any packages unless you ask for them. Alpine Linux is amazing! It runs on 8MB of RAM from fresh and doesn't need much more space to install.
You want .NET core? 140MB download. You're configuring database connection strings? Feel free to type in whatever you like, it'll parse and replace with some magic variables that have come from some other random file.
I was using Powershell recently, needed to set an env variable. Bash is happy with "export name=value". You want to do that in Powershell? I just googled it and found an entire 40-minute read discussing how to set env vars. Why?! It should be one command, and I don't know who thought that "Get-ChildItem" was _obviously_ referring to env variables.
It seems to me that everywhere MS has got their hands on development-wise, it inherits the typical sales bullshit. No no, you can't call them "websockets", they have to be branded "SignalR" and add tons of overhead. You can't say "disable notifications" it has to be "focus assist". I'm really surprised something as simple as a keyboard hasn't become a "varied user input device" or something of the like.
Am I alone in thinking this?4 -
So I’ve been recording the same project into dr who bullshit meets the invasion of the body snatchers
If I were sleeping and motivated to finish something some bastardized people would steal it would be so simple to keep progressing through it and it would be contributed allowing people to write their implementations to parse and index Gis formats and integrate a lot of valuable data regarding travel and survivable conditions
Except for all the above mentioned bs which cuts my goddamn motivation down to next to nothing
And no one else seems to see a problem with this across the goddamn board because the pods already sucker their innards out13 -
I swear to god, getting Chumsky to do my bidding has almost taken longer than writing a parser by hand. I'm not looking for operator precedence, I'm not looking for complicated rules or anything, the main part of my language is literally just S-expressions, with some top level bells and whistles.
I don't even have a working lexer yet because I wanted to use this piece of shit library which usually matches the fewest possible characters to parse significant newlines but the Padded combinator takes as much whitespace at the end as it can find, and a host of other atomics don't actually adhere to the library's lazy principle in their procedural implementation. I've had enough. I'm going to bed, and tomorrow I'm writing tickets.
Actually, I'll probably also write PRs because I actually want the fixes to exist and not just complain about the problems, but I also really want to complain before I get started on that because I spent about two weeks just on this bullshit.3 -
Not really most painful, but definitely most painful of the recent bunch..
// yup, a bunch.. I've managed to fuck up a little on every thing I did that day :/ little friday the 13th for me, especially as I went on sick leave the next day and had to fixup my fuckups with a friggin migrane..
Anyways, I was fixing fallback to some default value in plsql.. before it didn't check what the input format was and simply relied on certain format, parsed that and converted to number..threw an error, duh!
I fixed it somehow elegantly to check with regex if the format is as expected and if not default to xy value..and if format is as expected to parse out the number..except that when I copied (or typed?! for the sake of me, I cannot recall how the fuck I managed to fuck this up) over the code to the package I didn't see additional [ at the begining, so everything went to the default.. Most embarrassing part is I commented everything, how it should work, use cases, what the input was and what was expected output..and failed to see the friggin extra [..
It was fixed easily, the extra [ stood out later when I saw the code, but it bothers me how I managed to overlook that in the first place. I think I need a vacation.. but have to fix other fuckups first.. :/ -
So how does an experienced programmer break his own code in a such a terrible manner.
And why would someone try to make me embrace a bogus thing I KNOW doesn't work to make sure its broken ?
See this is what I hate about this shit.
No programmer would make the mistake that was made. They converted all their classes that interpret STRING VALUES using a parse to BitConverter.
(The input is a byte array) for like, ALL THEIR CLASSES.
Again this seems fucking intentional.
Instead of letting it remain a goddamn class that handed around an open file stream with a binaryreader around it which was simple, they tried some fucking fancy shit and throw readonlyspan<byte> at a read method which is where the code WILL fuck up ! wtf is wrong with you fucking dumb bastards ? IF YOU DONT WANT THE CHOMS GETTING AHEAD SHOOT THEM JESUS CHRIST !
Maybe this is some special interests shit to make sure ArcGis remains the dominant gis package and no ordinary lowly programmer can have a reader to get started with their own manipulations.
YOu fucking bastards screwed up the world and i want to eat your fucking hearts from your chests and wear your fucking scalps and ears on a fucking necklace while burning down your fucking houses !
