
Join devRant
Do all the things like
++ or -- rants, post your own rants, comment on others' rants and build your customized dev avatar
Sign Up
Pipeless API

From the creators of devRant, Pipeless lets you power real-time personalized recommendations and activity feeds using a simple API
Learn More
-
I worked with a good dev at one of my previous jobs, but one of his faults was that he was a bit scattered and would sometimes forget things.
The story goes that one day we had this massive bug on our web app and we had a large portion of our dev team trying to figure it out. We thought we narrowed down the issue to a very specific part of the code, but something weird happened. No matter how often we looked at the piece of code where we all knew the problem had to be, no one could see any problem with it. And there want anything close to explaining how we could be seeing the issue we were in production.
We spent hours going through this. It was driving everyone crazy. All of a sudden, my co-worker (one referenced above) gasps “oh shit.” And we’re all like, what’s up? He proceeds to tell us that he thinks he might have been testing a line of code on one of our prod servers and left it in there by accident and never committed it into the actual codebase. Just to explain this - we had a great deploy process at this company but every so often a dev would need to test something quickly on a prod machine so we’d allow it as long as they did it and removed it quickly. It was meant for being for a select few tasks that required a prod server and was just going to be a single line to test something. Bad practice, but was fine because everyone had been extremely careful with it.
Until this guy came along. After he said he thought he might have left a line change in the code on a prod server, we had to manually go in to 12 web servers and check. Eventually, we found the one that had the change and finally, the issue at hand made sense. We never thought for a second that the committed code in the git repo that we were looking at would be inaccurate.
Needless to say, he was never allowed to touch code on a prod server ever again.8 -
Dear DEVS,
chmod -R 777 /
is not the right way to fix your application permissions issues!!!!!!
Yours truly,
sys ad who is not fixing your production server.23 -
So they were having trouble with the server always being slow and maxed to 100%, so the boss told me when wait times were hitting 5+mins due to server trying to catch up, he complained at me, said if I could get the wait time to 30sec to instant he would raise my pay to 90k a year, then walked away after I agreed, I was quite serious but I don't think he thought I was, so I decided to look over the system, IDK who but they put all the calculations and processing server-side for the CA's on floor then sent the completed view to the CA, so I spent months recreating the entire system except the server only pulled the data needed then the new client would do all the processing on their computer since they weren't doing anything anyways, I did a practice run today as its one of our peak days, wait times went to barely 5secs or "instant" according to CA's, I walked into the office, slapped that hourly report down after just two hours and showed the massive increase in employees production times.
That look on his face...
That look on my face...
That look on my next check...
Bliss10 -
Production is down, a coworker got himself locked in his own apartment so he can’t leave and another is late, the phone won’t stop ringing
And I don’t have the credentials to access the production server
Just a monday morning, everything’s fine 🔥😊🔥7 -
The project where I realized I wanted to go from chemist to pro dev.
I built a flow-chemistry spectrometer with monitoring backend in Haskell.
Spectroscopy is where you add a reagent to a glass tube, it changes color, and by measuring the exact color it tells you how much of something (for example, a toxin) is present in the sample.
I had to do that a lot on factory samples, writing down measurements using pen & paper.
I'm lazy so I decided to do the logical thing: Automate it. I bought a second hand spectrometer, stripped the casing, did a shitload of glassblowing and hooked up tubes to the production pipelines, so I could get samples, mixing them in the correct ratio with reagents in continuous flows using valves.
I ended up using 2 home-crafted arduino-like boards (etching PCBs is fun!).
One to calibrate the mixture against known samples and control solenoid valves to continuously cycle through various reagents and deionized flushing water, the other to record the measurements and send them to a server running a Haskell/Yesod API.
The server collected the information into InfluxDB (A time series database), displaying all data on a graphite dashboard.
Eventually I wrote Haskell plugins for most of the chemistry processes, from pH & temperature measurements to polymer property and pigment tests (they made a lot of printer ink).
Then I was fired because they didn't need chemists anymore, and the code "could be maintained by the intern" (poor guy)...
But I did find out that I loved functional programming, chemistry automation projects, and crafting my own electronics during that time.16 -
I worked on a greenfield project a couple of years ago. The company had an old solution written in Omnis (heard of it? Yeah, me neither) with an SQL database. My team was to create a completely new web based system... on top of the old database, so the customers could keep their existing stuff.
The dba was an intelligent man, one of the nicest people I've met, and over the course of fifteen years he had made a remarkably terrifying monstrosity of a database. Some years before me they wanted to "future proof" the system and make it "easier to switch to new technologies". So they moved the entire business logic into the database...
I used a tool to create a visualization of said database when we started. It had no views, only tables and sprocs. Look at it! Tables and sprocs are rectangles (well, dots) and any connections are drawn in grey lines. There were no foreign keys, so a tables only visualization only yielded a collection of independent rectangles without a single line.
Now, the stored procedures were bloody MASSIVE. A single procedure that only registered a new interested party and attached them to a property had 2500+ lines and over 150 parameters.
Also, this dba added features and fixed bugs by logging into the respective customers production server and writing SQL.
That database is the stupidest thing I've ever seen a developer do. 34
34 -
I think I've shown in my past rants and comments that I'm pretty experienced. Looking back though, I was really fucking stupid. Since I haven't posted a rant yet on the weekly topics, I figure I would share this humbling little gem.
Way back in the ancient era known as 2009, I was working my first desk job as a "web designer". Apparently the owner of this company didn't know the difference between "designer", which I'm not, and "developer", which I am, nor the responsibilities of each role.
It was a shitty job paying $12/hour. It was such a nightmare to work at. I guess the silver lining is that this company now no longer exists as it was because of my mistake, but it was definitely a learning experience I hold in high regard even today. Okay, enough filler...
I was told to wipe the Dev server in order to start fresh and set up an entirely new distro of Linux. I was to swap out the drives with whatever was available from the non-production machines, set up the RAID 5 array and route it through the router and firewall, as we needed to bring this Dev server online to allow clients to monitor the work. I had no idea what any of this meant, but I was expected to learn it that day because the next day I would be commencing with the task.
Astonishingly, I managed to set up the server and everything worked great! I got a pat on the back and the boss offered me a 4 day weekend with pay to get some R&R. I decided to take the time to go camping. I let him know I would be out of town and possibly unreachable because of cell service, to which he said no problem.
Tuesday afternoon I walked into work and noticed two of the field techs messing with the Dev server I built. One was holding a drive while the other was holding a clipboard. I was immediately called into the boss's office.
He told me the drives on the production server failed during the weekend, resulting in the loss of the data. He then asked me where I got the drives from for the Dev server upgrade. I told him that they came from one of the inactive systems on the shelf. What he told me next through the deafening screams rendered me speechless.
I had gutted the drives from our backup server that was just set up the week prior. Every Friday at midnight, it would turn on through a remote power switch on a schedule, then the system would boot and proceed to copy over the production server's files into an archive for that night and shutdown when it completed. Well, that last Friday night/Saturday morning, the machine kicked on, but guess what didn't happen? The files weren't copied. Not only were they not copied, but the existing files that got backed up previously we're gone. Why? Because I wiped those drives when I put them into the Dev server.
I would up quitting because the conversation was very hostile and I couldn't deal with it. The next week, I was served with a suit for damages to this company. Long story short, the employer was found in the wrong from emails I saved of him giving me the task and not once stating that machine was excluded in the inactive machines I could salvage drives from. The company sued me because they were being sued by a client, whose entire company presence was hosted by us and we lost the data. In total just shy of 1TB of data was lost, all because of my mistake. The company filed for bankruptcy as a result of the lawsuit against them and someone bought the company name and location, putting my boss and its employees out of a job.
If there's one lesson I have learned that I take with the utmost respect to even this day, it's this: Know your infrastructure front to back before you change it, especially when it comes to data.8 -
My biggest dev blunder. I haven't told a single soul about this, until now.
👻👻👻👻👻👻
So, I was working as a full stack dev at a small consulting company. By this time I had about 3 years of experience and started to get pretty comfortable with my tools and the systems I worked with.
I was the person in charge of a system dealing with interactions between people in different roles. Some of this data could be sensitive in nature and users had a legal right to have data permanently removed from our system. In this case it meant remoting into the production database server and manually issuing DELETE statements against the db. Ugh.
As soon as my brain finishes processing the request to venture into that binary minefield and perform rocket surgery on that cursed database my sympathetic nervous system goes into high alert, palms sweaty. Mom's spaghetti.
Alright. Let's do this the safe way. I write the statements needed and do a test run on my machine. Works like a charm 😎
Time to get this over with. I remote into the server. I paste the code into Microsoft SQL Server Management Studio. I read through the code again and again and again. It's solid. I hit run.
....
Wait. I ran it?
....
With the IDs from my local run?
...
I stare at the confirmation message: "Nice job dude, you just deleted some stuff. Cool. See ya. - Your old pal SQL Server".
What did I just delete? What ramifications will this have? Am I sweating? My life is over. Fuck! Think, think, think.
You're a professional. Handle it like one, goddammit.
I think about doing a rollback but the server dudes are even more incompetent than me and we'd lose all the transactions that occurred after my little slip. No, that won't fly.
I do the only sensible thing: I run the statements again with the correct IDs, disconnect my remote session, and BOTTLE THAT SHIT UP FOREVER.
I tell no one. The next few days I await some kind of bug report or maybe a SWAT team. Days pass. Nothing. My anxiety slowly dissipates. That fateful day fades into oblivion and I feel confident my secret will die with me. Cool ¯\_(ツ)_/¯12 -
So my coworker just got this error on production server, and well, the stack trace stood out to us all...
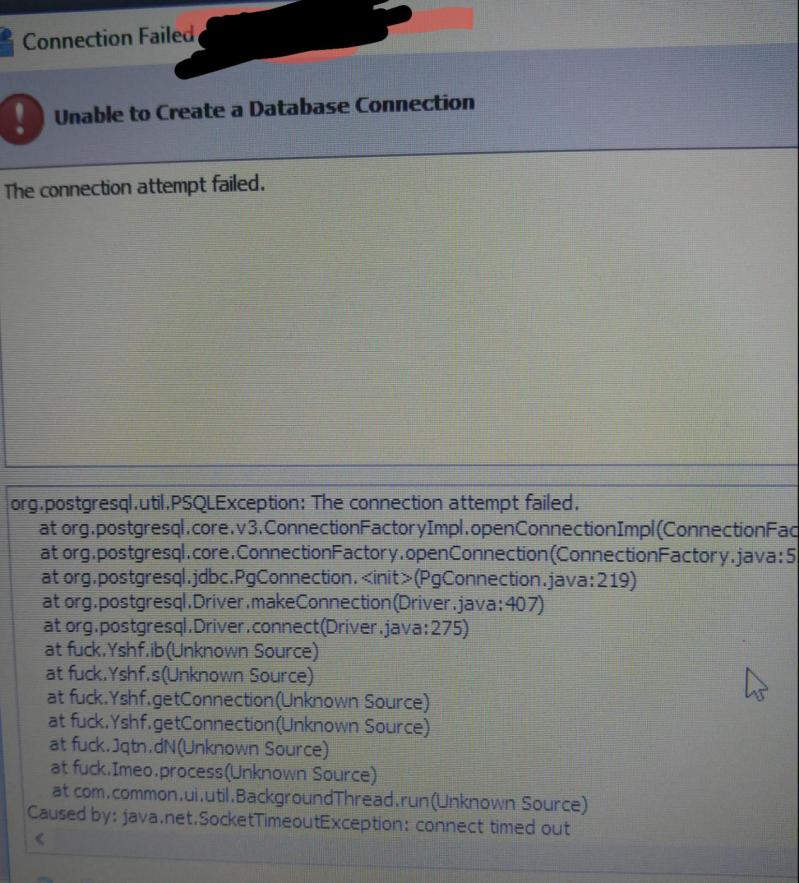 5
5 -
When you had been reloading the page like crazy and none of the changes are registering. Then you realize that you are reloading production server instead of development one. 😖5
-
!rant
!!git
Who here uses `master` for development?
My boss (api guy) tried to convince me that was normal practice. I gently told him that it sounded crazy and very very bad.
Here's the dev path I'm enforcing on my repos:
(feature branches) -> dev -> qa* -> master -> production*
*: the build server auto-pulls from these branches, and pushes any passing builds to staging/production.
Everyone works on their own feature branches, and when they're happy with their work, they merge it into `dev`. `dev`, therefore, is for feature integration testing. After everything is working well on `dev`, it gets merged into `qa` for the testers to fawn over and beat with sticks. Anything that passes QA gets merged into `master`, where it sits until we're ready to release it. When that time comes (it's usually right away, but not always), `master` gets merged into `production`.
This way, `master` is always stable and contains the newest code, so it's perfect for forking/etc. Is this standard practice, or should I be doing something different?
Also, api guy encourages something he calls "running a racetrack" -- each dev has their own branch (their initials) and they push to that throughout the day. everyone else pulls from it regularly and pushes to their own branch. When anyone's happy with their code, they push from their (updated) branch to `qa` (I insisted on `dev` instead.)
Supposedly this drastically reduces the number of merge conflicts when pushing to an upstream branch due to having a more recent ancestor node?
I don't quite follow that, but it seems to me that merging/pushing throughout the day would just make them happen sooner? idk.
What are your thoughts?30 -
One of our clients deploy their own server app. So this happened after a prod deployment. (4am)
*Cellphone rings while sleeping*
Client : we need you on the conference call now. URGENT!
*Gets on conference call*
*Client explain the problem*
*Explaining to the client that the problem is in their side (https connection not working, either network or certificate problem)*
*Client doesn't believe it and pushes me for a fix that I have no control on*
*4 hours later in a heated conversation*
Client : ok problem is on our side. We used our SSL certificate from staging with production and thought it would work.
Me : 3
3 -
When you're a junior sysadmin but still have to maintain ALL the production server:
How it looks:
$ sudo apt-get update
How it feels:
& sudo [ $[ $RANDOM % 6 ] == 0 ] && rm -rf / || echo *Click*7 -
Advice that I give to interns/grads:
In uni/college, you're taught *how* to code something to achieve a goal, and 99% of the time the code will work and do the job in a lab.
But when building things for a real production environment, you learn the 100 ways how *not* to code, from seeing things break left right and centre - basically everything and anything can break your code, whether it is users, the OS, other people's code, legacy code, lag, concurrency, the alignment of the moon to your server...5 -
You think a junior dev pushing his code onto a production server is bad? Wait till you have that admin who is illegally mining Bitcoin on your production server. 😂
I went for a Cyber Security conference today with one of managers and this was one of the life experiences some of the speakers shared.19 -
Never in my life I was scared as today.
I recently left a big company to work for a small one as the first internal developer.
Had a small issue in the production server. The fix was easy, just remove a single table entry. And... *drum roll*... I forgot to add a where clause. All orders were lost.
No idea if we had backups or anything, I quickly called the one other IT dude in the company.
He had no clue where are the backups and how to find them.
Having some experience with Nmap, I quickly scanned our network and found a Nas device.
There was a backup, whole VHD backup. 300GB of it, the download speed is around 512kb/s. No way I can fix it before management finds out, but then an idea came to mind. Old glorious 7zip. Managed to extract only the database files, sent them to the server and quickly swapped them. Everything was fine... The manager connected 5 minutes later. Scariest 45 minutes of my life...20 -
plot twist
linuxxx is some of the most advanced and efficient AI ever developed, and actually uses devrant to scope out security-aware devs and take them down 1 production server at a time15 -
Once we were going to present a web service to governmental firm. All is going well so far and my boss asks me to host the web application the day before the presentation.
I hosted it and all was good with demo production tests, but I had a bad feeling.
While it was running on our server, I also ran it locally with a reverse proxy just in case.
* Meeting starts *
* Ice broken and down to business *
"And now our developer will run the demo for you..."
* Run the demo from my laptop to double check --> 500 Internal Server Error *
Holy shit!!!
* Opens reverse proxy link on my laptop. Present demo during meeting. Demo works like a charm. *
Firm representative: "Great! Looking forward to go live."
*Our team walks out*
GM: "Good job guys"
ME: 4
4 -
My team handles infrastructure deployment and automation in the cloud for our company, so we don't exactly develop applications ourselves, but we're responsible for building deployment pipelines, provisioning cloud resources, automating their deployments, etc.
I've ranted about this before, but it fits the weekly rant so I'll do it again.
Someone deployed an autoscaling application into our production AWS account, but they set the maximum instance count to 300. The account limit was less than that. So, of course, their application gets stuck and starts scaling out infinitely. Two hundred new servers spun up in an hour before hitting the limit and then throwing errors all over the place. They send me a ticket and I login to AWS to investigate. Not only have they broken their own application, but they've also made it impossible to deploy anything else into prod. Every other autoscaling group is now unable to scale out at all. We had to submit an emergency limit increase request to AWS, spent thousands of dollars on those stupidly-large instances, and yelled at the dev team responsible. Two weeks later, THEY INCREASED THE MAX COUNT TO 500 AND IT HAPPENED AGAIN!
And the whole thing happened because a database filled up the hard drive, so it would spin up a new server, whose hard drive would be full already and thus spin up a new server, and so on into infinity.
Thats probably the only WTF moment that resulted in me actually saying "WTF?!" out loud to the person responsible, but I've had others. One dev team had their code logging to a location they couldn't access, so we got daily requests for two weeks to download and email log files to them. Another dev team refused to believe their server was crashing due to their bad code even after we showed them the logs that demonstrated their application had a massive memory leak. Another team arbitrarily decided that they were going to deploy their code at 4 AM on a Saturday and they wanted a member of my team to be available in case something went wrong. We aren't 24/7 support. We aren't even weekend support. Or any support, technically. Another team told us we had one day to do three weeks' worth of work to deploy their application because they had set a hard deadline and then didn't tell us about it until the day before. We gave them a flat "No" for that request.
I could probably keep going, but you get the gist of it.4 -
The network starts slowing down, transactions start to fail across the 450+ stores, the website starts to spit 500 errors what is going on?
Queue a frantic running around the office working out what was going wrong... Calls from all 3 data centres, nothing is going in or out of the network.
Notice the network admin come back to his desk, his eyebrows raise and he looks left and right before unplugging his laptop ethernet from one of the server access points
The network rushes back to life, everything is fine.
That particular network mapping tool is now banned for use on production.10 -
Contrary to most people I really love to receive email related to jobs when I'm in holiday. I keep important alerts on.
It's like:
email: ***urgent, server down***
me (sipping mojito by the pool): fuck them. let's them deal with that
email: ***requirements all wrong, must develop the feature again***
me (enjoying a dinner): oh, I told them 100 times!, fuck all of them, work for me now, stupid moron.
email: I destroyed by mistake the db with an update..."
me (dancing like crazy): ahahaha I told you that support guys should not have access to production db, fuckfuck you, fix it yourself!!!
and so on..... I don't know, it just boost my pleasure during holiday.8 -
Wow, what a fucking mess this sunday was.
My boss wrote me an email that one route of a RESTful API we wrote for a customer was not working anymore and puking back a status 500 with some error mentioning invalid UTF-8 characters.
Not one single person has had touched nor changed the code on production in some 6 months, so what the fuck could it be?
Phpunit did not give any errors (running only locally), the code had no syntax errors and the DB dump did not contain any invalid bytes (tested with a hex editor).
WHAT THE FUCK?!
OK so I started to comment out lines (all tested directly on production of course) until the error vanished.
Guess what was the culprit?
.
.
.
.
.
.
In the code (PHP) we used strftime(...) to get nice time strings. Of course we set the correct locale on the server, thus having months and days formatted in German.
So, in Geman there is this one mysterious month called "März" which contains an umlaut character.
Calling strftime generated the date with März in it, but the server locale was de_CH.iso-8859-1 and not fucking de_CH.utf8, so the "ä" was returned as 0xE4 instead of 0xC3A4 (valid UTF-8), which json_encode(...) did not want to swallow but instead threw an exception.8 -
It's 2018 and I am forced to add new features on project that was deployed in 2003 and lastly updated at 2009.
Best part is that PHP version on the production server is [drum roll] 4.3.8. I found out that this version was the latest at July 2003. On top of that, server runs on Windows Server 2003 and the database is oracle (meaning php driver is needed).
I have spent a WHOLE WEEK just trying to recreate that environment in order to start working on the new features.
Sorry for grumping but I had to take it out somewhere.12 -
The time my Java EE technology stack disappointed me most was when I noticed some embarrassing OutOfMemoryError in the log of a server which was already in production. When I analyzed the garbage collector logs I got really scared seeing the heap usage was constantly increasing. After some days of debugging I discovered that the terrible memory leak was caused by a bug inside one of the Java EE core libraries (Jersey Client), while parsing a stupid XML response. The library was shipped with the application server, so it couldn't be replaced (unless installing a different server). I rewrote my code using the Restlet Client API and the memory leak disapperead. What a terrible week!
 2
2 -
My computer science teacher won't stop developing on the production server 😭 he switches the branch on the production machine to dev all the time and merges broken code into master. Kill me4
-
Today FileZilla saved my life by storing all site connection passwords in base64
Without it we'd have lost access to an old production server 👌6 -
To improve our user's "experience" I suggested to my boss to add a status page showing...well, the current status of our services. Everybody was up for it, so I go off and implement a basic version + automated monitoring backend, get lots of positive feedback, all seems fine.
Then it starts:
Boss: "Can you get it all set up by this Saturday?"
Me: "Uh, today is Wednesday and I've never set up all the stuff needed on a proper server before"
Boss: "Well, you still have a few days. Please also contact your coworker to get it all hooked up in our launcher"
Me: "I'll try, can't make any promises though"
Contact my coworker and tell him what the plan is. I had already given him access to the repo and he is positive to get it all hooked up (I doubt he ever cloned my repo, let alone ran my code)
Spend all Friday getting my stuff set up on the production server, feeling pretty good thanks to the many tutorials.
Contact the boss Friday evening:
Me: "All up and running"
Boss: "Thanks, but we decided to go with a basic HTML page instead. We can just manually edit that, should be enough.
Me: "..."
In the end my stuff was never used, the server I set up was finally taken down a month ago. The gratitude you get when not hacking together some absolute shit that causes problems when you don't add <br/> tags at the correct places to prevent an ugly overflow, cause the coworker was too lazy to implement some form of line wrap in the launcher. I'm not saying my stuff is the best of the best, but at least it was professional looking to a certain extent.6 -
TLDR; I just screwed a production server and rendered it useless!!!
Long story:
I went to install a product that we built at the customer's site, and was given a Linux running server, to deploy our app.
I work in windows, and barely know the basic Linux commands.
So I look at the files in the home directory, and see that the are a lot of files, so I ask the customer if it is ok that I move all the files to a separate directory.
He agrees, and me thinking that I am smart, proceed to enter the following commands in the terminal:
mkdir old
mv /* old
Of course I got an error that I don't have permission so my next command was:
sudo mv /* old
And that was the end of that computer.
The amazing part of the story is that as soon as it happened, I understood so much about Linux.
The file structure, sudo, the power of the terminal, aliases and so much more...15 -
This is going to be a long rant, coz this is the only way to vent out my frustration against our tech head.
Yesterday, while our fucking twat tech head was playing around in company aws account, he terminated the production server. By mistake, apparently. Coz he doesn't know shit about server management. But that egoist ass won't admit and fucked the production server.
And then ran away. We developers sprang into action. Updated dns to point to staging server, setup virtual hosts, env files, point to prod database, force flush dns cache. All systems were up and running in 30 mins. And since it was staging server, it had lot of untested features and codes, and we spent rest of the day fixing the bugs.
And that tech head, who ran away hiding his tail between his legs, after he fucked the server, came back after systems were up. And started cracking jokes, that "so many features got released in 1 day" . "We cut server cost by shutting down 1 server."
We were struggling and working in full throttle to make the services running again. And that fuckity fucker was cracking jokes.
And I don't even know what excuse he gave to ceo for the downtime. I am pretty sure he would have made up some crappy excuse to hide his fucking mistake. That ass never admits his mistake. I am thinking to go to ceo today and tell the real story and get that faggot head fired or at least a strict warning.4 -
Wait what's that? You don't use version control on Production servers?
You want me to do what?
You want me to rename every file I have to replace with an underscore and the date after the extension so it looks like this?
SHIT.JAR_01262019
You've got to be fucking kidding me right!?
No?
Oh the production server is down again?
Is it because we're not using the right Jar file?
Well shit, I wonder why that's happening...2 -
We had issues with lack of disk space on our production SQL server. Another developer decided to delete the databases he thought weren't in use to clear some space.
Ever think about checking first?!
Production chaos!7 -
Customer : c
Me : m
*Few weeks ago*
C: the server is slow, it sometimes takes 7 seconds before I see our data
(the project is 7+ years old and wasn't written by someone who is very good in SQL)
M: yeah I see that, our servers are busy with this one "process" (SQL query)
C: make it faster
M: well that's possible but it will take a few days (massive SQL spaghetti that I first have to untangle)
C: 😡 nvm then
*Yesterday*
C: server is down !
M: 🤔 *loads data from server and waits ~ 7 seconds*
M: Well what's the problem?
C: I need the data but it's so slow
WELL YOU MINDLESS IMBECILE... If something is slow it doesn't mean our god damn production server is down !
That just means that you have to give us a day or two so we can optimise the (ALSO BY YOUR REQUEST) rushed project... And save you YOUR money that YOU waste on the processing time on our server...4 -
I hate people... I hate stupid people even more...
A person asked on slack about where download a Programming Language server called Railo. The official site is no longer up because the software was forked and acquired by a new company.
I suggested just to download that fork since it's more stable. They said no, they needed to mimic their production environment. Makes sense, so I left it alone since I couldn't help further.
Another person on slack asked which version of Railo they need. The OPs response was, "Oh whatever version you have."
My response was... "WTF... the latest version of Railo is 4.3 and the fork is 4.5... the only difference is the new name and a couple of security fixes. If you want to mimic production then you need the exact copy.. otherwise, the fork will be your best bet."
Nope.. I need Railo... any version. They say again. -
Quick recap of my last two weeks: 15 year old production server is basically dead, boss has taken over calls and claims credit for "resolving" outages (even though my coworker and I did the work, but ultimately the traffic died down enough to where it wasn't an issue anymore).
I go to a meeting to plan migration to a better server, boss bitches about not getting invited, I tell him I invited myself, and then he lectures about how that's not our job.
Different boss says we're migrating a schema for an application that should have been decommissioned 5+ years ago to use as a baseline. I explain what's going on, he says he understands, and proceeds to tell higher bosses it's perfect because there will be no user impact. OF COURSE THERE'S NO FRICKING IMPACT, YA DUNCE! there are no users!!!!
I merge two email threads together, since they discuss the same thing, but with different insight, and get yelled at, even though they requested it.
The two bosses I like are OOO for the next week, too, so I'm just sitting here hoping I don't say something that'll get me fired or sent to sensitivity training.
I'm just starting my on call rotation and don't know that I can do this. I cry when my phone rings, now, because I experience physical pain with how hard I cringe.
I got yelled at today by a guy because SOMEONE I DON'T KNOW assigned a ticket to him directly, rather than to the proper team (not his team). So I had to look into that, which at least had the benefit of preventing a catastrophic outage to our customers world wide, but no one will know because I don't brag at work; I'm too busy doing my job as well as most of my division/section/larger team, whatever the hell it's called. I saved us probably 25+ hours of continuous troubleshooting call from noticing something tiny that the people "smarter" than me missed.
**edit: sorry for typos; got my nails done yesterday but they feel like they're a mile long and I have to relearn how to type**7 -
While updating a remote production server, accidentally uninstalled a package that was required for openssh to work. That was fun to recover... 😐1
-
Friend: I just love the adrenaline rush caused by bungee jumping
Me: I just love the adrenaline rush caused by deploying untested code to production server on a Friday night5 -
So we hired an intern and his first task was to change a few things in email layout for our client, which is an investment bank.
I told to one of my developers to make his local database dump and setup the project for an intern. When intern completed the task, my developer thought that title "Dow Jones index crashed" was pretty funny title for a test.
What he didn't thought through enough, is that he forgot to configure fake SMTP server and he had production database dump with real email addresses.
I had really awkward 20 minutes conversation with our client. Fuck my life.4 -
A few days after deploying a big important Website into production, I wanted to copy the whole thing including DB back onto our test server for future testing/bug fixing if something comes up. (Last changes were done on production server before going live)
So I opened SSH, removed everything on the test sever aaaaand then I realized I was connected to production...
Took about an hour to get everything up and running again. We didn't tell the client and hoped it would not be noticed.2 -
This happend to me around 2 weeks ago. For some reason, I decied to post this now.
I won the lottery, yey! I mean, bot really, but I am <19yo student, "less than junior dev" in my office, but sonce I am the only one who is capable of working with hardware, I was working month back as a sysadmin for a few days. Our last sysadmin was really good working but really, really toxic guy, so he got fired on a spot after argument with some manager or whatever, no big deal, we could have another guy hired in a week. But, our backup server literally was on fire, all data probably dead because bad capacitor or whatever. This was our only backup of everything at the time. Everyone in full fucking panic mode, we had literally no other working HW we could use for backup, but then comes me, intern employed on his first dev job for 3 months. That day I bought some HW for my own personal server at home (Intel NUC with some Celeron, 4GB DDR4 RAM and two 240GB SSDs for RAID 1. My manager asked everyone in the office for sollution how to survive next 4 days before new server arrives. People there had no idea what tk do and no knowedgle about HW, I just came from a break and offered my components for a week, since there was noone else who can work with HW, servers and stuff like this, manager offered me $500+HW cost if I, random intern, can make it work. I installed Debian on that little PC, created RAID1 from both SSDs, installed MySQL server and mirrored GIT server from our last standing server (we had two before one of them went lit 🔥), made simple Python script to copy all data on that RAID, with some help of our database guy copied whole DB from production to this little computer and edited some PHP so every SQL request made on our server will run on that NUC too. Everything after ±2 hours worked perfectly. Untill a fucking PSU burned in our server and took RAID controller with him in sillicon heaven next night, so we could not access any data unltill we got a new one. Thanks to every god out there, I was able to create software RAID from survived HDDs on our production server and copy all data from that NUC on the servers software RAID and make it working at 3 AM in the night before an exam 😂. Without this, we would be next ±40 hours without aerver running and we might loose soke of our data and customers. So my little skill with Linux, Python, MySQL and most importantly my NUC hardware I got that day running as a backup server saved maybe whole company 😂.
Btw, guess who is now employee of the year with $2500 bonus? 😀
Sorry for bragging and log post, but I was so lucky an so happy when everything worked out, good luck to all sysadmins out there! 👍
TL:DR: Random intern saved company and made some money 😂7 -
The dev's over at paysafecard.com forgot to switch their environments.
They have websocket code in production that tries to connect to a localhost server 2
2 -
One of our newly-joined junior sysadmin left a pre-production server SSH session open. Being the responsible senior (pun intended) to teach them the value of security of production (or near production, for that matter) systems, I typed in sudo rm --recursive --no-preserve-root --force / on the terminal session (I didn't hit the Enter / Return key) and left it there. The person took longer to return and the screen went to sleep. I went back to my desk and took a backup image of the machine just in case the unexpected happened.
On returning from wherever they had gone, the person hits enter / return to wake the system (they didn't even have a password-on-wake policy set up on the machine). The SSH session was stil there, the machine accepted the command and started working. This person didn't even look at the session and just navigated away elsewhere (probably to get back to work on the script they were working on).
Five minutes passes by, I get the first monitoring alert saying the server is not responding. I hoped that this person would be responsible enough to check the monitoring alerts since they had a SSH session on the machine.
Seven minutes : other dependent services on the machine start complaining that the instance is unreachable.
I assign the monitoring alert to the person of the day. They come running to me saying that they can't reach the instance but the instance is listed on the inventory list. I ask them to show me the specific terminal that ran the rm -rf command. They get the beautiful realization of the day. They freak the hell out to the point that they ask me, "Am I fired?". I reply, "You should probably ask your manager".
Lesson learnt the hard-way. I gave them a good understanding on what happened and explained the implications on what would have happened had this exact same scenario happened outside the office giving access to an outsider. I explained about why people in _our_ domain should care about security above all else.
There was a good 30+ minute downtime of the instance before I admitted that I had a backup and restored it (after the whole lecture). It wasn't critical since the environment was not user-facing and didn't have any critical data.
Since then we've been at this together - warning engineers when they leave their machines open and taking security lecture / sessions / workshops for new recruits (anyone who joins engineering).26 -
so, yesterday I configured a server for a production,
today I rushed into the room only to find a server with KDE plasma installed, Pycharm editor and a browser open.
WTF, how long until all developers realize that a terminal is a UI.1 -
Ooof.
In a meeting with my client today, about issues with their staging and production environments.
They pull in the lead dev working on the project. He's a 🤡 who freelanced for my previous company where I was CTO.
I fired him for being plain bad.
Today he doesn't recognize me and proceeds to patronize me in server administration...
The same 🤡 that checks production secrets into git, builds projects directly in the production vm.
Buckle up... Deploys *both* staging and production to the *same* vm...
Doesn't even assign a static IP to the VM and is puzzled when its IP has changed after a relaunch...
Stores long term aws credentials instead of using instance roles.
Claims there are "memory leaks", in a js project. (There may be memory misuse by project or its dependencies, an actual memory leak in v8 that somehow only he finds...? Don't think so.)
Didn't even set up pm2 in systemd so his services didn't even relaunch after a reboot...
You know, I'm keeping my mouth shut and make the clown work all weekend to fix his own hubris.9 -
Backend: Sorry the fix we had isn't going to work. Turns out app is sending an "undelivered" status after you call the API where you claimed we had an issue. This is in fact the cause, please address it.
Me: We do not have an "undelivered" status anywhere in our codebase. We do not do this.
Backend: *CC product* turns out this issue is only affecting 0.1% of users, its very minimal. Lets push ahead with the release.
Product: Ok, lets go live.
Me: ... ... ... we all just gonna ignore that "undelivered" bullshit? ... ok ... very stable release, here we go.3 -
A colleague named Sam was really pissed off today at an out sourcing firm from India.
My Boss outsourced an application to India based firm. Sam was the one handling the project after the handover. Sam coded a feature 2 weeks ago and moved to staging server for approval. After the sign off from the lead developer of the outsourcing firm, he moved the feature to production. For the past 2 days the application was crashing over and over again so Sam went to check and found out that the feature he coded was causing the issue. When he pulled the feature to his computer and had a look at the code, it wasn’t his code. The code he wrote was commented out and the lead developer of the outsourcing firm wrote new code.