AND FIX THAT GODDAMN STEAM RELEASE VALVE !!!1 -
Vue <router-link> cant parse props data when parsed using path="" rather than name=""
WHAAAAAAAATTTT??????2 -
I'm trying to create log files with the PID or some JVM arg like app name but File appender doesn't parse ${myVar} in the config.
Issue is we have multiple instances of an app running but they can't be all writing to the same file.
I tried creating a custom Appender by pretty much copying the source code of FileAppender and then adding a function to add PID to the filename.
But when I use it, get some error saying "name, and fileName" are invalid parameters.
So wondering if anyone has experience building one that works out maybe there an existing code for such an appender?12 -
Once upon a time I was working with an engineer who loved sed and awk a bit too much. We had data stored in SharePoint that was retrievable via an RSS feed. Said engineer insisted on using curl to grab the feed and sed/awk to parse the HTML ...
I on the other hand suggested using libcurl (primarily for NTLM auth support) and parsing the RSS feed using libxml.
Which engineer do you think management decided supporting?
Hint: Reusability and maintainability were big requirements in this project.1 -
How do they parse and arrange the input and then generate the output with neural nets for talking bots?7
-
The coolest thing i wrote solo is a web app that parse my whatsapp text export files and show messages in bblocks with space between blocks proprotional to the delay between messages. I did this after a breakeup with my ex and i wanted to read all message history.
And yes, i had some stats features also. -
I used parse-server and services back when it was a web service at an internship, just loved the way it did things it did. Backend as a service was new to me as a mobile application developer. 5 years down the lane. My first go-to backend is Parse. I know firebase does XYZ things better. But I love the simplicity and openness of parse.
Community picked up parse as a self hosted open source service and its still going strong.
Just love the possibility of starting a mobile project and not having to worry about setting up a whole web service to cater to it. -
My CS (theoretical foundations of computer science, specifically) professor is currently teaching regular expressions... Has been for three weeks. Same thing over and over. All of his examples involve using regular expressions to parse HTML. He just told us to write a script (using Perl-style regex) that would recursively find and follow link tags in various websites. Just... no...1
-
Hey does anyone know of a Firebase alternative for user authentication? I used parse back when it was around but idk of any others
-
@grokii write a me a program that uses libpostal to parse one line addresses from any country and populates a record which contains all the fields that it uses in python21
-
Mother of rants ...
The AWS and MongoDB Infrastructure of Parse: Lessons Learned -
https://medium.com/baqend-blog/... -
Does anybody know of a Java library that you can use to parse cron expressions? I mainly want to give it a cron expressions and have it calculate its next execution time.6
-
Maybe I am picky, but:
Some people made a "FileStorage" API where in the open method you have flags like READ, WRITE, APPEND... And they made it like when you check WRITE the API opens/overwites to an empty file.
And when someon made a github Issue about this behaviour, they flagged it as a feature request. I'm so anoyed by not being able to overwite my data, thats just rude. Like should I use an file storage API to overwrite data like this:
0- Save file inner structure (you can't extract it from the API)
1- Open the file, parse the structure
2- Find file to overwrite
3- Save all the mess again
4- write your own API
5- sigh4 -
Excuse my question I might be the one to blame, but on Typescript 3.7 JSON.stringify parses numbers as strings, while on 3.4 it was working without issues.
I'm no pro in web dev but I did use JSON.stringify lots of times and that's something strange here, not sure what the cause is, but when I parse number props again using parseInt(value.toString()) it works .-.2 -
What kind of database do apps like Snapchat, Instagram, etc. use to store pictures and info. I'm guessing it is not MySQL, or Firebase, or Parse, so then what is it.7
-
!rant but want to know this
how does facebook parse the json like
for(;;);{"key":"value"}
that for loop prevents anyone to read json but how does facebook get away with it?












































































































































































































Top Tags
Weekly Rant
View