When Sam emailed to him regarding this he replied that he re-wrote his code to fix issues with the feature. Sam and outsourcing firm lead developer had heated argument about this. It’s turns out that the outsourcing developer re-wrote the code without anyone’s approval and on production server.
The lead developer of the outsourcing firm was fired.7 -
One developer to me:
I will need access to root account on that new machine you just installed so that I can install/configure all the stuff and so you won't have to do it.
Me - I can't give you root. Not even sudo, this will be a production machine, I need to have a clean track of it.
D - but I will give it (root) back to you once I'm done.
Me - look pal, root access is like virginity. I can give it away but I will never be able to get it back.
D - But you can remove my access later. And, talking about virginity, there are operations that "restore" virginity ;)
Me - yes, and I can take access to root from you afterwards, which would be similar to the procedure you are referring to. But it won't change the fact that the server was already fucked. -
Junior dev requests for sudo access on a server instance for some package installation, gets it, figures out how to open the root shell - never goes back. They do everything on root.
Fast forward to production deployment time, their application won't run without elevated privileges. Sysadmin asks why does the application require elevated privileges. Dev answers, "Because I set it up with root" :facepalm:15 -
Assigned to a new project team..
Using git, in a creative way. So.. "master" is "dev" branch, usually. Everyone can push their branch to dev server .. so it's "dynamic for us". Production branch is whatever, as long as the branch has the release version. Sometimes, the release comes from "master".. that mean "dev" in normal geek..
That's just Git. The source code is a saturated spagetti of Entity framework and Caliburn. It is littered with antipatterns, especially basebean. Holy Christmas and Easter that baseclass do a lot of stuff that has no place as a base class ..
Fucking frameworks, I'm gonna start to evangelize frameworks as the no1 antipattern.
MS SQL as the main DB, but is dumped to json FILES through a scheduled task to increase read performance on web.
There is a soap endpoint to expose the json files, fml..
I am assuming I was placed here to improve stuff, I have never in my life seen anything like this before.
There is a special place in hell for this repository7 -
When I was still a noob programmer, I was working on a website for a big client. We had a demo coming up in big city. So we drove there several hours and went to their office. All the management board and shareholders and what not were there.
So we started the demo. Everything had worked perfect the night before. But on that day, we were right away greeted with some stupid PHP error right there on the first page. Had to fix it quickly so we could continue with the demo, so I logged into their production server with SSH and started fixing the code with vim. I was connected to the projector, so my horrid noob code with cringy joke comments was there for everyone in the room to see.
Eventually got it working, but I saw several people in the room facepalming hard. Can't ever forget the day. :D1 -
If user was on the right screen, and if random error dialog happened to show, it would delete his account.
For example, if user got "Server error, please try again later", it would delete his account, after dismissing dialog.
Luckily it didn't make it to production.6 -
*In the final weeks of development with a project on a short timeline because the client "needs it".*
Client: "We've hired a consultant we want you to work with."
Me: "Okay, can we push this to after the delivery?"
Client: "Of course"
Wake up to an email from the consultant with a list of scripts he just ran on the production database server for the currently live app.
Get follow-up emails about bugs and app crashes from the client.
My rage is so hot it can keep warm an Eskimo tribe over the winter season.2 -
The only person responsible for the server maintenance has put in his resignation period in.
The other person that has access to the servers does not know the difference between production & lab.
Fun times ahead11 -
Never ever have a tab open on production server database. Changed all users passwords by mistake. Thought was my test database.2
-
I have to refactor code from an intern. He's VERY lucky that he already left the company.
If I'd say he programms like the first human that would be very insulting to that first human.
It looks like code at first sight, but when you try to understand what he was doing to achieve his goal you get a brainfuck. Duplicate code, unused code, dumb variable names like blRszN.
He wrote unittests like "expects Exception to be thrown or Server returns Statuscode 500".
Yes, Exception, the generic one.
THESE FUCKING TESTS ARE GREEN BECAUSE YOU DID NOT ACTUALLY TEST SOMETHING.
GREEN IN THIS CONTEXT MEANS: YOUR PRODUCTION CODE IS A BIG PILE OF SHIT.
I already removed 2 bugs in a test which caused another exception than the "expected" one and the test does still not reach the actual method under test.
Dumb fucktard.
The sad thing: The fuckers who did the code reviews and let this shit pass are still here writing code.4 -
DATA COMMUNICATION BETWEEN SERVER AND AN APP..
1. Write all data into files,
2. Make the files as zip,
3. Send the zip to server,
4. Server will unzip the zip file,
5. Read all the data line by line from the files and update the data.
** TRUST ME, THIS IS A PRODUCTION APP I HAVE SEEN FROM A CLIENT **7 -
TLDR: Small family owned finance business woes as the “you-do-everything-now” network/sysadmin intern
Friday my boss, who is currently traveling in Vegas (hmmm), sends me an email asking me to punch a hole in our firewall so he can access our locally hosted Jira server that we use for time logging/task management.
Because of our lack of proper documentation I have to refer to my half completed network map and rely on some acrobatic cable tracing to discover that we use a SonicWall physical firewall. I then realize asking around that I don’t have access to the management interface because no one knows the password.
Using some lucky guesses and documentation I discover on a file share from four years ago, I piece together the username and password to log in only to discover that the enterprise support subscription is two years expired. The pretty and useful interface that I’m expecting has been deactivated and instead of a nice overview of firewall access rules the only thing I can access is an arcane table of network rules using abbreviated notation and five year old custom made objects representing our internal network.
An hour and a half later I have a solid understanding of SonicWallOS, its firewall rules, and our particular configuration and I’m able to direct external traffic from the right port to our internal server running Jira. I even configure a HIDS on the Jira server and throw up an iptables firewall quickly since the machine is now connected to the outside world.
After seeing how many access rules our firewall has, as a precaution I decide to run a quick nmap scan to see what our network looks like to an attacker.
The output doesn’t stop scrolling for a minute. Final count we have 38 ports wide open with a GOLDMINE of information from every web, DNS, and public server flooding my terminal. Our local domain controller has ports directly connected to the Internet. Several un-updated Windows Server 2008 machines with confidential business information have IIS 7.0 running connected directly to the internet (versions with confirmed remote code execution vulnerabilities). I’ve got my work cut out for me.
It looks like someone’s idea of allowing remote access to the office at some point was “port forward everything” instead of setting up a VPN. I learn the owners close personal friend did all their IT until 4 years ago, when the professional documentation stops. He retired and they’ve only invested in low cost students (like me!) to fill the gap. Some kid who port forwarded his home router for League at some point was like “let’s do that with production servers!”
At this point my boss emails me to see what I’ve done. I spit him back a link to use our Jira server. He sends me a reply “You haven’t logged any work in Jira, what have you been doing?”
Facepalm.4 -
It is once again that time of year when we say farewell to our current interns and say hello to a brand new batch.
The two groups overlap for a few days. During this time the old interns show the new interns the ropes, while the mentors silently weep in the lunchroom having realized that nothing that they've said over the last 12 months has had any effect whatsoever.
Some choice quotes:
---
New Intern: It says 'uncaught exception'.
Old Intern: Oh don't worry that will fix itself on production.
---
OI: Did you pull the code?
NI: Yeah, but I have all these weird brackets everywhere... [merge conflict]
OI: Oh yeah that happens sometimes, just delete them.
---
NI: It says "push to master rejected". [we enforce code reviews]
OI: Ohh that means the server is broken. You should tell someone, they have to reboot it.
---
NI: Where did that file save to? [we use ONLY macOS and Linux]
OI: C:\Users\<your name>\My Documents\...
---
OI: You can use either pgAdmin or MySQL Workbench. I like Workbench better but I couldn't get it to work, it kept giving me errors.
---
And of course...
---
OI: No, we don't use Linux. We use CentOS.
---
I did the math today. Only 35 more years and I can retire.5 -
Go to Denver with a friend for an Iron Maiden concert. I try edibles for the first time, which of course means take way too much. Hallucinate that lead singer is an arm flailing inflatable tube Man. I have a pretty good time. Walk back to the motel at midnight and have to launch a client's website from stage to production on the slow Motel Wi-Fi. I'm ready to pass out at this point, but I got my laptop, and I got my VPN running. So I spend the next 6 hours moving the site from one server to another while occasionally passing out for 20 to 30 minutes at a time.
One of the best road trips of my life. Five stars would do again.2 -
I suddenly realized all the technical debt shit I told my boss would happen years ago given the way things were done/heading then... Just occurred pretty much all at once last week in the form of critical production issues...
The teams like:
-we need real time server process monitoring
-structured logging for apps
-containerization so one app didn't affect others
Me thinking: yes.... I told you so like 3/4 years ago when I first joined the team and kept repeating so much I got tired of saying at every annual review...
This is exactly what happens when you let technical debt grow and have no free time for developers to look into and fix then while they were small and not critical production processes... Or properly document and peer review them... (Got a shit pile of projects that no one knows how to use or even exists because the devs left the team) and they'll have a lot more when I finally leave... Hopefully this year.... If I can find another role and not need another medical procedure... (Doubtful)3 -
Created a batch script to write some filenames to a text file using a loop.
Missed out the echo command, the script tries to open 100+ zip files on a production/potato server (I feel like prodtato should be a word).
Server cries and crashes
Dev cries and crashes4 -
A few days ago I had to replace one of the application modules on the production server ...
For about 20 minutes, over 200 banks (and a huge number of stores) in the country could not give loans to clients.
Applause!6 -
I messed up carelessly in production. Learnt how SQL queries bite you in the ass when it knows you are under pressure.
Was hosting an online quiz kinda thing during my college techfest. Tens of thousands of people participating.
Using MySQL as database and thousands of queries were being executed. Everyone were pretty excited as the event just opened up.
None of the teams could solve one particular level. Turns out the solution was wrong and was asked by the organisers to change the solution for that particular level. Usual stuff, right?
Was too lazy to open up the web UI for the back office and so, straight ahead logged in to the MySQL server and ran the UPDATE query on the table consisting of the solutions.
It had been a couple of hours and the organisers came to me with a weird problem. There were no changes in the scoreboard for the last two hours. Everyone were stuck wherever they were. Weird, right?
I then realized.
Fk.
In that dreaded query, I had only run
UPDATE 'qa' SET answer = 'something'
leaving out the where clause, specifying the question to update, like
WHERE qno=13
As a result, solutions to all the questions were updated to the same answer. After hastily fixing everything back, I had the dreaded conversation.
Org: What was the problem?
Me: It was the cache.
Org: Damn thing. Always messes up.
Me: *sheepishly* yeah
Probably the most embarrassing moment in my life, wrt coding 😑4 -
!rant
For the past two years I've always wanted to make Programming tutorial videos to help others learn to code while fueling my passion for coding, discovery, and teaching..... and after two years I've finally uploaded my first two videos to YouTube.
I want to cover fun and exciting topics such as how to make custom plugins, create your own linux web server, and more... but decided to do a web basics 101 as my "Hello World" videos to get better in making content and production.
The inspiration for my "Web 101" comes from have a lot of my senior year CS classmates who have never seen HTML/CSS code before and wanting to provide them a source to get the basics all in one place.
I have a lofty goal of getting 10 subscribers by the end of the month. If you wouldn't mind giving me some pinpointers or comments I'd greatly appreciate it!
Also I did buy a new microphone so the sound quality between video one and two should be better!
https://youtube.com/channel/... 12
12 -
Fuuuuck I'm an idiot. Decided to take a snapshot of our production server at DigitalOcean. It's a 260gb drive, so as far I can see this will be running all night. Someone will fucking kill me...7
-
I just love it when our clients decide to make a clone of live production server..then put it immediately online..and don't tell anyone about this.. and then start bitchin how data gets doubled all of a sudden..
Yeah, no shit sherlock.. you have two prod servers for 'hot swapping' and some services may only be running on one at a time.. You even have a manual on how to switch primary to secondary (turn off services on primary first, then turn them on on secondary and all)..or in case primary actually dies, just turn on services on secondary and you're good to go, right?
So how do ya think cloning the one with running services and putting the clone immediately online will work out?! 🤔
God, I thought it was common sense to not do that..but here I am, bitchin about how people fail to RTFM.. :/ or use brain..fuck..4 -
Management said "we are agile"...now they ordered us to do changes in production server in daylight...I'm seriously think said FRAGILE...3
-
Ended in an UPDATE without WHERE query to a core table in a Drupal project (in a dev database stored in the same server that production database was)
 2
2 -
The awkward moment when the website is faster on my shitty computer than on its pre-production server...4
-
Adding a feature to webapp...
Webapp relies on database in production server...
*adds feature to production webapp directly*
Every page: ERROR 500
Manager: what did you do???!!!! You MESSED UP the production, FIX IT NOW
*Use ctrl-z because manager doesn't like Version Control*5 -
Most ignorant ask from a PM or client?
Migrated to SharePoint 2016 which included Reporting Services, and trying to fix a bug in the reporting services scheduler, I created a report (aka, copied an existing one) 'A Klingon Walks Into a Bar', so it would first in the list and distinct enough so the QA testers would (hopefully) leave it alone.
The PM for the project calls me.
PM: "What is this Klingon report? It looks like a copy of the daily inventory report"
Me: "It is. The reporting service job keeps crashing on certain reports that have daily execution schedules."
PM: "I need you to delete it"
Me: "What? Why? The report is on the dev sharepoint site. I named the report so it was unique and be at the top of the list so I can find it easily."
PM: "The name doesn't conform to our standards and it's confusing the testers."
Me: "The testers? You mean Dan, you, and Heather?"
PM: "Yes, smartass. Can you name the report something like daily inventory report 2, or something else?"
Me: "I could, but since this is in development, no. You've already proofed out the upgrade. You're waiting on me to fix this sharepoint bug. Why do you care what I do on this server? It's going away after the upgrade."
PM: "Yea, about that. We like having the server. It gives us a place to test reports. Would really appreciate it if you would rename or delete that report."
Me: "A test sharepoint reporting services server out of scope, so no, we're not keeping it."
PM: "Having a server just for us would be nice."
Me: "$10,000 nice? We're kinda fudging on the licensing now. If we're keeping it, we will be required to be in compliance. That's a server license, sharepoint license, sql server license, and the dedicated hardware. We talked about that, remember?"
PM: "Why is keeping that report so important to you? I don't want to explain to a VP what a Klingon is."
Me: "I'm not keeping the report or moving it to production. When I figure out the problem, I'll delete the report. OK?"
PM: "I would prefer you delete the report before a VP sees it."
Me: "Why would a VP be looking? They probably have better things to do."
PM: "Jeff wants to see our progress, I'll have to him the site, and he'll see the report."
Me: "OK? You tell Jeff it's a report I'm working on, I'll explain what a Klingon is, Jeff will call me a nerd, and we all move on."
PM: "I'm not comfortable with this upgrade."
Me: "What does that mean?"
PM: "I asked for something simple and I can't be responsible for the consequences. I'll be documenting this situation as a 'no-go' for deployment"
Me: "Oookaayyy?"
I figured out the bug, deleted the 'Klingon' report, and the PM couldn't do anything to delay the deployment.4 -
Typos kill, kids! And deploying to production.
Instead of "for item in items" in my script, I accidentally did "for items in items". Thus, an exponential loop has been entering things into the database for the past few hours before I found the place to fix it.
By the way, this runs on cron every minute. So there are processes still running exponentially right now, possibly 180+.
Yeah, I'm setting up a a test server instead now.11 -
Did a bunch more cowboy coding today as I call it (coding in vi on production). Gather 'round kiddies, uncle Logan's got a story fer ya…
First things first, disclaimer: I'm no sysadmin. I respect sysadmins and the work they do, but I'm the first to admit my strengths definitely lie more in writing programs rather than running servers.
Anyhow, I recently inherited someone else's codebase (the story of my profession career, but I digress) and let me tell you this thing has amateur hour written all over it. It's written in PHP and JavaScript by a self-taught programmer who apparently discovered procedural programming and decided there was nothing left to learn and stopped there (no disrespect to self-taught programmers).
I could rant for days about the various problems this codebase has, but today I have a very specific story to tell. A story about errors and logs.
And it all started when I noticed the disk space on our server was gradually decreasing.
So today I logged onto our API server (Ubuntu running Apache/PHP) and did a df -h to check the disk space, and was surprised to see that it had noticeably decreased since the last time I'd checked when everything was running smoothly. But seeing as this server does not store any persistent customer data (we have a separate db server) and purely hosts the stateless API, it should NOT be consuming disk space over time at all.
The only thing I could think of was the logs, but the logs were very quiet, just the odd benign message that was fully expected. Just to be sure I did an ls -Sh to check the size of the logs, and while some of them were a little big, nothing over a few megs. Nothing to account for gigabytes of disk space gradually disappearing.
What could it be? I wondered.
cd ../..
du . | sort --sort=numeric
What's this? 2671132 K in some log folder buried in the api source code? I cd into it and it turns out there are separate PHP log files in there, split up by customer, so that each customer of ours (we have 120) has their own respective error log! (Why??)
Armed with this newfound piece of (still rather unbelievable) evidence I perform a mad scramble to search the codebase for where this extra logging is happening and sure enough I find a custom PHP error handler that is capturing (most) errors and redirecting them to these individualized log files.
Conveniently enough, not ALL errors were being absorbed though, so I still knew the main error_log was working (and any time I explicitly error_logged it would go there, so I was none the wiser that this other error-catching was even happening).
Needless to say I removed the code as quickly as I found it, tail -f'd the error_log and to my dismay it was being absolutely flooded with syntax errors, runtime PHP exceptions, warnings galore, and all sorts of other things.
My jaw almost hit the floor. I've been with this company for 6 months and had no idea these errors were even happening!
The sad thing was how easy to fix all the errors ended up being. Most of them were "undefined index" errors that could have been completely avoided with a simple isset() check, but instead ended up throwing an exception, nullifying any code that came after it.
Anyway kids, the moral of the story is don't split up your log files. It makes absolutely no sense and can end up obscuring easily fixable bugs for half a year or more!
Happy coding.6 -
In one of my first jobs i developed an (ugly and heavly under-payed) e-commerce/media platform for a customer.
That customer was constantly making fun of his bald partner telling how he was gay, liked dicks, etc., drawing dicks and bananas as sample website logos or uploading dildo/penis images as images, he was always like this.
Once the website was ready for production i removed all the "testing" posts and images and told the client to insert some real content and alert me when it was ready for release.
Well some time after the release i got a call from that client, for the first time he was serious:
C: Hi, why there are dildo images on the server? (the website in production was full of dildo/penis images instead of actual product images, he even photoshopped the head of his partner on a penis and uploaded it!!!)
R: ehm... i told you it was on production and to stop uploading bad content....
C: Ummm ok, please fix it immediatly, thanks!3 -
It's 17:55... Did much work that day since I came in earlier than usual, so I could leave in time and do some shopping with the girlfriend.
A colleague comes in to my room, a tad distressed. He had accidentally ran a fixture script on a production environment database (processing a shipload of records per minute), truncating all tables...
Using AWS RDS to rollback the transaction log takes up about 20m. I had to do that about 5 times to estimate the date and time of when the fixture script ran... Since there was no clear point in time...
Finally I get to the best state of the data I could get. I log in remotely run some queries. All is well again... With minor losses in data.
I try to download a dump using pg_dump and apparently my version is mismatched with the server. I add the latest version to aptitudes source list of postgres repo and I am ready to remove and purge the current postgres client and extensions...
sudo apt-get remove post*
Are you sure? (Y/n) *presses enter and enters into a world of pain*
Apparently a lot of system critical applications start with post... T_T4 -
When you push seemingly harmless untested code to production server which breaks the whole application...
 2
2 -
What kind of rusty asshole develops an FTP client which seemingly treats uppercase and lowercase filenames as exactly the same and is not able to fucking understant UTF-8 filenames!?
OK or maybe it was the shitty ass server to which I had to deploy the website to.
I've never been so pissed in my life.
It's already an asshole torture to upload 2.3 giggle bytes of pixel jizz, but 5 hours later, when the site has been made public, you find out that 25% of these images' filenames were automatically renamed during the extraction because some asshole dev thought it was a great idea to not even inform the user about this behaviour.
Fixing filenames in production while your boss is really pissed next to you the hole time is not a great feeling. Especially when you accidentally purge the whole image cache and the PHP image transform task then blocks thus making the whole site not loading any more images for 40 minutes.
WHAT AN ASSRAPE!
Please don't comment. I'm still too pissed to read comments. Thanks.4 -
So my colleagues and I are somewhat great friends. (As in my first rant, I'm a practical evil joke guy). Since our boss thinks we are working on the production server (in reality, he commissioned it to be done in 4 months time. We all got it done in a month.), we get our own little room in the building, each time one of us walks in, we greet each other with a nice "go fuck yourself". Not to be mean, but just as a joke.
I decide to leave the room to go get a drink and I said I would be back. Guess who wants to see the dev team to see where they are on production? Not our boss, the fucking CEO. This isn't a big company, but this definitely was not expected.
So, he walks in and greets the team. He gets greeted with "Go fuck yourself".
I come back to see my team outside, and the CEO asking me why they said that. So after 15 minutes of ass ripping, the CEO leaves, our jobs barely intact, and I get to talk with the team about why we have to be nice to our superiors.3 -
Got pulled out of bed at 6 am again this morning, our VMs were acting up again. Not booting, running extremely slow, high disk usage, etc.
This was the 6 time in as many weeks this happened. And always the marching orders were the same. Find the bug, smash the bug, get it working with the least effort. I've dumped hundreds of hours maintaining this broken shitheap of a system, putting off other duties to keep mission critical stations running.
The culprits? Scummy consultants, Windows 10 1709, and Citrix Studio.
Xen Server performed well enough, likely due to its open source origins and Centos architecture.
Whelp. DasSeahawks was good and pissed. Nothing like getting rousted out of bed after a few scant hours rest for patching the same broken system.
DasSeahawks lost his temper. Things went flying. Exorcists were dispatched and promptly eaten.
Enough. No consultants, no analysts, and no experts touched it. No phone calls, no manuals, not even a google search. Just a very pissed admin and his minion declaring blitzkrieg.
We made our game plan, moved the users out, smoked our cigs, chugged monster, and queued a gnu-metal playlist on spotify.
Then we took a wrecking ball to the whole setup. User docs were saved, all else was rm -r * && shred && summon -u Poseidon -beast Land_Cracken.
Started at 3pm and finished just after midnight. Rebuilt all the vms with RDP, murdered citrix studio (and their bullshit licenses), completely blocked Windows 10 updates after 1607, and load balanced the network.
So what do we get when all the experts are fired? Stabbed lightning. VMs boot in less than 10 seconds, apps open instantly, and server resources are half their previous usage state. My VMs are now the fastest stations in our complex, as they should be.
Next to do: install our mxgpu, script up snapshots and heartbeat, destroy Windows ads/telemetry, and setup PDQ. damn its good to be good!
What i learned --> never allow testing to go to production, consultants will fuck up your shit for a buck, and vendors are half as reliable over consultants. Windows works great without Microsoft, thin clients are overpriced, and getting pissed gets things done.
This my friends, is why admins are assholes.4 -
Fuuuuck this corporate bullshit. I'm basically sitting around twiddling my thumbs waiting for some jackass to grant me access to the server that my boss moved my code over to. Why the hell did you put my app on a production server that runs every 30 minutes...THAT I DON'T HAVE ACCESS TO?? Now there's a critical bug and a $50K order in limbo because I can't push any fixes. Fuck me. The worst part will be in the next hour or so when dozens of people are calling, emailing, and attacking my cubicle like rabid animals about why orders aren't moving and I'll have to explain that production is a train wreck because reasons. Just end me.2
-
Two years ago I started a small online business. It was not a long term investment and it literally ended up being a one man business. The idea was to provide a service to a small group of people who will benefit from my idea and to offer it to them at a very cheap price. (It being the cheapest helped its popularity a lot).
However, never once did it actually make any profit. (and i never wanted it to make a profit) I wanted it to be self sustaining business and it was.
This was a project for my University by the way, I started off in my first year because of my extensive knowledge in the particular matter, and I only sold to people on campus.
Now that its been 4 years, my batch is graduating, and so there aren't many people to spread the word about this project. It's finally the time to actually say goodbye to this project.
I leased a dedicated server two years ago, and I am finally saying goodbye to that too (can't afford to keep it live anymore). And seriously, it feels sad to shut this machine down haha, I've had so much fun playing around with the configurations (even though it was a production server).
It's clear that this downsizing will continue and I will be closing the service in the near future.4 -
This is the craziest shit... MY FUCKING SERVER JUST SET ON FIRE!!!
Like seriously its hot news (can't resist the puns), it's actually really bad news and I'm just in shock (it's not everyday you find out your running the hottest stack in the country :-P)... I thought it slow as fuck this morning but the office internet was also on the fritz so I carried on with my life until EVERYTHING went down (completely down - poof gone) and within 2 minutes I had a technician from the data centre telling me that something to do with fans had failed and they caught fire, melted and have become one with the hardware. WTF? The last time I went to the data centre it was so cold I pissed sitting down for 2 days because my dick vanished.
I'm just so fucking torn right now because initially I was absolutely fucking ecstatic - 1 week ago after a year of doomsday bitching about having a single point of failure and me not being a sysadmin only to have them look at me like I'm some kind of techie flat earther I finally got approval to spend around 5x more per month and migrate all our software to containerized micro services.
I'll admit this is a bit worse than I expected but thanks to last week at least I have recent off site images of the drives - because big surprise I have to set this monolithic beast back up (No small feat - its gonna be a long night) on a fresh VPS, I also have to do it on premises or the data will only finish uploading sometime next week.
Pro Tip: If your also pleading for more resources/better production environment only to be stone walled the second you mention there's a cost attached be like me - I gave them an ultimatum, either I deploy the software on a stack that's manageable or they man the fuck up and pay a sys admin (This idea got them really amped up until they checked how much decent sys admins cost).
Now I have very flexible pockets because even if I go rambo the max server costs would only be 15-20% of a sys admins paycheck even though that is 13 x more than our current costs.
-
Not much of a story but about 2 years ago, I had just got to the mall (at its opening time so many shops were still closed). While walking through to find a place to eat while my mother went grocery shopping, my phone started buzzing. Upon checking; it had hundreds of notifications and emails. Our production server was malfunctioning.
Not much that I had to do, but I ran around to find a computer store to use their model computers to see what was happening.
However, while the problem was fixed, I did notice how friendly Mac stores were as opposed to windows dealers that day. Windows dealers did not allow me to use the computers while the Mac store connected me to wifi and allowed me all the time needed to fix my issue. 👀 -
Once upon a time, received a call whose intro was "I have a new production machine and I want to set up the Exchange server."
Person wanted to set up Outlook on a new personal computer.
Terminology can be dangerous.2 -
When you look at some production code that has been released for 4 years and find a HUGE security, like catastrophic here is my server hack me flaw 😁4
-
Today I build a queue to spread the load of the 300.000 daily caculations. To prevent slow server response time from to many analist calculating at the same time.
First run on the server I managed to get the server load to 120% and get us offline for 30 minutes.
Accepation environment and production are on the same hardware.
Today was not a good day.4 -
The moment I switched to root user in the production server my hand was just itching to type rm -rf.
Must resist the urge!4 -
Since we are using the same password on all our servers (both QA and Production environment) my team somehow decided that it would be easier to copy the private SSH key for to ALL servers and add the public key to the authorized.keys file.
This way we SSH without password and easily add it to new servers, it also means that anyone who gets into one server can get to all of them.
I wasn't a fan of the same password on all servers, but this private key copying is just going against basic security principles.
Do they want rogue connections? Because that's how you get them.1 -
Please don't create a test server that doesn't have the same data with the production server, and vice versa.2
-
Ran a script on production to scrape ~1000 sites continously and update our ~50.000 productions from the data. On the same server as our site was running. Needless to say, with traffic and scraping, our server had almost 100% CPU and ram usage all the time for 2 weeks until I realised my fuckup2
-
There goes a week of work. I accidentally overwrote my Node server, in production, with a client script, without backups.5
-
...He hired a shit dev who did the same work in 3 times less than what I asked for.
He's now back crying to fix his Fuck up.
You ask how I know he is shit. He SSH-ed into the server. Worked directly off the production files. Worst of all, he installed phpmyadmin, changed the db structure without even writing a fucking migration !!!
How the hell am I supposed to know what he changed!! It's gonna be a long night 😥5 -
Working on photo contest site, no design, no specification. 2 weeks until deadline.
CEO: Deadline is one week earlier, and client wants to have video uploads and automatic facebook share too.
Me: We don't even have a contract and design to work with yet.
CEO: No worries, the contract will be signed by the time you finished the website.
Site done in 1 week, including weekend days and overtime. Production on client's server as asked by CEO.
3 weeks later...
Me: So van you pay the overtime I worked?
CEO: Sorry client not payed and says they don't like the end product. I can't afford to pay you overtime.
2 days later.
CEO: The online department is lossy so you have to work harder in the next month, we have 3 sites to be done.
Me: Do we have the contracts?
CEO: No worries...4 -
rant & question
Last year I had to collaborate to a project written by an old man; let's call him Bob. Bob started working in the punch cards era, he worked as a sysadmin for ages and now he is being "recycled" as a web developer. He will retire in 2 years.
The boss (that is not a programmer) loves Bob and trusts him on everything he says.
Here my problems with Bob and his code:
- he refuses learning git (or any other kind of version control system);
- he knows only procedural PHP (not OO);
- he mixes the presentation layer with business logic;
- he writes layout using tables;
- he uses deprecated HTML tags;
- he uses a random indentation;
- most of the code is vulnerable to SQL injection;
- and, of course, there are no tests.
- Ah, yes, he develops directly on the server, through a SSH connection, using vi without syntax highlighting.
In the beginning I tried to be nice, pointing out just the vulnerabilities and insisting on using git, but he ignored all my suggestions.
So, since I would have managed the production server, I decided to cheat: I completely rewrote the whole application, keeping the same UI, and I said the boss that I created a little fork in order to adapt the code to our infrastructure. He doesn't imagine that the 95% of the code is completely different from the original.
Now it's time to do some changes and another colleague is helping. She noticed what I did and said that I've been disrespectful in throwing away the old man clusterfuck, because in any case the code was working. Moreover he will retire in 2 years and I shouldn't force him to learn new things [tbh, he missed at least last 15 years of web development].
What would you have done in my place?10 -
The WTF moment when I realized that the main production DB server was configured with **dynamic** private IP. After maintenance upgrade and reboot the rest of environment stopped. When I explained to sys admin what caused the production breakdown hi still did not get that :/3
-
Finally, I can play around with a proper server.
HP ProLiant DL380 G6 = dual 8-core Xenons @ 2.4GHz with 32GB RAM and 12TB / RAID1-0 of WD Purples (we happened to have them for some reason).
Already pissed at HP because they don't support JBOD and already pissed at myself for using CentOS, but other than that, enjoying the hell out of it!
And it's ALL MINE! ... Well, technically it's the org's, but it won't go into production for half a year and I'm the only one with the root access so, for now, it's MINE! 😅 13
13 -
Difficult tasks, dog is sick, S.O. suffering from depression, sleep deprived, and now I accidentally type "rm -r / ./" instead of "rm -r ./" on the production server. Whyyyyy12
-
I work on a warehouse dev team. One day this past year, I was trying to deploy a new build to a QA server. Earlier that day I had been looking at the logs on the production server and had left the ssh session open. I had been working for less than a year out of college at this point and shouldn't have had access to deploy to the production server.
Long story short I deployed my QA build to the production server and saw there were problems connection to our production database. Then my heart dropped in my chest as I realized I had just brought down our production server.
I managed to get the server back up by rolling back in about 5 minutes and no one ever knew except some people on my team.
I felt horrible for the longest time. Later in the year another guy that joined my team that has about 20 years of experience under his belt did the exact same thing, but needed help rolling it back. Needless to say, that made me feel a lot better. 😂
Definitely the worst moment of my year.3 -
Do I want to continue?
Y -> vacation lost (Production server is down).
N -> Ok, I will gather more packages for you to update next time.
😭😭 3
3 -
Who doesn't already deleted a DB from production server because tought that is deleting it from localhost's Phpmyadmin? Yeah, shit happens...
.
.
.
It seems less shitty when you have a backup of it from last 9mins, but sucks as well...5 -
Sometimes your music app knows just the right song to play.
Story:
Production program was working (has been for a long time). But suddenly it starts failing. I spent a long ass time trying to see what went wrong.
Problem:
Security update on the server 🙃
Now I've got the client, his minions, and the users emailing me to fix this. But I didn't start this fire!
Song: We didn't start the fire, by Billy Joel -
Creates PHP scripts for development SQL server, pushes to production to find out the schemas are different. *face palm*1
-
Some Project Manager outsourced a redundant RADIUS setup with MySQL backend. We got 2 copies of a daloradius appliance running on Ubuntu 10.04. Once I saw this, I started to get a bit suspicious and requested to audit the system and database redundancy. With the system in production, and without getting back any documentation, I got into the VMs using the default root password. This was not even the worst part, as I found. One server was using a local MySQL instance, while the other was also using the first one's MySQL instance. When I reported this, I was told to comment clearly any changes to the configuration files, which resulted in commenting the word SHAME above each change.1
-
TL;DR Dear boss, firstly, you always get someone to review anything important done by a fucking intern.
Secondly, you do not give access to your fucking client's production server to an intern.
Thirdly, you don't ask your fucking intern to test the intern's work that has not been reviewed by anyone directly on your client's fucking production server.
Last week, the boss and one of the lead devs (the only guy with some serious knowledge about systems and networking) decided to give me (an intern who barely has any work experience) the task of fixing or finding an alternate solution to allowing their support team access to their client machines. Currently they used a reverse SSH tunnel and an intermediary VH but for some reason, that was very unreliable in terms of availability. I suggested using OpenVPN and explained how it would work. Seemed to be a far better idea and they accepted. After several days of working through documentations and guides and everything, I figured out how OpenVPN works and managed to deploy a TEST server and successfully test remote access using two VMs. On seeing my tests, the boss told me that he wanted to test it on the client network. I agreed. Today he comes to me and he tells me to prepare testing for tomorrow and that the client technician is going to give me access to one of their boxes. And then he adds, "It's a working prod server. We'll see if we can make it work on that" and left. I gaped at him for a while and asked another dev guy in the room if what I heard was right. He confirmed. Turns out, the lead dev and the boss's son (who also works here) had had a huge argument since morning on the same issue and finally the dev guy had washed it off his hands and declared that if anything goes wrong from testing it on production, it's entirely the boss's own fault. That's when the boss stepped in and approached me. I ran back to his office and began to explain why prod servers don't top the list of things you can fuck around with. But he simply silenced me saying, "What can go wrong?" and added, "You shouldn't stay still. You should keep moving". Okay, like firstly what the fuck and secondly, what the fuck?.
Even though OpenVPN client is not the scariest thing to install, tomorrow's going to be fun.4 -
fuck this!
spent an hour trying get my website working (on a raspberry) ... no errors, dev tools gave nothing, php gives nothing mySQL related... weird.. debugged my code for an hour when it me... db on my pc for testing is not the same one as the "production" server. i am so fucking stupid... i need some sleep3 -
So I had a problem. MongoDB replica set connection was not accessible to server in another container. I’ve used ChatGPT. Gave it my code. It showed me the things I didn’t know and helped me work out a problem I’ve struggled with for 2 days.
It’s awesome!
ChatGPT is basically StackOverflow 2.0. It’s a tool and a great one. I can’t wait for an actual production level implementation target to software engineers.
P.S. I think co-pilot sucks.1 -
Yesterday I killed a production server with a handful of sites running on it. 😬
Created an observer for one of my Laravel models. It was generating new translated slugs when another post gets translated by an API. While implementing also an updated method besides the created observation I obviously updated the models slug.
Pretty confident this small update will work I just pushed to production. Tested it live.
BOOM
Hard reset on the server redoing the changes. Searching where I fucked up this time...
Finding me observing the updating while updating the updating of the updating by the updating. 🤦4 -
Not mine, but a colleague puts a script in production which has to sent an email every time a config changes, but in reality sent an email every time the file was accessed. The system sent a good amount of email in a couple of minutes, the remote SMTP bounced them but the connections on port 25 was dropped by the server, the production firewall hits the maximum number of allowed connections... a lot of shit!
-
Just got into office and saw a group email about a recently released feature.
Apparently, it creates a lot of connections which it never closes. This could hang the server since it can only handle a large but finite amount of active connections.
Well the dev said: I will optimize later
My thoughts: later = min(never, production blows up) -
Have you ever been interrupted because a marketing workmate had a friend on the phone who needed advice on a WordPress hosting, and wanted your advice right now?
Because I have.
When we had a massive server failure and our production environment was down.
Seriously, what the fuck is wrong with people nowadays.6 -
Accidentally dragged-n-dropped a very important folder into some other folder because of some hiccup when hovering in an Explorer window using remote desktop against our production server. Then left for home. Gotta love GUIs...
-
FUCKING MICROSOFT IIS SHIT.
I'm a .NET dev since 13 years and EVERY FUCKING TIME STUPID IIS MOTHERFUCKER AND STUPID WINDOWS SERVER have a different problem setting up because of some permission.
You can't never get a site up in IIS without loosing time and patience having weird 400/500.x errors because every fucking machine have to set up some tweaky and hidden permissions.
I have 2 identical fucking win servers and deploying a .NET core applications and on one works (test server) and obviously, on the production server it gives troubles.
FUCK YOU MICROSOFT FUCK YOU I would take the IIS devs personally here and whip them to death until they don't resolve the fucking thing3 -
Living on the edge!
One or two years ago I managed to deploy a DDL change directly on the production server. As I knew there was a backup job which will run every day at noon and at midnight. So I run my script some minutes after noon. So far so good. But somehow I tested it badly in my test environment and the UI of the application throws error after error now in production.
Well, just revert the db to the latest recovery point with the backup, I thought.
It became clear then after a couple of minutes of searching the backup folder for the db backup that there was no such file. The youngest backup file was 3 years old.
Now what happened: The backup script had a switch "simulate=true" and then simulated a successful backup on each run. Therefore the monitoring system got no alerts for not correctly executing those jobs correctly. Then the monitoring job which should do the backupfolder surveillance stuck with green, because there was a valid backup file inside. But it did not check for a specific creation date.
Now this database is the one we need for doing our daily business and is really crucial. Therefore It was easier to emergencyfix the application than doing a rollback of the db 🙄
Well, not really a data loss story, but close to one. -
Today marks the day that i finally get to do stuff on a production server.
Its just installing the elasticsearch cluster. But i still feel honored by the trust im given even tho im still an apprentice.6 -
My project manager one time called me while I was waiting in the bank. He told me that the latest changes in the project I was working on were not deployed to production and they were having a meeting to demo those changes to the client later that day.
I had my laptop with me but it wasn't charged. I asked the security guys if I could use the socket used to power up the cleaning/sweeping machines and they didn't mind.
So it was me sitting on the floor in the bank hall using a side socket to power up my laptop holding my cellphone so I can use the hotspot and get internet connection deploying yesterday's changes to a production server.
Eventually, the client didn't attend the meeting that day!4 -
If they followed my suggestion and went straight to debugging the server issues they would have been solved it from week 1 and everyone would have thought the migration had a minor performance hiccup. In fact, we have already done such at least twice before and nobody batted an eye.
Instead they self-labelled the migration a failure on first error, setting the stage for apologizing to the client, and put themselves on the spot for a whole staging / production signoff, replication / backup worfklow, almost a blue-green "seamless" deployment reminiscent of DigitalOcean.
Well they're not DigitalOcean, and anyone who has spent any time understanding users knows they will not participate in "new system" tests long enough to find or report issues.
So of course the migration stretched out to almost three months up until the whole reason for the migration - the rapidly escalating risk of the old provider disappearing - hit like a freight train and now they have to go through the problem of debugging the server like I told them to on week 1. Only this time they've set the client mindset against it, lost any chance of reverting, have had grave risk for data loss, and are under pressure to debug other people's code in real-time.
This is why I don't trust devs to do ops. A dev's first solution to any problem is to throw tech at it.
-
Every time I think I've seen the worst there's someone to prove me wrong...
GRANT ALL ON ALL TABLES/SEQUENCES
To web user on production
if (x == 1) y = 1;
else y = x;
loop through a collection and get 'few' relations using ORM - 1000s of queries and not a single join - but don't worry, "The ITs will just add more RAM and some CPU cores to the server"
4th day off and I already miss this2 -
Going through the conversation for xxxxth time with my business partner, why we will not launch a new product on top of pre-made PHP script / plugin.
Just got our company into TDD, and automated QA via CI server & code checks etc, PLEASE stop trying to drag us back into the land of spaghetti code & bug legions in production. That's all thxbye. -
Client calls me requesting a new simple feature.
Connect to FTP server.
Edit some PHP pages and upload them back, check if the changes actually worked.
Basically implementing and testing a new feature on a live production website...
PS. It didn't work the first or second time -
My biggest mistake was that I didn't check the file extension of a uploaded file. Or more correctly forgot that I turned it off for debugging and pushed the app to production.
Somebody noticed an uploaded a hacker php script and got access to all the files on the server. Including some semi sensetive clients information.
A talk with the client that followed was not a pleasant one4 -
Normally you would have:
- Management
- SysOps
- DevOps
- Devs
In the company (30-50 workers) we only have:
- Management
- SysOps (they don't know how to deploy apps beyond FTP to a webhost either)
- Devs
Jepp, management does not want a specific DevOps department, because he thinks every single "I just finished the Javascript course on codecademy" person knows how to deploy an app beyond dragging&dropping it to a webhost with FTP...
I tried to propose to them that I handle DevOps and teach it to others, so we can deploy code that we deem "production ready" in a more proper manner...
They refused...
They rather stick to "just use FTP to push any changes we made directly to the production server and test changes there"4 -
So management wants this:
As soon as a customer reports a bug, management wants to have an "emergency button" to let their inexperienced hands make production fall back to the last stable version, without having to pass through IT and wait for them to fix it. If the server catches a 500 error, this process should be done automatically. All because they don't want to give us more time writing more thorough tests...9 -
The most crazy issue I've fixed was caused by a TCP behavior which I didn't know, called the "half-closed connection".
There was a third-party application installed on a production server which called a LDAP server for retrieving users information. During the day we had several users using the application and all worked fine. During the night, when the application was not accessed, something happened and the first call to the application in the morning was stuck for about 5 minutes before returning a response. I tried to reproduce the issue in a testing environment without success. Then I discovered that the application and the LDAP server were located on two different networks, with a firewall between them. And firewalls sometimes drop old connections. For this reason network applications usually implement a keep-alive mechanism. Well, the default LDAP Java libraries don't set the keep-alive on their connections. So, I found a library called "libdontdie", which force the keep-alive on the connections. I installed the library on the server, loaded it at the startup and the weird stuck behavior in the morning disappeared.2 -
I was doing some maintenance on a production server for a game hosting company (Minecraft hosting, for those interested). A week before, I had created a backup of an account directory before trying to solve an issue, I now wanted to remove this directory.
Since I am way too confident in my ability to not mess up, I was logged in as root.
Instead of typing `rm -rf ../` (I know using -f is a bad idea), I typed `rm -rf /`.
The distro we were using did not have any protections built in.
The directory I wanted to remove as gone, but so was the rest of the server once I realized what I had done.3 -
Manager tweaks with some data on the production server and accidentally deletes some rows.
*flip table* *rage*2 -
Everytime you tell yourself "This time I'm going to make them stop putting the cart before the horse again!!! No more forced shit implementations!!! NO MORE ! I'm strong!!"
The last hour in the next week:
- Selinux: off
- Firewall: Any-Any
- Application data: Everything installed on OS disc.
- Documentation: At best, someone remembers the server supposed-to-be dns record
- Service Accounts: Your domain admin account and sysadmin for databases.
- Patching: DON'T EVER THINK ABOUT IT..AND NO REBOOTING! I have set very important runtime variables.
- Backup: Maybe someone else will set this up.
- Monitoring: Not needed since clients will create tickets if system fails.
- Production Status: vague at best. Sort of silently transitioned to production.
- Handover status: Probably, but I quit before the project closed.
! -
I'm a fullstack engineer, this period there is literally nothing to do, we are a 1000+ employees company.
I got so bored I toke over the database of our production server two times in a week, exploiting dumb vulnerabilities I discovered out of boredom, of course I reported everything.
The funny thing is that they just don't care, no one took action or is willing to fix it and they actually insulted me because I set a query in sleep for 8 minutes exploiting one of the vulnerabilities.
I work for a great company that hosts (in this very server) most italian citizens informations C: free to take for everyone c:5 -
If you’re a Russian ux engineer who is present in a Russian ux community and you fucking make your form validate on change event and that leads to the situation when a user starts entering their email and your bouba form immediately throws WRONG EMAIL errors, we don’t call you a bouba.
We call you a ебанок (ebanok) — a small, stupid and miserable creature that you can only feel hatred mixed with disgust towards.
This shit is acceptable if you’re an intern making their first shy steps creating their own personal project, but if you push this to production, you’re a ebanok. If you don’t know how to do ux, just use server-side validation or display errors with alerts on submit.
You fucking ebanok.5 -
Writing a feature critical for production in 2 hours of solid focus during the morning.
6 hours later it's still not in the build because:
* tech lead wants the code to move to a partial class instead of an extension method, delaying the UX review. No guidelines for this ever existed.
* after seeing the result, the UX team wants some element to be dynamic. A line. A friggin horizontal line.
* after adding the dynamic shiny frigggggin line, I try to test the feature with the server. It is still not deployed because the server guy went home. "The PR was not merged so I assumed we'll add it tomorrow".
Another day at the meat grinder.6 -
First day back from holiday: after 30 minutes of work (excludes start-up, catch-up etc.) The P.O. (product owner) comes to me
Telling me I needed to switch project, ok I thought at least they switched the project from what ever it was to a propper OTAP street while I was away
Few tickets later the P.O. asked me if tickets x could be deployed to our test servers as well as production.. (note the ticket was already merged with our develop branch and he wanted only that single ticket x to be deployed)
WTF is the point of a OTAP street if you're going to deploy it to every server type at once?
So day one after my holiday I already needed to fight the P.O. again
At least I wasn't disturbed during my vacation... Witch is a first.8 -
New twist on an old favorite.
Background:
- TeamA provides a service internal to the company.
- That service is made accessible to a cloud environment, also has a requirement to be made available to machines on the local network so you can develop against it.
- Company is too cheap/stupid to get a s2s vpn to their cloud provider.
- Company also only hosts production in the cloud, so all other dev is done locally, or on production non-similar infra, local dev is podman.
- They accomplish service connectivity by use of an inordinately complicated edge gateway/router/firewall/message translator/ouija board/julienne fry maker, also controlled by said service team.
Scenario:
Me: "Hey, we're cool with signing requests using an x509 cert. That said, doing so requires different code than connecting to an unsecured endpoint. Please make this service accessible to developer machines and lower environments on the internal network so we can, you know, develop."
TeamA: "The service should be accessible to [cloud ip range]"
Me: "Yes, that's a production range. We need to be able to test the signing code without testing in production"
TeamA: "Can you mock the data?"
Me: "The code we are testing is relating to auth, not business logic"
TeamA: "What are you trying to do?"
Me: "We are trying to test the code that uses the x509 you provide to connect to the service"
TeamA: "Can you deploy to the cloud"
Me: "Again, no, the cloud is only production per policy, all lower environments are in the local data center"
TeamA: "can you try connecting to the gateway?"
Me: "Yes, we have, it's not accessible, it only has public DNS, and only allows [cloud ip range]"
TeamA: "it work when we try it"
Me: "Can you please supply repro steps so we can adjust our process"
TeamA: "Yes, log into the gateway and try issuing the call from there"
Me: (╯°□°)╯︵ ┻━┻
tl;dr: Works on my server -
Our IT team keeping our PET Production server alive by resizing partitions on the fly.
#living-on-the-edge
#caveman-practices
-
Was just reading some of the OpenVPN scripts to renew a certificate where I forgot to source the vars file first (apparently OpenVPN stores those in a separate file that you always have to source first, and I tend to forget it sometimes).
Reading the revoke-full script that OpenVPN provides, it's just bash so I can read it no problem. But traversing through it and trying to understand it... Horrible! There's a test file in $RT named keys/revoke-test.pem. It's not used anywhere in OpenVPN for anything useful as far as I'm aware. The script however - the script that's running on a production server! - attempts to remove this file. It doesn't exist. Test files do (or at least should) not exist in production. They're not supposed to be there.
It exports empty variables. Some of them are set by the sourced vars file, some aren't. Not entirely sure why it's exporting variables as empty when they're uninitialized, or why it doesn't just unset the ones that are initialized.
And finally it goes ahead and revokes the key file that I'm actually concerned about through regular OpenSSL and verifies it.
Not to mention that the lack of the sourced vars file, which admittedly I should think about in the current status quo, if it *always* needs to be sourced anyway... Why doesn't the script do that itself then? One less thing to go wrong. But hey, proper design?
Gore. I don't have any other words for it.
And before anyone tells me that I should go and fix it if I'm so worried about it. Remember, I am not a developer. That's the job of the developers that made this in the first place.6 -
When you catch developers rolling out untested changes to production that have a huge impact on your clients workflow... And they don't tell anyone so you find out because your clients are yelling on the phone about some change affecting their work flow.

-
Some birds told me Galaxy S9 is really good.
Googled it, and found something more interesting.
PS: this is the 3rd largest mobile server provider in NZ
Use development code in production.
Distructed certificate.
Nice work guys! 2
2 -
Well... Just last week one guy somehow completely broken our production server while creating an WordPress using Ghostscript for some reason. First this CMS users 100% CPU, then something has happened and whole server couldn't get up. Admin had to restore it from a backup. There are around 7 client on this server and all of our projects.1
-
So glad to be staying a new job next week. Today a junior colleague asked me what the best way to test something would be as it won't work locally. Knowing this has a good chance of taking down the server, I suggest he sounds up a server on his AWS account. My manager comes in, oh no I don't want him doing it on AWS use the production server instead. By the time stuff States hitting the fan I will be gone.1
-
MySQL is freaking and keeps restarting :(
Production server "Error establishing database connection"
FUCKKKKKKKKKKKKKKKK2 -
We called a customer because that on their server a directory is missing which was important for production.
Turned out that they didn't miss a directory because they worked in the development environment of the same customer but in a different location. For the last 3 months. -
Wow or wtf to these banks API. was integrating an API for a service which accept JSON input.
Okay fair enough, that would be fine
Spent an hour writing code(purescript) most of time spent was on writing Types based on the API doc. after that okay let me test the API it failed.
I was what happened? So tested the API from postman with the payload from the doc, it worked. What how?
used a JSON diff to compare the payload from postman and the log. Looked same to me after spending few hours checking what is wrong with it .trying changing value to pasting the body of the log request in postman and trying everything failed.
Later went to the original working payload provided by them and changing the order. It started throwing error. I was like wait what?
It must be only on there UAT. created a payload with production creds and hoping to our production server (they have IP whitelist) ran the curl with proper payload as expected it worked. Later for same payload changed the order or one key and tried it failed.
Just why????
I don't want to create a JSON with keys on specific order. Also it's not even sorted order.4 -
Don't need Netflix when you have a production deployment right before a long weekend. It has failed since last two weeks due to vulnerabilities present in one of libraries(P.S. FUCK JAVASCRIPT and Post release vulnerability scans!). You have rewritten the whole functionality from scratch twice! Security gates finally open for you, welcoming with arms wide open. So you click Deploy! DAFUQ!! FUCK MY LIFE! Deployment failed! It's only a 3 hour window to deploy! You frantically re-review your code, is it me?? Not again!! It isn't! Well, why is the deployment failing, you work against the clock. Going through configs, code, documentation! WTF is it?? Should I give up and raise a support ticket? Nope! You login to the server, sifting through logs and configs, there's a couple of other tickets with today's deadline. What are you going to do? And you get a hint! You take the hunch, change the config 5 minutes before deadline!
Get merge request approved, wait for the build, hit DEPLOY!! Nail biting 3 minutes! Your eyes fixed on the logs! Building..... Pushing instances..... Starting App..... SUCCESS!!! Finish the remaining tickets! Your long weekend still exists!3 -
One of those mysterious bugs that only happens on production. Want to solve it on your laptop, it's not reproducible. Staging server? Nope. Production?
HOW DARE YOU TOUCH THE LIVE SYSTEM?!?1 -
Yesterday was a horrible day...
First of all, as we are short of few devs, I was assigned production bugs... Few applications from mobile app were getting fucked up. All fields in db were empty, no customer name, email, mobile number, etc.
I started investigating, took dump from db, analyzed the created_at time stamps. Installed app, tried to reproduce bug, everything worked. Tried API calls from postman, again worked. There were no error emails too.
So I asked for server access logs, devops took 4 hrs just to give me the log. Went through 4 million lines and found 500 errors on mobile apis. Went to the file, no error handling in place.
So I have a bug to fix which occurs 1 in 100 case, no stack trace, no idea what is failing. Fuck my job. -
God damnit!!
Just got a team assigned for the course I follow and the codebase they work looks like someone shit on the floor and dragged it all over place. No consistency, no clear structure.
The project has to be built in PHP (which is fine by the way) following the principles of MVC. Did I say the codebase looks like shit all over the place? Well that's exactly what it is!!
They use $_SERVER['DOCUMENT_ROOT'] everywhere!! In every fucking file!! Why the FUCK would someone possibly want to do that??
I know I'm not perfect, but what the fuck!!
Now comes the most weird thing. They have to work on a remote server without SSH access, so working with FTP is mandatory. This is because the school won't setup ssh. That's fine by me, but because of that they don't use git!! They upload files directly to the production server. They merge everything manually. I asked why they didn't use git and the answer was so fucking SHIT!! "Because the teacher wants to see who uploaded to the server.."
First off all: what happened to git blame? Second: Later I heard that there is only one FTP account, so all the things they said where just bullshit!!
The fuck.
Tomorrow I'm going to try and convince them to use git..1 -
I started fully exploring different aspects of tech in a middle school technology class where the teacher gave me a good grade as long as I did something that could be useful or interesting. I learned how to design webpages by playing with inspect element, and then decided to make my own with Notepad. One of my friends showed me how to use Sublime Text, and I found that I loved programming. Other things I did in there included using two desktops with NIC's wired directly to each other with an old version of Synergy and a VNC server, and at one point, I built a server node out of old dell Optiplex desktops the school had piled in a storage room.
Last year in high school, I took a class on VB.net and made some money afterwards by freelance refreshing legacy spaghetti, and got burned pretty badly by a person offering $25,000 for a major POS to backend CMS integration rewrite. The person told me that I had finished second, and that another dev had gotten the reward, but that he liked my code. A few days later, I was notified through a *cough*very convoluted*cough* system of mine by a trigger that ran once during startup in a production environment and reported the version number as well as a few other bits, and I was able to see that *cough*someone*cough* had been using my code. I stopped programming for at least six months straight because I didn't want to go back.
This year in high school, I'm taking the engineering class I didn't get into last year, and I realized that Autodesk Inventor supports VBA. I got back into programming with a lot of copy-paste and click-once "installers" to get my modelling assignments done faster than my classmates. Last week, one of my friends asked me to help him fix his VB program, which I did, and now I'm hooked again.
I've always been an engineer at heart, but now I'm conflicted with going into I.T., mechanical or robotical engineering, or being a software developer.
A little long, but that's how I got to where I am now. (I still detest those who take advantage of defenseless programmers. There's a special place for them.)7 -
when a dev fixes a memory leek issue but rebooting the server, and when ask why the production application crashes he casualty replies "I don't know but I restarted the server and its fine now..."7
-
I have a web app that is currently running on a production server with no issues, but at the same time, it isn't working on my machine which I used to write, test, and deploy the app. The thing is, I haven't touched the code for a full month.
Now, I know this has to be logical and that there must be an reasonable explanation for all of this that I do not know yet.
However, and out of frustration, my mind wants to believe that there's some sorcery involved here or that a cosmic ray has actually penetrated the machine and messed its registers.
Damn the cosmic ray!3 -
When your staging/test server dies just as the boss wants a big update completed. Straight to production it is!
-
So, we are having a SaaS service for people where they can build X stuff. It is all fine as long as you are using basic things there, no complex cases and so on. Even on some complex - it does work just fine.
Here's the rant itself:
The production server throws us errors every 5-10 minutes that something broke and fails to do job X. At first we were all hands on deck fixing it ASAP to make it stable to later realise that most of these cases were users doing stupid shit. Then we began to fix the core issues rather than chasing every single issue there is (costs are important you know) - funny enough, we get few support requests a week and our 1h response time + 24h fix time usually buys us that customer and allows t o leave a great impression.
So all in all, bugles production is good but great support - is way better. Users can deal with issues especially if they are experimenting there but when they need answers - you'd better give it to them.1 -
TL;DR The "senior dev", that the client hired on their end, is acting as a middleman between me and the project requestors. Taking the credit for my work.
I've already bitch about this before. I've been in a crusade to defend the production server from this fraud for a long time now.
But most recently he has removed me from all meetings with the actual project owner. I create the solutions, then he goes through them to understand it a bit. He proceeds to present it to the project owner in a way that almost blatantly says that he made it.
I'm sick and tired of working with this asshole. He is literally useless, worse he is slowing things down and breaking others.
I'm just gonna begin countering this... -
So I'm currently "assigned" a task in which I need to fix a slow query problem, which isn't a big deal. The biggest problem is that the original team of this project haven't got any means to develop things on your local machine. Looking at their docs and scripts, it seems like everything is deployed to a dev server. But whilst looking for details for this server, I found out that the network team have decommissioned the server!
So my dilemma right now is that I can't test any of my fixes on anywhere besides staging, or possibly production! Inheriting projects is the bloody worst!5 -
It was in old days when I was working in java and windows systems.
Java and different log4j versions across dependencies caused system not working only on production server.
Turned out some of libraries got log4j embedded and conflicted with other log4j.
It worked in all computers except production one.
Actually that was my main reason to switch my career to python after that dependency hell.
Another one was windows server 2008 tcp connection limit set to 200 or something.
We needed to change registry to get our servers working. After this case we finally managed to convince people to switch to linux.
Anyway any non standard error when you got multiple layers communicate with each other is hard, practice make it easier to solve those problems as your success moment comes faster.4 -
Let's see what's on the menu today:
* Web Application Catastrophe Special *
Includes, but not limited to:
- Orphaned server processes in the configuration management cluster
- Microservice back-end architecture with no API documentation
- Poorly implemented cache microservice with no documentation
- Stale data causing everything to be shown as down in production, despite everything running fine
Cost: 1 developer's sanity -
That feeling when you have already fixed the problem on production server on Thursday and got the approval from the client but the same issue appears again on Friday evening.
#WeekendSpoiled 5
5 -
My mate just pen-testing on running production server using admin credential.
Guess what happen!
And no backup!
What a day!2 -
Developed an update to our database procedures and tested it with local copy. After a few days everything was ready. Opened our server and started the update. After a couple of rows an error occurred. Turns out our production db is older version and does not support some syntax I used. It became a bit longer day at work...
-
That moment when you build your app around a clients development API only to find out their production API responds about 8x slower... I'm sorry, it's not my fault your API server takes 4000 ms for a SIMPLE response. My app isn't the problem. Fix your shit.1
-
Does anyone of you fellow devs ever pushes to production during working hours?
I have the luxury to do so and at first was uncomfortable, as this of course takes the system offline for a few seconds, and next web requests from a user are painful due to cold start of web server (and we have 40-100 active users at any given time)...
...but you know what? They all complain SharePoint is slow (it is) anyway, so. I do it.
Sometimes it fucking fails, so I do have all of the historic deployments handy, ready to revert. :)10 -
Production goes down because there's a memory leak due to scale.
When you say it in one sentence, it sounds too easy. Being developers we know how it all goes. It starts with an alert ping, then one server instance goes down, then the next. First you start debugging from your code, then the application servers, then the web servers and by that time, you're already on the tips of your toes. Then you realize that the application and application servers have been gradually losing memory over a period of time. If the application is one that don't get re-deployed ever so often, the complexity grows faster. No anomaly / change detection monitor can detect a gradual decrease of memory over a period of months.2 -
Deploy Updates in the production Server, when:
- it's Friday
- after lunch
- 2 hours before closing time
- the next 5 days are Holidays
-
This is why code reviews are important.
Instead of loading a relevant dataset from the database once, the developer was querying the database for every field, every time the method interacted with it.
What should have been one call for 200k records ended up as 50+ calls for 200k records for every one of 300+ users.
The whole production application server was locked.2 -
Alright so I've been thinking of taking my skills to the next level and would like to know a few things from PRO C++ DEV out there
1. Is it possible to set up a production level web server with c++, if so why don't i see many and why are there so many with nodejs etc..
2. Client side web pages without Javascript, possible?
3. Well I forgot the other questions I wanted to ask, if I do remember you'd be able to find them in the comments
I believe in a single universal language for coding, hence I place forth such questions9 -
Who the hell hardcodes their localhost ports in a web.config without updating the release config to the correct production URLs? And why doesn't our ops team pick up on this shit before clicking their fancy deploy button? And why in holy heaven do we even have a pre-production server if it isn't an exact mirror of production?
God help me, I need a drink. -
Our client wants us to deploy all changes to the test server & to the production server at the same time (-___-)
So all bugs which have been founded after that should be hotfixed ASAP :/2 -
Waiting for the day when i deploy my app to the production server and everything runs as expected.
 1
1 -
Finally made my node production server stable enough that I could focus on writing tests*. I start by setting up docker, mocking cognito, preparing the database and everything. Reading up on Node test suites and following a short tut to set up my first unit test. Didn't go smoothly, but it's local and there are no deadlines so who cares. 4 days later, first assert.equal(1+1, 2) passes and I'm happy.
I start writing all sorts of tests, installing everything required into "devDependancies," and getting the joy of having some tests pass on first try with all asserts set up, feels good!
I decide to make a small update to production, so I add a test, run and see it fail, implement the feature, re-run and, it passes!
I push the feature to develop, test it, and it works as intended. Merge that to master and subsequently to one of my ec2 production servers**, and lo and behold, production server is on a bootloop claiming it "Cannot find module `graphql`". But how? I didn't change any production dependencies, and my package lock json is committed so wth?
I google the issue, but can't find anything relevant. The only thing that I could guess was that some dependencies (including graphql) were referenced*** in both, prod and dev, and were omitted when installed on a prod NODE_ENV, but googling that specific issue yielded no results, and I would have thought npm would be clever enough to see that and would always install those dependencies (spoiler: it didn't for me).
With reduced production capacity (having one server down) I decided to npm uninstall all dev dependencies anyway and see what happens. Aaaaand it works.....
So now I have a working production server, but broken local tests, and I'm not sure why npm is behaving like this...
* Yes I see the irony.
** No staging because $$$, also this is a personal project.
*** I am not directly referencing the same thing twice, it's probably a subdependency somewhere.2 -
I just love starting my mornings with telling someone at another company not to chmod 777 their ftp root because mutual customers are yelling at me because the other company’s shit is broke. This is a production server with thousands of accounts.1
-
Switching from Linux to Windows on my personal production server... because sometimes logging into RDP is so much easier than SSH.3
-
How do you guys push changes to you server. ?
I am currently pushing changes to my git repo then pulling those changes on server where I am running the application in production.
I am planning to set up a simple server, to which I will push the changes and it push the changes to the server's running in production.
Or better would be to write a script and run on production servers that will check github for changes3 -
4th week of internship begins and today, for the first time, features that I programmed got deployed to the production server !
I'm proud of myself and I really enjoy working there !
It's challenging and at the same time really cool.8 -
A developer couldn't get a application performance monitoring (APM) tool to trace his application. They claimed that their libraries and their configurations were alright and that the APM tool was non-performant.
The developer then argues with sysadmin that the APM tool can't trace the application and that there's nothing wrong with the application or the configurations. When sysadmin questions whether the developer got the tool to work anywhere, they say, "No" and head off to make it work at least in one place. They come back saying that it works on their development environment (which is their local machine). Sysadmin claims that the system configurations on the server instances cannot be matched by the development environment and there could be a lot more factors to be considered for the problem. The sysadmin asks to prove it on a server instance on one of the test environments and then they'd agree that it is a problem with the tool. They also argue that this is not the only application that uses the APM tool and the tool happily traces other applications with no issues.
The developer tries the same configuration on a staging instance and fails. In order to make it work, they silently uninstall the existing version of the APM tool and then compiles an unstable branch of the tool. It finally works with this version.
They go back to the sysadmin and show that it works on the staging environment, but does not on production. After banging their head on the wall for a while, the sysadmin figure that the tool had been swapped out for the unstable branch that was manually compiled. When questioned, the developer responds, "It works with this version on staging, so deploy the same version on production"
WTF? You don't deploy an unstable branch to production. Just because you can't make it work on the stable branch doesn't mean that it is the problem with the tool itself. There's a big difference between a stable branch and a non-stable branch. How would you feel if the sysadmin retorted by asking you to deploy the staging branch of your application to production? -
How fucked up are you,
when your vp of engineering doesn't even know how to show phpinfo webpage to test server setup.
and..
change ode directly in production server,
then messed up and using excuse :
" I don't know because i am a frontend developer "
Then why you become a VP of Engineer !3 -
When your IT VP starts speaking blasphemy:
"Team,
We all know what’s going on with the API. Next week we may see 6x order volumes.
We need to do everything possible to minimize the load on our prod database server.
Here are some guidelines we’re implementing immediately:
· I’m revoking most direct production SQL access. (even read only). You should be running analysis queries and data pulls out of the replication server anyway.
· No User Management activities are allowed between 9AM and 9PM EST. If you’re going to run a large amount of updates, please coordinate with a DBA to have someone monitoring.
· No checklist setup/maintenance activities are allowed at all. If this causes business impact please let me know.
· If you see are doing anything in [App Name] that’s running long, kill it and get a DBA involved.
Please keep the communication level high and stay vigilant in protecting our prod environment!"
RIP most of what I do at work.3 -
Hotswapping/replacing classes on the production server
We call it "russian deployment" .. No offense -
I'm starting to FUCKing hate those 1-5 lines minified 3rdparty javascript snippets that everyone seems to be bombarding their website with.
Why on gods ungodly earth would you ever dream of injecting this kind of style into my <head> tag.
Without any warning whatsoever.
You couldn't be FUCKing bothered to be thinking about the consequences, before pushing such an update to your production server.
That's how you leave your users website broken, or ugly af.
I know it's an easy fix, simply remove the snippet that injects this crap, if only I was allowed to say "no don't keep this FUCKing crap" to the customer. 2
2 -
Posted in DevOps discussion board (teams channel):
“Program x isn’t behaving the same way that it does on production. Can you please take a look?”
..a little background: we have a deployment scheduled for today and this issue was found during regression testing.
The issue found is that when a file is clicked on it disappears from the screen, and then isn’t opened…
The file is not on prem, and doesn’t get uploaded to a server that our DevOps team owns…
So why on earth would this development team be asking DevOps to look into a bug that is most likely a code related issue? 😆
Is this a common occurrence for anyone else?
A Bug is found, and the first thought is that the code isn’t the issue?11 -
After three months of development, my first contribution to the client is going live on their servers in less than 12 hours. And let me say, I shall never again be doing that much programming in one go, because the last week and a half has been a nightmare... Where to begin...
So last Monday, my code passed to our testing servers, for QA to review and give its seal of approval. But the server was acting up and wouldn't let us do much, giving us tons of timeouts and other errors, so we reported it to the sysadmin and had to put off the testing.
Now that's all fine and dandy, but last Wednesday we had to prepare the release for 4 days of regression testing on our staging servers, which meant that by Wednesday night the code had to be greenlight by QA. Tuesday the sysadmin was unable to check the problem on our testing servers, so we had to wait to Wednesday.
Wednesday comes along, I'm patching a couple things I saw, and around lunch time we deploy to the testing servers. I launch our fancy new Postman tests which pass in local, and I get a bunch of errors. Partially my codes fault, partially the testing env manipulating server responses and systems failing.
Fifteen minutes before I leave work on the day we have to leave everything ready to pass to staging, I find another bug, which is not really something I can ignore. My typing skills go to work as I'm hammering line after line of code out, trying to get it finished so we can deploy and test when I get home. Done just in time to catch the bus home...
So I get home. Run the tests. Still a couple failures due to the bug I tried to resolve. We ask for an extension till the following morning, thus delaying our deployment to staging. Eight hours later, at 1AM, after working a full 8 hours before, I push my code and leave it ready for deployment the following morning. Finally, everything works and we can get our code up to staging. Tests had to be modified to accommodate the shitty testing environment, but I'm happy that we're finally done there.
Staging server shits itself for half a day, so we end up doing regression tests a full day late, without a change in date for our upload to production (yay...).
We get to staging, I run my tests, all green, all working, so happy. I keep on working on other stuff, and the day that we were slated to upload to production, my coworkers find that throughout the development (which included a huge migration), code was removed which should not have. Team panics. Everyone is reviewing my commits (over a hundred commits) trying to see what we're missing that is required (especially legal requirements). Upload to production is delayed one day because of this. Ended up being one class missing, and a couple lines of code, which is my bad (but seriously, not bad considering I'm a Junior who was handed this project as his first task at his first job).
I swear to God, from here on out, one feature per branch and merge request. Never again shall I let this happen. I don't even know why it was allowed to happen, it breaks our branch policies. But ohel... I will now personally oppose crap like this too...
Now if you'll excuse me... I'm going to be highly unproductive and rest, because I might start balding otherwise after these weeks... -
Some idiot fixing bugs in production and overwriting files without updating his git repo when I pushed another bugfix live.
Boss to me: "it's your job to get the fix live!"
I FUCKING HATE MONDAYS!
screw performance i'm gonna run gulp.watch in production and just git reset it to last release when someone fiddles with files on the server :( -
So basically a friend was tasked with doing some syadmin on a propietary system running on top of GNU/Linux (they distribute the software as a distro).
Called me about an hour ago because there was some odd stuff happening so I log into the system and start figuring out what the actual fuck is up.
Just now we discovered that for a certain critical feature you just need to trust that there will be no eavesdroppers, meaning you send system credentials in cleartext over the network, and it won't work if it's not so.
Of course, some tunnels and routing later (which by the way, is "manual" configuration which is highly discouraged by the creators of this piece of crap) we kind of managed to overcome this obvious fail.
Now then, can you please explain me again how is it that these companies grab open source, make useless layers that limit it in every way possible and still profit? I mean, for fucks sake, you should at least let people manage shit with standard, well understood tools instead of "improving system administration", "easing it for...", for whom?
I'm so happy to log into our production server and be welcomed by beastie. -
docker is shit. It fills up the disk on its own whim and then crashes the server, and they claim it to be production ready. Stupid piece of software!4
-
Confession: a very important feature of the website I'm developping wasn't working for a certain time. The boss wasn't aware because he doesn't go on the site, and I only found out last week because I needed to implement a new feature that used the previous one. Problem: the bug was only on production, not on local (and of course we don't have test server).
I took advantage of the absence of my boss today to clear the situation by making all of my tests on prod. I hope no customer tried to pass a command today, but it's finally repaired. I am both proud and shameful.3 -
Fire every single teacher who runs from self education. Someone who keeps themselves up to date should be keeping students up to date.
Secondly, assign each class a major project which starts from 4th semester with one of the faculty acting as the Project Manager. Allow each student to choose their area of interest and work on that module. This will help develop team work and teach how not to rm rf production server or db:drop production database ^.^ -
You should write comments in your code, and in case of Perl you must write comments in your code.
I've done some DNS zone editing stuff using Perl's magic around 4 years ago and now I have no fucking idea what's going on in there. It's on production DNS server since then, no problems so far... -
So, someone from support department asked me to check the app as it was displaying blank information on a page.
I started debugging on the api which i found is doing the proboem. I checked and it was working a moment before but not now. Switched in debug mode to see what went wrong and it works again. This happen multiple times.
Before doing anything else i asked our api developer to check if api is working. He said it should work now and problem has been fixed.
Later i found out that he was doing debugging/changing code on production server instead of his local machine or test server. -
I looked at an SQL server today from a customer, talked with one of their devs and he said that he's unable to understand why the server misbehaves... All (!) queries were optimized, but they have 'big data queries'... Migraine started, I had a very bad feeling. Monitoring? Nooooppeeee. Migraine kicks in. Connected to server. SHOW GLOBAL VARIABLES...
After a bit of scrolling I found a lot of misconfigured variables (e.g. extreme large join buffers, unrealistic buffer sizes), high slow query count (nearly 60 % of COM_SELECT) and a few variables that were unknown to me.
Then came the version line.
5.0.46
Yes. 5.0.46.
Big data? Well... 30 GB of usage data.
I called the company back... The dev told me sternly that this was the production server (I had hope...) and that I lie - neither the version, nor the variables could be the problem.
A coworker had to verify it and our manager had to do the communication... Worst, most traumatic working day I ever had. -
What's your workspace setup?
Curious because it took awhile and a lot of experimenting/thinking to get mine setup the way it is, but now I can't even think properly unless I have things setup that way after booting up in the morning.
Here goes:
Workspace 1: General stuff, personal email. social media, random research for non work related things, etc
Workspace 2: My main project local development, includes terminals, database, browser research for bugs, debugging software, error logs, etc.
Workspace 3: My main project, production workspace, consoles, browser, etc related to production server, you get the idea
Workspace 4: local dev on my side project
I found it crucial to setup workspace 2 and 3, it has helped me avoid countless stupid errors, like, for example, accidentally working on production terminal and wanting to rip my hair out wondering why the fuck _____ isn't working, then realizing, oh shit, i'm on production, not local. Huge brainspace bandwidth saver when I setup like this.
How about you?2 -
Weekend thought: What counts as stable in development?
From my experience it seems that "stable" is a relative concept. My linux server is "stable" in the sense that the packages are tested for a long period of time before release, but my home distro is a rolling release and that is also stable in my opinion. So which is it? Can it be both? Or maybe we're just lying to ourselves that anything is stable.
When I'm developing web applications I always have this rule that is the user can't enter and exit the application without a major error coming out, it isn't ready for production. Once that's out of the way, from my point of view the application is stable. But if I were to present this to a company would they think the same? Probably not.
What do you think counts as a stable production release?1 -
Before get get source code for freelance job, the person who cantact me say the job is to continue the project for some update and tweak.
The UI from design is beautiful and he gave good explaination for the project and the update, continue to conversarion, negosiation and deal.
but he is not the IT guy and also the project is not his work or something that he do previosly. All the person who work on that project is already leave and not contactable.
And here that I get:
- source code
- domain cred.
And here what's missing:
- documentation
- .env file
- db backup / old db cred.
- server and hosting cred.
And after some hour of learning the code I find out that:
- latest commit was 2 year ago and different from production version.
- most of the branch is RnD.
- the code have many wtf/minute lol
And for now I still re-negotiate with the person who give me the project with 2 suggestion from me.
- continue with this code with condition, he need to search for the missing part at least backup db or documentation.
- recreate the project with more time
And here's one funny part of the code.
randomNumber(){
return 5 // this number was choose by dev team at random
}1 -
Change of technology. There's one time that the team can't decide what tech to use. So after 2 years of production suddenly we moved from Nodejs to Elixir for server side and MySql to Cassandra for database ... It is crazy that time...
So learning a new language it was so difficult as elixir is functional ... (And I was sucks back then) , and Cassandra is something new to me , which is difficult.
(Hey bit now it is ok ) -
Risk is part of my everyday life.
I take the risk everyday when opening IDE and changing line of code that can either break database or crash other systems that are depending on one I am developing. ( not instantly but in some time in the future )
So....
Many years ago I was updating some application server production code while being drunk.
Everything went fine except me waking up in the morning and didn’t remember how I did it.
... what I learned from my developers life except that heavy drinking and updating servers is not the best idea ?
First, don’t give a fuck, do your job and ask questions even if the person in front of you said that understood everything and you think you understood all of shit.
Second, if you think you know what to do think twice.
Third, having any backup, any tests and any documentation is always better then having nothing.
And the most important.
The most risky in every business are people around you, so always have good people around and there would be no risk at all or you won’t even think about it.
✌🏽 ❤️ -
TL;DR: idiot 'team leader' does mindless merge to master. Precious time wasted in a high pressure deadline environment.
So, i work currently at one of Belgiums largest consulting company's at brussels airport, we are moving their analytics platform to the cloud.
We use puppet to manage the systems.
When i started i noticed immediately that their 'development workflow' is hardly to be named as such, because they simply change stuff directly on server , manual 'temporary' fixes everywhere, hardcoded stuff, non validated code... Basically the way one would develop in their garage, not in a consulting company as this one. But that is just the beginning.
A month ago i did a major effort to equalize all the discrepancies between the codebase and the server. Ensured entire codebase to be validated, syntax checked, parsed, tested... It works. A 'great codebase overhaul' commit was PR'ed to master and got merged.
Yesterday the team lead, i'll call him 'B-tard' from here on, has also 'equalized the discrepancies between codebase, server and the restnof the stale branches on the repo' . i was doing my other work on my branch so no fucks given. This is where i should have given some fucks.
Anyways, today. The day starts every day with merging the master branch into your working branh because you need the latest working codebase, right?
Wrong!
This fucking dipshit smug b-tard has done a mindless merge of the entire codebase, effectively removing ALL validated working code for provisioning servers. Control blocks, lookup functions, lambda's... Basically everything he did not understand.
At the same time the project is already way beyond the allotted budget in pkney and time, so there is a huge pressure to have a working 'production' environment TODAY!
THIS MOTHERFUCKING B-TARD JUST MADE THAT IMPOSSIBLE.
i'm loving this assignment, i'm loving the PM, the collegues, the environment, the location... everything. All but this fuckibg b-tard that somehow got his position by sucking dick or licking ass or both...
I wanna get out asap.
Oh... While typing this and arriving at the room of the office... It is locked, i have no key.
Fucking asshole!1 -
This one time last year a colleague found out that some data went missing and suggested to recover the data from a backup. When trying to create a new database instance in the Google Cloud Platform (if everything works it's amazing!) it failed.
Not knowing why this happened, I tried to revert that backup to the production database, after creating a backup using the GCP. Needless to say that failed as well, resulting in a corrupted database instance where I couldn't access the created backups anymore.
This all went at around 10pm and the only users of our product are currently in the same timezone and use it from around 7.30AM until 6PM so no one besides our team knew the server was down.
After a long night chatting Google's support team the database was successfully recovered and the only harm done was sleep depravation for me and a colleague.
Apparently there was a bug in the GCP. It was resolved in two hours and the last time a breaking bug was in that piece was more than seventy days earlier.
I did at least learn to create local backups as well, instead of relying on the tools of the same product...
Best: the moment I saw the corrupted database spin up again and not losing my job because of it. -
Last weekend I was working on a small project for a friend of mine: a dockerized webapp, plus API backend and DB. I had some problems with the installation on the vps and had to try out different images and never really did a complete setup of my usual dotfiles. Got it running on an Ubuntu distro. Everything great.
It was the first release so I still had to check that every configuration worked ok, like letsencrypt companion container, the reverse proxy and all that stuff, so I decided to clone the whole project on the server tho make the changes there and then commit them from there.
Docker compose, 10 lines of code, change the hosts and password. Boom everything working. Great... Except for the images in the webapp.
WTF? Check the repo, here they are, all ok. I try different build tactics. Nothing. Even building the app on another docker always the same. Checked browser cache, all the correct ports are open. I even though that maybe react was still using some weird websocket I didn't know, but no.
Damn, I spent 5 hours checking why the f*** the server wouldn't make it out.
Then, finally, the realization...
I didn't install the f******* git-lfs plugin and all I was working with were stupid symbolics links! Webpack never even throw an error for any of the stupid images and the browser would only show a corrupted image, when decoding the base64 string.
Literally the solution took 5 minutes.
F*** changes on production, now I do everything on a fully automated CI. -
A while back I was looking for a new job and was given an interview by one company who shall remain nameless. Before the interview, they asked me look through their current site, nothing unusual there, so I started browsing. Then I received an email with all the details I needed to access their production server. Apparently they wanted me to look through the code, unusual but I did so.
First thing all the passwords, including those belonging to members of the public were stored in plain text and many were still the default passwords which were based on the Id so were sequential.
I highlighted these issues at the interview and they then asked me to do a test, not the usual test though, they asked me to add some charts to their prod site. Needless to say that didn’t happen and I got another job elsewhere.1 -
I am creating a PWA using quasar, which uses vue.js at core.
Now the router is working fine. In production code, The address url is updating dynamically upon clicking route-links. Say, there are 4 routes, namely /user , /friends, /human, /robots. But when I visit one of those route paths using web address or say I reload the application/web page, when the route path is /robot or any other path, server reply with cannot GET /[route path]. I know that I had not set up the route handler at server, but I am not expecting this behavior. I dont want to make request to server like this.
While in dev mode, everything is working fine and as expected. when I visit /robot or any other route path , instead of contacting the server, it render the component that was bound to handle that route path34 -
Got a call about production was going to fail. They thought it's the application server.
I'm the end it was bogus file mods which were scrambled by the backup tool.
Why we didn't find out earlier? Because the java application was coded like this:
-------
String content;
Try {
File bla = new File
content = ... Read operation
} catch (IoException | SecurityEx | RuntimeEx ex)
// nothing we can do here
}
doWork(content);
---------
Why the fuck do we have code reviews? Why not just log or throw a Runtime Exception? Argh... I thought it would be better in enterprise applications. Perhaps I should tell them to not just use pmd, also spotbugs and sonarqube. But the department for the build tools does not have enough employees. Dang.
Anyway. Earned some money for that.
Now it's 2018 and I still get money for the same kind of bugs as 2008.3 -
Today at work, I had to do a dry run of our new production environment config for our VM server.
So I setup ESXi in a vm in my workstation. Installed it it, no problem. Setup some VMs, still going good. Then my supervisor came and said I have to make some tweaks and use vCenter. I thought: meh, that came late but ok. Download the vCenter installer from our internal CDN and ran it. Sorry general config, blah blah blah. "Setup with embedded or external platform service controller?" -"Embedded" - "minimal requirements: 11GB ram, 250GB disk storage, 2 CPU cores". Well... Fuck me. My workstation specs: 8 GB RAM, 128 GB SSD, 4 cores.
What the bloody fucking hell does this stuff need 250 GB disk space for?!
Well at least I've got a permanent upgrade for my workstation.1 -
Disclaimer: Technically it's not "our" stack, but we have to use it so....
A webapp we built runs inside the company's network we built it for. Their IT are windows lovers, so everything has to run on Windows servers, even the tablets which are used to access said web app need to have windows.
Their company network isn't accessable from the outside world, so we have access via VPN to get into their network. But this isn't enough to access that shitty windows server our software runs on. After that VPN, you have to connect to a different VPN to which you can only connect to while you're inside the company's network. Then you have access to two servers, one the application is running on and one, well to see if you're changes were deployed correctly because the production server doesn't have a browser on it other than shitty internet explorer 8.
The only way to connect to the server is using RDP. Not even samba or so. To deploy the changes we made to our app, you need to copy paste the files from your local machine to the server. And don't get me started on running mssql migration with the shitty mssql console 😤😤
Why would anyone who isn't a complete idiot use Windows for servers or mssql in the first place????2 -
First let me start this rant by saying: Don't use SharePoint lists as your primary data store if you can avoid it. You're gonna have a bad time.
My coworkers and I work on a system where we need to pull tons of data down from a SharePoint site and run various algorithms and operations on it. Generate reports, that sort of thing. This is all done in the browser using a Typescript React SPFX webpart. Basically using SharePoint as a DB/DAL.
Because of the sheer amount of data we end up pulling down (our system in production is the single source of truth for one of the largest companies in Canada, and they're currently building a pipeline as we speak), in order to maintain a reasonable speed while using it, we have some pretty intense caching logic implemented, logic that ensures we get new items when new items are detected, and merges changes to already exisiting objects. It's pretty brilliant, and that's before we even consider the custom paging that my coworker implemented in order to get around the IndexedDB max size of 100MB.
Well that's all well and good, and works great in production, but it is a horror to work with. Because EVERYTHING we touch on the server is cached locally, it can be IMPOSSIBLE to detect data anomalies, be they local or server side -.- You don't know how many hours I have completely WASTED fixing a "bug" that didn't really exist... Just incorrect data in the cache12 -
How the fuck does someone not check from Middleware server to database? Going to production and we find that was never checked.... It's 1130pm and now I have to wake people up on a Friday night...
-
Rules and policies are just for discussions and arguments. When you really have a problem on production, all you need a solution without any law.
You are allowed to execute Alter, Restart Server, Deploy some hacks and many more :D -
Gah, I just received this Ubuntu 18.04 VM with 8 cores and 8 gigs of ram, and since it'll be a production server both serving public and "private" networks (yes, shout at me, but projects won't be about hosting sensitive information, I wouldn't put all that on one server), and I'm struggling between my options.
Docker, or not docker?
The server's main use is to host our growing blog and install Varnish, which will hog some ram after a while. I use Laradock for my dev projets, it's really easy to develop with it, but I am unsure if it fits a production environment with performance, security and traffic load in mind :(
I read Docker has stability issues (in 2016-2017), and can bring the machine down with it, I don't know if I should just install the software (nginx, apache, percona/mysql/maria) without "containerizing" it and go for it
I'm lost xD7 -
Only when the latest feature is implemented, the last bugfix and the last workaround are found, the last unit test is written, the latest CI/CD pipeline done, the customer guy does manual testing and acceptance tests on the staging server and let's them pass and a few days later it's pushed to production...
You will be reminded (again) that shitty customers do exist! A customer is the least capable person to tell you what the customer actually wants and is also the least trustworthy person to test the features he requested...
Holy fuck come on! Just test that shit on the staging Server! One Look could have already shown you that that's Not what you expected!
I checked the logs after that and yup you guessed correctly... The said endpoints weren't even used on staging, only on production...1 -
That feeling when a new feature works on a local build, works on the development server, and works on the QA/UAT server, and then still breaks production when deployed.2
-
When the client decides that we wants to change the production server and does it, and the DB params are still the old ones, and no one can work, and shit happens...1
-
So I currently work at my first job and have for 2 years now. First project I had was to redesign a user info set up page. Didn't know any of the languages so kinda had to just wing it. Anyway finally committed my code and tested on dev server. Then code pushed to production and tested there. Then I saw a message from one of the top devs saying nobody could login. I replied saying that I was able to. Well, I actually ended up making it to where no one could log in except me. I learned real quick to never fuck up like that again. Surprised I wasn't fired on the spot.1
-
A dev decided to overwrite the master branch with his code saying its better. That it fixes the major bugs that all of us couldn't solve.
Against my better judgement of firing him, I decided to test it.
Firing up the testing site, we made test databases to use and we went to house.
In the middle of testing, I noticed the test DBs weren't being changed. While everyone was still testing, I looked at the code. It wasn't made to test on any databases, it was specifically designed for the actual production server.
However the damage was done. In a secret dashboard in the code, someone sent instructions to drop the tables, effectively ruining the production server.
We had the dev go to an offline backup site that only went online every 10 minutes a day to make new backups. So we shut down the production server, setup a maintenance page. I get my ass chewed out again, and we were sitting ducks.
I don't think the dev had enough punishment, so I grabbed his laptop and made a full backup of his data, and locked the SSD in a safe.
I downloaded a Windows 98 and put it on a flash drive. And installed it all on his SSD. The dev is now a proud (pirate) owner of Windows 98.
He came back and started balling on his desk. We all looked at him with a pity, but he deserved it.
I'll give him the drive on Monday.
Do you think he learned his lesson?7 -
Currently debugging a project that was written over 4 years ago...
At first all was well in the world, besides the ever present issue off our goddamn legacy framework. This framework was written 7 years ago on top of an existing open source one, because the existing one was 'lacking some features' & 'did not feel right'.
Now those might be perfectly fine reasons to write a layer on top of a framework, but please, for all future devs sanities, write fucking documentation and maintain it if you're going to use said framework in all major projects!!
Anyhow back to the situation at hand, I'm getting familiar with the project, sighing at the use of our stupid legacy framework, attempting to recreate the reported bugs...
Turns out I can't, well I get other bugs & errors, but not the reported ones. I go to the production server, where I suddenly do can reproduce them...
Already thinking, fuck my life, and scared for the results... I try a 'git status' on the production server....
And yep, there it is, lo and behold, fucking changes on production, that are not in git, fuck you previous dev who worked on this and your stupid lazy ass modifcations on production!
Bleh, already feeling royally pissed, there's only 1 thing I can do, push changes back to git in a seperate branch, and pray I can merge them back in master on my dev environment without to much issues...
Only I first have to get our sysadmi. to allow pushing from a production server back to our git server...
Sigh, going to put on my headphones, retreat to my me space and try to sort out this shitpile now... -
for the 3rd time ive tried introducing some version control on a project that really needs it because it has multiple people working on it.
And because the last time my efforts got shut down because in practice people thought it was too much of a hassle to develop locally rather than on the shared development server directly, I made a feature that would let people checkout branches on said server...
Apparently the action of; saving > committing > pushing to your feature branch > merge after aproval, is still too much for people to comprehend; "I think this is too convoluted can't we just keep pushing to the production server to check our work and then commit and push to the master branch"
So I just got pissed and said fuck it, no more git then, I'm not even going to put any effort into changing tooling here anymore, and this is a massive project where we have to manually remove code that isnt ready yet from the staging environment.
Are the people I'm working with just this stupid or am I really overengineering this solution because I think 4 people should not be working on the same file at the same time without any form of version control and just direct upload to FTP.
(and yes, I know I should leave this job already, but social anxiety of starting at a new company is a big obstacle for me)3 -
Boss: this can't ever be the production version of the server
Emp: actually, it can be
Boss: that's what I mean, this will literally be the production version -
Java server faces (primefaces) needs you to define shit like "DATETIMECONVERTER_DEFAULT_TIMEZONE_IS_SYSTEM_TIMEZONE" or that stupid piece just assumes that every date time should be loaded as UTC timezone.
Production standard my ass nobody wants to use such verbose, outdated and logically incomprehensible piece of shit, not even at gunpoint -
so I'm the new guy now, my new team write complicated, deep-for-no-reason IFs instead of a switch, gave me a shitload of resources to get up to date with their standards, insisted to every time make sure my code has been tested, then the first deployment I see THEM do breaks production, because a major fucking app had no tests whatsoever, also half of the team has 30+ years of experience in backend, laughs about TS on the server (which is actually fair) and I'm the frontend guy
challenge accepted3 -
We're remediating tls issues on production servers. gotta be pic compliant. It's been an hour and a half for one server and were not even close to done... we have at least 5 more to go for this particular app... my organization controls over 300... the company has thousands... for the love of god save me.5
-
My beautifull roomie asked me make a simple php page for her company . I did not sleep 3 days. The day it was released on production, it fucking didn't work. The reason: "the production Administrator didn't install the php server. I get no paid, my roomie is kinda mad at me.13
-
Have you ever considered switching to IT support/help desk?
I mean, sometimes I try to analyze my own situation from a 3rd person perspective and I realize I could have a pretty much stressless job with still enough money to live a normal life.
I have a BSc and MSc(soon to have) in CS, with focus on AI/ML. I've always been a geek with a problem solving attitude, that's why I got into computers in the first place. And now I'm pondering if I should just try an IT Support position, it's the kind of things I used to do as a teenager when a classmate had a network/computer problem, it doesn't even feel like a job to me. I could call it a day, get home at 5/6pm, and spend time on my personal projects (software, infosec) with a fresh mind, going to bed (and sleep) knowing that the next day would be a nice one. No clients wanting a new feature that you gotta implement and push on a production server friday afternoon because your ceo(who is also a pseudo proj manager) just said:"Yes, we can", while you watch the technical debt rising like amazon's stocks.
Maybe this is just the burnout talking, I don't know. Maybe I should just try being a software engineer outside of Uni in the first place, and only then start pondering.
Maybe a sysadmin position...
Have a nice day12 -
So a third-party service that I implemented is going to production and me and the PO were testing that yesterday, didn't see any orders coming in the service backend.. so we send a mail to them.
This morning they respond with saying that they can't have both the test server running and the production server...
What the hell is this... :/3 -
worst mistake was probably introducing an infinite loop in the category tree for e-commerce site...
in the vein of true agile and considering MVPs and what not we had not yet automated everything. the client would send category updates as a spreadsheet and i had a script to generate the sql and jam it into the site. having run the script several times in the past I thought I'd just throw the update into production and call it a weekend...
it wasn't long before I started fielding calls that the site was unstable. no page would load and the server kept crashing under trivial load. well an entire frantic weekend later I discovered the category load hit an edge case I hadn't considered and I had introduced an infinite loop in the navigation of the site.
i'd like to say I learned my lesson and never just threw changes into production again, but what can I say - I like living on the edge. I did however learn that loop detection can be a valuable thibg -
If your code is giving HTTP 500 error on a production server, go kill yourself, until you are having a development environment on the production server. In that case, kill your manager! 💢
-
Me: Code checked in, CI and tests passed, deployment kicked off. Huh maybe I won't have to stay late after all!
Production Web Server:
-
Modified stuff on production server without checking documentation, because I was cocky and tought that I remembered everything. The worst thing is, that right after that I took a lunch break and only realised what have I done after that. For an hour or so anyone who opened our app experienced an instant crash...
-
How reliable or better freebsd is? I was thinking to use it in production server instead of ubuntu 16 LTS. I've heard it has pretty good networking stack and whatsapp uses it in their prod machines.6
-
I have 2 server that run in production that using SQL Server Developer Edition and SQL Server Standard Edition.This was setup by shit people before they all resigned from the company.
I need to upgrade both server to Enterprise Edition.It give me a real pain since both server is on production side now.
Is it possible to upgrade it without any error or long downtime?3 -
TL;DR As time goes by, I'm feel deeply in love with linux. An infatuation? :D
Before, I really dont mind how the file system works, permission setup, library installation, etc. as long I finished my project (before like 90% of the time I copy paste cmds). But now, after many hair pulling while debugging times, crying while rolling on the floor moments, and painful production deployments (wtf! it's working on my machine/dev server rants), it helps me clearly realized how amazing it is. I might be relatively new with the OS compare to others so maybe what I feel like now is like having a crush on someone in a bus :). But still, I just wanted to say thank you to all who are giving their time in developing/improving linux distros - you are heroes!
I'm hoping that I can contribute something soon :)
senti_mode off1 -
Do you use rust for production apps? if yes:
1. which framework do you use to build the server?
2. how do you work with mongodb?
3. how do you handle authorizations?
4. any beginner friendly project idea?1 -
So I was writing SaltStack state for syslog management and I had a simple config file in place to be deployed on a test server. I was writing the command to run the state for the test server, and the only thing that was left was to type the hostname of the server (instead of wildcard) when someone interrupted me. After I got back to this terminal I instinctively pressed return sending test configuration to over 80 production servers. Nice one...
-
Today our PM planned to deploy in production an e-commerce based on PrestaShop.
A colleague of mine mamaged to implement everything that was necessary, and I made a small script to add random sales on random products every sunday.
We tested it several times in our environment, on multiple machines, and everything was working fine.
BUT
Today we launched the script on production server, and we was a little mistake.
"A bug? Say no more pal, I'll fix it!".
Fixed, tested on local environment, deployed and.... The first steps weren't working.
"Fatal error".
That's what I got. No exceptions, no error messages, no references.. Just "fatal error".
We spent two hours looking for the problem, thinking it was a server error that was just outputting that shitty message.
And you know what? Some fucking fat cocksucker son of a bitch thought it was an excellent idea to stop the code execution with a simple and very helpful "fatal error".
"oh, wait, there is an error here, let me print die(" fatal error"), ao the other developer will be able to find what's going on", he thought.
FUCK YOU MORON.
TL;DR: Avoid French software, they are a bounch of asshole (except some goos guy..) -
I had a client with an ongoing project. Everything was going fine until her boy-asshole-friend talked to me by phone... He was so ignorant.
Don't get me wrong. I'm not talking about the ignorant who doesn't know anything. I'm talking about the ignorant who doesn't know a shit but he is talking about it and refuses to get a professional advice. He told me explicitly: "Don't use test server for testing your project. Do it directly on production"
Unnecessary to say that my client "suspended" the project.1 -
Testing new server deployment in test env all works, then production it all breaks down. Network didn't allowed the right traffic. Took me whole week to find that out. Until some networking engineer said, you know there is a firewall between those networks?
-
I once executed a rm -rf * on a production server. What was your most fckd up or fireable instance at job?1
-
Just heard someone saying it's bad security practise to have composer and git on production server for deployments.... did I miss the memo?1
-
Sure boss, we don't need staging. Let's just copy some tables from our customer's server to our testing machine, overwrite our data with theirs and start testing "simulating" their environment. It's not that we need to test for our production, right?
-
I recoded a REST endpoint that transfers large amounts of data from our db using a streaming response so it doesn't crash the server...
Pretty easy... Mostly just needed someone that knew wtf it was or has a bit of curiosity and asks questions... rather than just keep on doing what everyone else is doing...
Who hasn't seen logs updating in near real time in TeamCity, Jenkins... for the last 5yrs+... No one else ever wondered how it's done?
So yes solving a production issue with old technology and being called a genius... I guess is pretty satisfying? -
From the guy that practices bash in the production server, here's the same guy who also practices SQL queries in the production's PostgreSQL!
I swear these happen by accident. I'm having to do some data corruption control by some bug, but I forget to close the panel when I'm finished. Then I go on with my tasks and I think it's my own computer I'm writing these commands to.3 -
We have a CRM running on an EC2 instance. We need to clone it so we can test a tool on the replica. We tried cloning it directly, sharing the AMI and creating a new instance through it but it always redirects changes to the original production server. The database is on the instance only and static files are stored in S3. Can someone guide me or share some resourses on how to do this.6
-
Separation of duties.
I work in a fairly large IT department for a Healthcare company and for security reasons always having to involve application support or other teams even during development phase can be very aggravating when I have to ask for simple things like server log files. And the process to get to deploy in production is paved with bureaucracy and paperwork and emails that have little to do with anything other than just say, I approve, yet we are supposed to be trying to implement agile. -
How do I deal with this;
Edge case hiccup on production, no errors in the available logs(very shallow logging), no access to the production server, issue unreproducable on staging and a manager that want me to fix it AFTER I already said that im kind of sailing blind and can't do much without logs or access, and already looked at it with another dev who also has no idea what is going on3 -
Deploys to Production.
Runtime error.
Open Development server and run in Production setting.
Still runtime error.
Fixes Error.
Error fixed on development.
while (hoursWasted < 3) {
Deploy.
Not working on Prod.
Try other fix.
Still not working, but works perfectly in dev machine.
What the fuck
}
Rage
Go take a walk
Realized I might have deployed to the wrong server
Glanced at deployment path
Realized it's at the wrong server
Reconfigure and Deploy
It works.
Fuck.1 -
Struggling to optimize and to scale the infrastructure of our production environement dealing with people who don't bother themselves to write scalable code.
-
When you have a customer that is a pain and you have to do a new contract since months but they are no replying but at same time there is a bug in a plugin they are using.
They are not updating their plugins in production but only after a test in staging.
In production there aren't write permission from web server side, so only they have access.
And the plugin has a 0-day. -
Does anyone use file comparison software (Ex. Beyond Compare) on production server to deploy code?7
-
I kinda wonder why so few server frameworks have actually implemented the FastCGI spec, instead of running their own weaker HTTP server that needs to be put behind something like nginx for production anyways.
-
In my initial days as a web developer, i was assigned a task, to implement a cart share functionality in an e commerce company.
I made the functionality and tested on my system.
Result: working good.
Pushed it to beta testing environment.
Resilt: working good.
Pushed to pre production environment.
Result: working good.
Pushed to live site.
Result: 😀 Error in live site..
So a call comes to me from my team lead..
Asks what was the issue...
Me: i dont know either.
....
After 3-4 hrs:
I found the reason.
My system, beta test env, pre prod env are all having latest php version (5.6 i guess)
But the live server had old version of php.
Me: laughed like anything.
I didn't know that these things would matter in such a great level.
Moral of the story:
Be one with the force (server in this case)1 -
One nightmarish project that was doomed from the beginning, had me as the sole developer. I could hardly sleep when we began testing on a separate test system, but with (nearly) all the config stored in shared memory and copied from the production system, I dreaded, half awake, that the production server data base connection was still configured in the test system and that it was shooting all it's test data repeatedly to prod.
Finally drove to company in middle of the night at 4 o'clock. Checked everything was OK, tried to sleep 3 hours before the start of the work day.
This system also had the most hideous memory corruption in some shared memory that was used across several processes and should have been thoroughly protected by a mutex, but somehow, sometimes this crucial map, that was used to speed up the access to all the customer data just contained garbage.
Still haunts me to that day. (Like xkcd's unresolved tension of a non-matching parenthesis - an unresolved bug. -
When you test on production server
"Your system folder path does not appear to be set correctly. Please open the following file and correct this: index.php"1 -
this afternoon, we got email from our pentester. He said that he got some security vulnerability in our project. He found .git/ folder in project directory in production server. He considered it as security vulnerability because user can see all git branch on remote repo. He recommend us to remove that folder but the problem is, we using CI/CD so we need that .git/ folder. My question is it bad practice to use git on production server?10
-
To this day, I'm constantly surprised how developers who are more experienced and senior than me, DO NOT use try-catch wraps around their code before pushing it onto the production server.
Developers like these have such a high level of confidence that scares the crap outta me.9 -
MRW I deploy to production server and forget to add a server domain in "OAuth redirect domains" in Firebase.
Before that I was debugging for 6 hours without success. 1
1






















































































































































































































































Top Tags
Weekly Rant
View